Author: Denis Avetisyan
Researchers have developed a novel framework that combines neural reasoning with deterministic validation to create more accurate and reliable autonomous simulations of complex fluid flows.
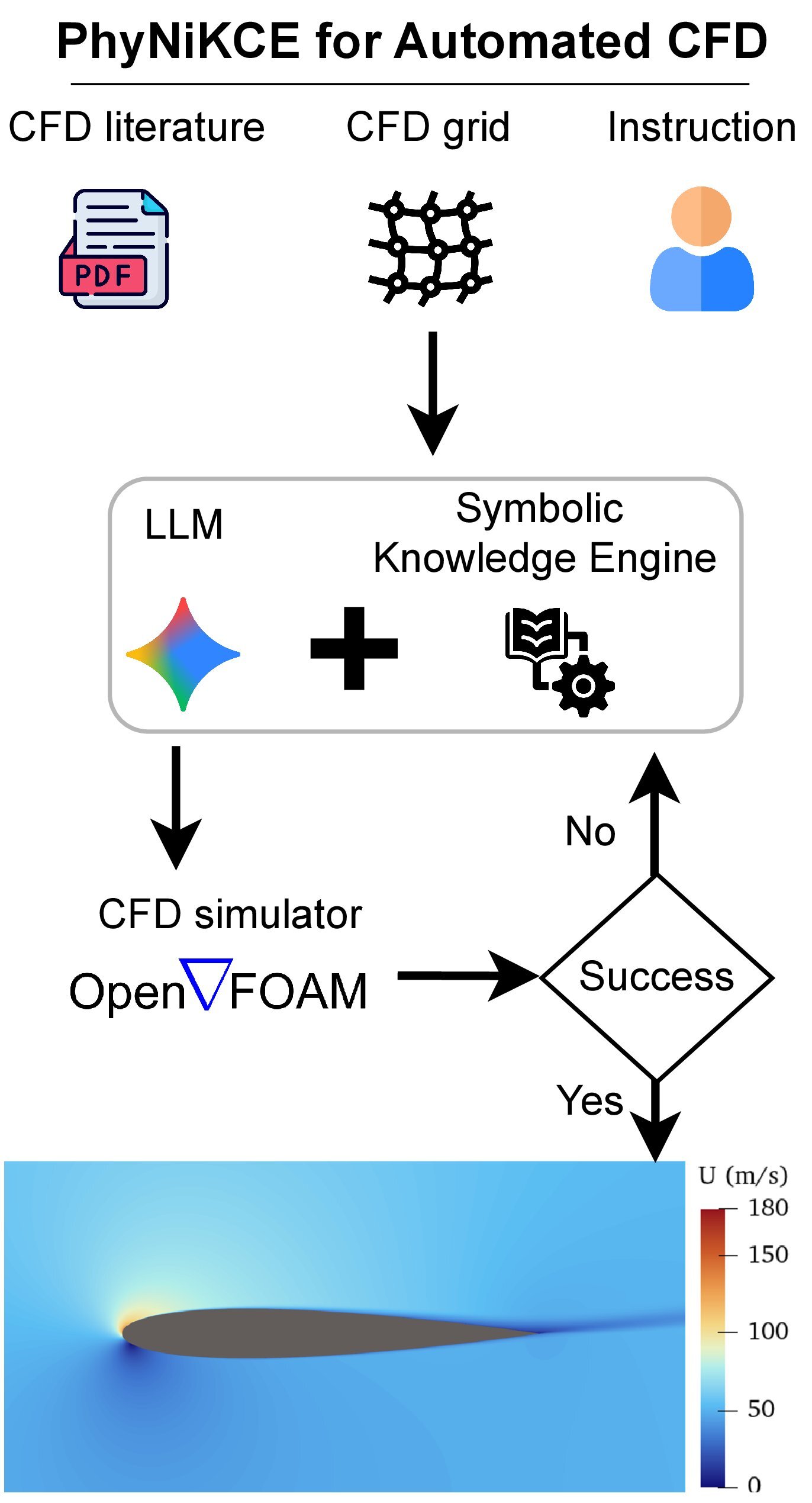
PhyNiKCE decouples neural planning from physical consistency checks, improving the reliability of AI-driven Computational Fluid Dynamics simulations.
