Author: Denis Avetisyan
Researchers have developed a hierarchical system that allows robots to better understand and predict the outcomes of complex actions, significantly improving long-term task planning.
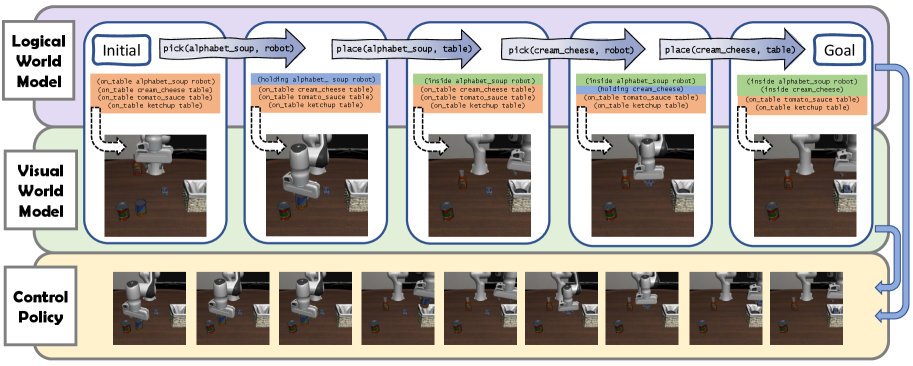
This work introduces a hierarchical world model combining logical and visual predictions for enhanced Vision-Language-Action (VLA) performance in robotics.
Effective robotic planning requires navigating the tension between long-horizon reasoning and perceptual grounding, yet current world models often prioritize either predictive accuracy in visual domains or robot-executable symbolic logic. This paper introduces [latex]H-WM[/latex]: Robotic Task and Motion Planning Guided by Hierarchical World Model, a novel approach that jointly predicts logical and visual state transitions within a unified framework. By integrating a high-level symbolic model with a low-level visual representation, [latex]H-WM[/latex] provides stable intermediate guidance for complex tasks, mitigating error accumulation and enabling robust performance across extended sequences. Will this hierarchical approach unlock more adaptable and reliable robotic systems capable of tackling increasingly intricate real-world challenges?
The Illusion of Understanding: Bridging Perception and Plan
Conventional robotic systems often falter when confronted with tasks demanding both intricate planning and accurate environmental understanding. These machines typically excel at pre-programmed, repetitive actions within highly structured settings, but struggle with the ambiguities and unforeseen circumstances of the real world. The core difficulty lies in the disconnect between a robot’s ability to reason about goals and actions – its “symbolic” intelligence – and its capacity to interpret raw sensory data, such as visual or tactile input. This separation creates a bottleneck; the robot must translate abstract plans into concrete movements while simultaneously processing imperfect and often noisy perceptual information, resulting in brittle performance and limited adaptability. Consequently, even seemingly simple tasks, like grasping an object amidst clutter or navigating a dynamic environment, present significant challenges for traditional robotic architectures.
Historically, robotic systems have approached problem-solving by rigidly separating the phases of planning and perception. A robot might receive a high-level goal – such as ‘clear the table’ – and then independently attempt to interpret visual data to identify objects and their locations. This compartmentalization creates fragility; even slight deviations from expected sensory input, like an object being partially obscured or in an unusual pose, can derail the entire process. Because the planning stage doesn’t inherently account for the inherent messiness of real-world perception, the system struggles to adapt, leading to frequent failures and a limited ability to generalize to new environments or unforeseen circumstances. This disconnect ultimately hinders the creation of truly robust and adaptable robots capable of operating reliably in complex, dynamic settings.
The pursuit of truly adaptable robots necessitates a departure from segregated systems of symbolic planning and sensory perception. Current robotic architectures often treat high-level reasoning – the ‘what’ and ‘why’ of a task – as distinct from the processing of raw sensory data, creating a performance bottleneck when facing real-world ambiguity. A unified framework proposes instead a seamless integration, allowing symbolic representations – like goals and object relationships – to be directly grounded in perceptual input. This convergence enables a robot to not only plan a sequence of actions, but to dynamically adjust those plans based on immediate sensory feedback, fostering robustness against unforeseen circumstances and environmental variations. Such an approach moves beyond brittle, pre-programmed behaviors, paving the way for robots capable of genuine, flexible task execution in complex and unpredictable environments.