Despite advances in artificial intelligence, reliably automating complex physics-based simulations remains a challenge due to the inherent difficulty of aligning linguistic plausibility with physical law. This work introduces PhyNiKCE: A Neurosymbolic Agentic Framework for Autonomous Computational Fluid Dynamics, which addresses this limitation by decoupling neural planning from deterministic, knowledge-driven validation of simulation parameters. Through a symbolic knowledge engine enforcing constraints on solver selection and boundary conditions, PhyNiKCE achieves a 96% relative improvement over state-of-the-art baselines in autonomous CFD tasks, while simultaneously reducing LLM token consumption. Could this neurosymbolic approach offer a pathway towards truly trustworthy and scalable AI for broader industrial automation and scientific discovery?
The Erosion of Validity: LLMs and the Limits of Pattern Recognition
Large Language Models are increasingly explored for their potential to revolutionize Computational Fluid Dynamics by automating tasks traditionally requiring significant expert time and resources. However, a fundamental challenge lies in ensuring the physical validity of simulations generated by these models. While LLMs excel at pattern recognition and can generate plausible outputs based on training data, they often struggle to adhere to the underlying laws of physics, particularly in complex scenarios involving turbulence, multiphase flows, or intricate geometries. This isn’t a matter of simple calculation errors, but rather a disconnect between the model’s ability to understand the description of a fluid dynamics problem and its capacity to guarantee a physically realistic solution – leading to simulations that may appear reasonable but ultimately violate conservation laws or produce unstable results. Consequently, significant research is focused on developing methods to ground LLM-driven CFD in established physical principles and validation techniques.
While Retrieval-Augmented Generation (RAG) has emerged as a valuable technique for grounding Large Language Models (LLMs) in factual data and reducing instances of nonsensical outputs in Computational Fluid Dynamics (CFD), its effectiveness reaches a limit when addressing intricate physical constraints. Current RAG systems primarily focus on retrieving relevant information based on semantic similarity, meaning they excel at finding documents about a problem but struggle to guarantee the retrieved knowledge translates into a physically plausible simulation. This is because nuanced physical laws and boundary conditions often aren’t explicitly stated in text; instead, they’re implicitly understood within the mathematical framework of fluid dynamics. Consequently, RAG approaches can plateau, delivering informationally correct but physically invalid results – the LLM understands what needs to be done but lacks the capacity to ensure how it’s done adheres to the governing physics, hindering its ability to create truly reliable CFD solutions.
A fundamental challenge in applying Large Language Models (LLMs) to Computational Fluid Dynamics (CFD) stems from a disconnect between semantic understanding and physical validity. While LLMs excel at processing and interpreting the description of a fluid dynamics problem – recognizing terms like ‘turbulent flow’ or ‘boundary layer’ – this linguistic comprehension doesn’t inherently guarantee a physically realistic simulation. The model can articulate the principles involved, even suggest appropriate equations, without internally verifying if the resulting numerical solution adheres to fundamental laws of physics, such as conservation of mass or energy. This ‘semantic-physical disconnect’ manifests as simulations that sound correct but produce non-physical results – a critical limitation that necessitates innovative approaches to ground LLM-driven CFD in demonstrable physical accuracy, going beyond simple text-based reasoning.
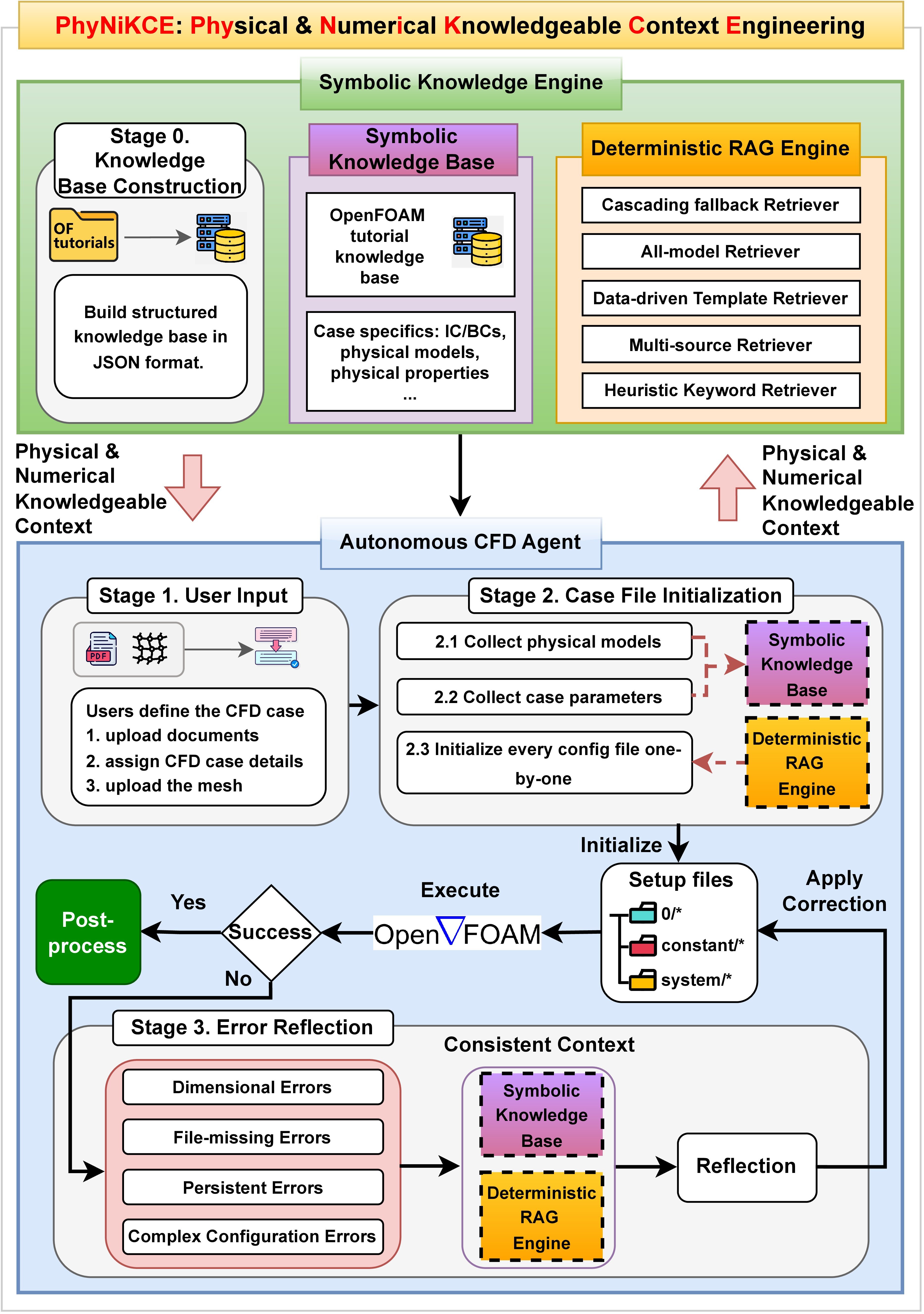
Decoupling the Ideal from the Real: PhyNiKCE’s Architecture
PhyNiKCE tackles the challenge of bridging the gap between the semantic understanding of large language models (LLMs) and the physical requirements of robotic execution by separating the planning and validation processes. Traditional approaches often integrate these steps, leading to plans that, while logically sound, may be physically unrealistic or impossible to execute. PhyNiKCE implements a neurosymbolic framework where the LLM generates high-level plans based on semantic reasoning, and a separate symbolic validation system rigorously checks these plans against the physics engine and simulation constraints. This decoupling allows the LLM to focus on goal-oriented reasoning without being burdened by low-level physical details, while the symbolic validator ensures the resulting actions are feasible and safe for execution in the simulated or real world.
The Symbolic Knowledge Engine serves as an intermediary component within PhyNiKCE, mediating between the Large Language Model (LLM) planner and the simulation solver. This engine operates deterministically, receiving proposed configurations from the LLM and verifying their validity before they are passed to the simulation. It functions as a ‘guardrail’ by enforcing pre-defined rules and constraints, preventing the simulation solver from receiving physically implausible or invalid states. This decoupling allows the LLM to focus on high-level planning without needing to directly encode physical laws, and ensures the simulation remains stable and predictable by filtering out infeasible actions.
The Symbolic Knowledge Engine employs a Constraint Satisfaction Problem (CSP) formulation to validate proposed plans by representing the environment’s physical laws and simulation constraints as a set of variables, domains, and constraints. Each variable corresponds to a relevant aspect of the configuration – such as object positions or joint angles – with its domain defining permissible values. Constraints are then defined as logical relationships between these variables, ensuring that any proposed configuration satisfies physical requirements like collision avoidance, stability, and joint limits. The CSP solver then determines if a valid assignment of values to the variables exists, effectively verifying the feasibility of the planned configuration before execution within the simulation environment. This deterministic validation step ensures adherence to simulation rules and prevents physically implausible actions.
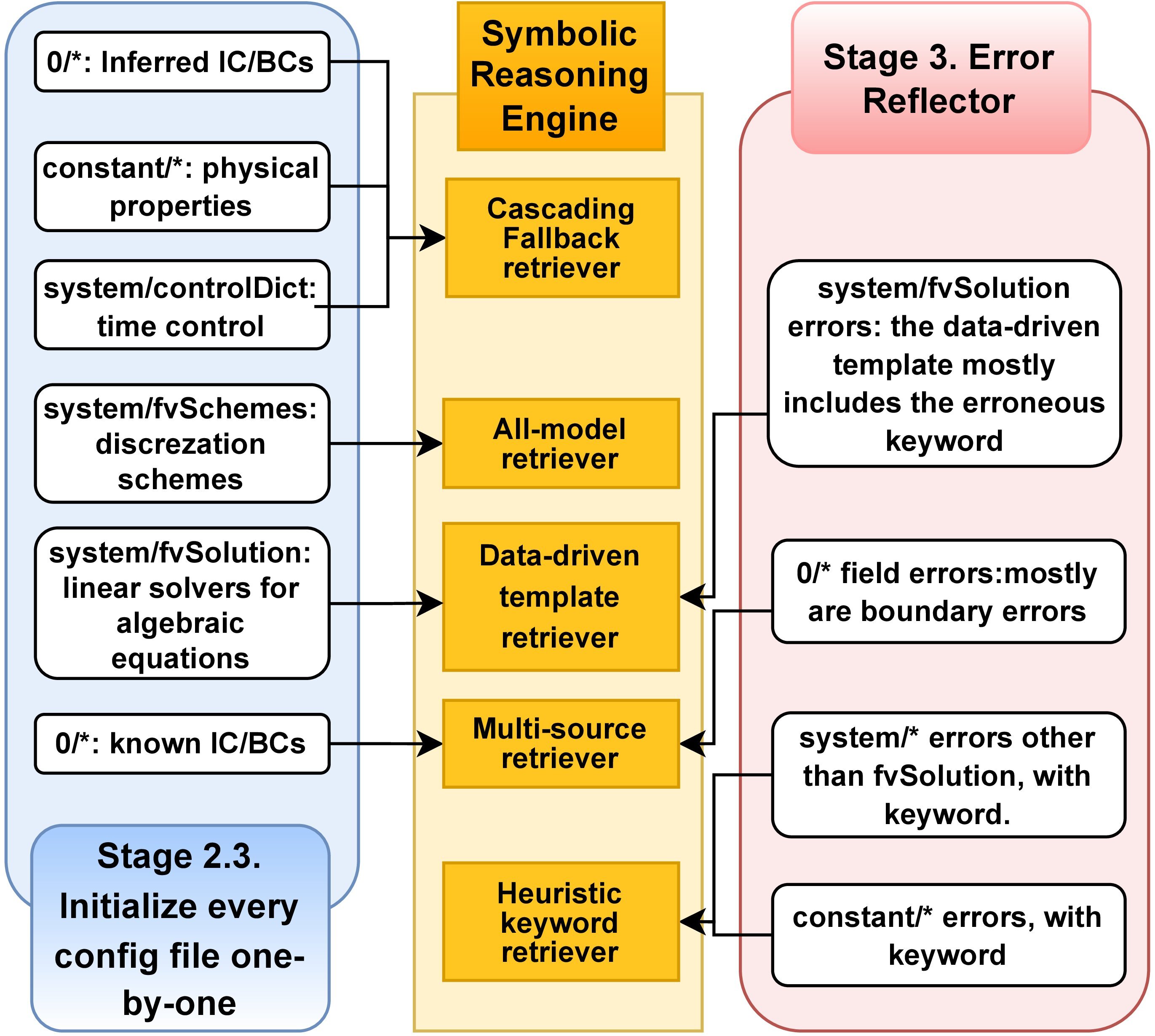
From Probability to Certainty: Deterministic Retrieval in PhyNiKCE
PhyNiKCE utilizes a Deterministic Retrieval-Augmented Generation (RAG) engine as an alternative to conventional vector-based RAG systems. Standard vector RAG relies on semantic similarity, which can be susceptible to “context poisoning” – the inclusion of misleading or incorrect information that influences the generated output. In contrast, PhyNiKCE’s deterministic engine employs structured retrieval strategies, prioritizing predictable and controlled access to relevant data. This approach moves away from probabilistic similarity searches toward defined pathways and constraints, ensuring that the retrieved context is consistently valid and directly applicable to the task at hand, thereby enhancing the reliability of the generated configurations.
PhyNiKCE’s Deterministic RAG Engine utilizes Specialized Retrievers to address limitations of standard vector-based RAG systems. These retrievers are not general-purpose; instead, each is engineered for a defined retrieval task and incorporates mechanisms to enforce physical constraints on the retrieved data. The Cascading Fallback Retriever, for example, sequentially queries multiple knowledge sources, prioritizing those with higher confidence or relevance, and only proceeding to subsequent sources if the primary fails to meet criteria. The Multi-Source Retriever aggregates information from several sources simultaneously, applying filtering and validation rules to ensure the combined result adheres to defined physical parameters and avoids inconsistencies. This targeted approach minimizes the inclusion of invalid or irrelevant data in the final retrieved context.
PhyNiKCE’s configuration retrieval process is designed to mitigate the generation of invalid simulation inputs by implementing strict controls over data sourcing and selection. This is achieved through deterministic retrieval, prioritizing known-valid configuration components and explicitly excluding potentially problematic or irrelevant data. By enforcing these constraints, the system significantly reduces the incidence of errors that could lead to unstable or inaccurate simulations, ultimately increasing the reliability and fidelity of the resulting outputs. The deterministic approach contrasts with probabilistic methods where irrelevant or incorrect context can be included, introducing unpredictability and the potential for simulation failure.
Beyond Resilience: PhyNiKCE and the Future of Autonomous Simulation
PhyNiKCE represents a significant advancement in autonomous scientific problem-solving, demonstrably outperforming previous agents like ChatCFD. A key innovation lies in its ability to overcome the limitations of ‘Template Rigidity’ – the tendency of earlier systems to rely heavily on pre-defined solution structures. This new framework achieves more robust and adaptable solutions by dynamically constructing and refining its approach to complex simulations. Unlike its predecessors, PhyNiKCE doesn’t simply fill in the blanks of a template; it actively learns and adjusts its methodology, allowing it to tackle a wider range of problems with greater reliability and ultimately delivering more accurate and dependable results.
PhyNiKCE introduces a novel capacity for autonomous error resolution, fundamentally enhancing the reliability of complex simulations. The framework doesn’t simply halt upon encountering runtime errors; instead, it actively reflects on the problem, identifies the source, and implements corrective measures without external intervention. This process, termed Error Reflection, was demonstrated to be remarkably efficient, requiring 59% fewer rounds compared to conventional approaches. By proactively addressing instability during simulation, PhyNiKCE achieves more robust and dependable results, minimizing the need for manual debugging and accelerating the path to accurate scientific discovery. This self-correcting mechanism is crucial for tackling challenging physics-based problems where errors are common and iterative refinement is essential.
PhyNiKCE distinguishes itself through a novel approach to simulation validation, significantly boosting both the reliability and transparency of its results. By integrating symbolic validation, the framework doesn’t merely produce solutions, but provides a clear, traceable pathway to those solutions, fostering increased trust in autonomous computational fluid dynamics (CFD) simulations. This methodology directly translates into quantifiable improvements; accuracy surged from 26% to 51%, representing a 96% relative gain. Importantly, this enhanced performance is achieved with greater efficiency, as knowledge-driven initialization led to a 17% reduction in large language model (LLM) token consumption, streamlining the process and minimizing computational cost.
![Computational fluid dynamics validation tests were performed using geometries featuring grids and various boundary types, including a NACA 0012 airfoil [30] and a nozzle [41].](https://arxiv.org/html/2602.11666v1/figures/Fig_5_2_geometries.jpeg)
PhyNiKCE’s architecture embodies a recognition that all systems, even those built on the latest neurosymbolic frameworks, are subject to the inevitable decay of accuracy over time. The framework’s decoupling of neural planning from deterministic validation isn’t merely a technical innovation; it’s an acknowledgement that solutions are, by nature, temporary. As Paul Erdős once stated, “A mathematician knows a lot of things, but not enough.” This echoes PhyNiKCE’s approach: no single model possesses complete knowledge of fluid dynamics, necessitating a system where planning and verification operate as separate, evolving components. Only through such deliberate, slow change-allowing validation to correct the inherent imperfections of planning-can resilience be preserved against the persistent challenge of semantic-physical disconnect.
The Long Flow
PhyNiKCE represents a necessary, if incremental, deceleration in the rush to imbue large language models with the authority of physics. The framework’s decoupling of neural planning from deterministic validation isn’t a solution, but a carefully considered admission: current systems still fundamentally interpret reality, rather than embody it. Every bug in an autonomous simulation is a moment of truth in the timeline, a stark reminder that semantic understanding does not guarantee physical consistency. The elegance lies in acknowledging this fracture, not attempting to paper over it with larger models or more complex prompting.
The true challenge isn’t simply scaling accuracy, but managing the inevitable accumulation of technical debt. Each shortcut taken in the pursuit of autonomous operation-each approximation, each reliance on learned correlation instead of first principles-is the past’s mortgage, paid by the present’s computational resources and, ultimately, by the integrity of the simulation. Future work must address not just what a system simulates, but how it ages, and what mechanisms can gracefully accommodate the decay inherent in all complex systems.
The pursuit of fully autonomous CFD, therefore, isn’t about achieving a perfect, static solution. It’s about building systems capable of continuous self-assessment, of recognizing the limits of their own knowledge, and of actively seeking validation from the deterministic universe they attempt to model. The goal isn’t flawless prediction, but resilient adaptation – a slow, deliberate flow toward increasingly robust understanding.
Original article: https://arxiv.org/pdf/2602.11666.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 11:41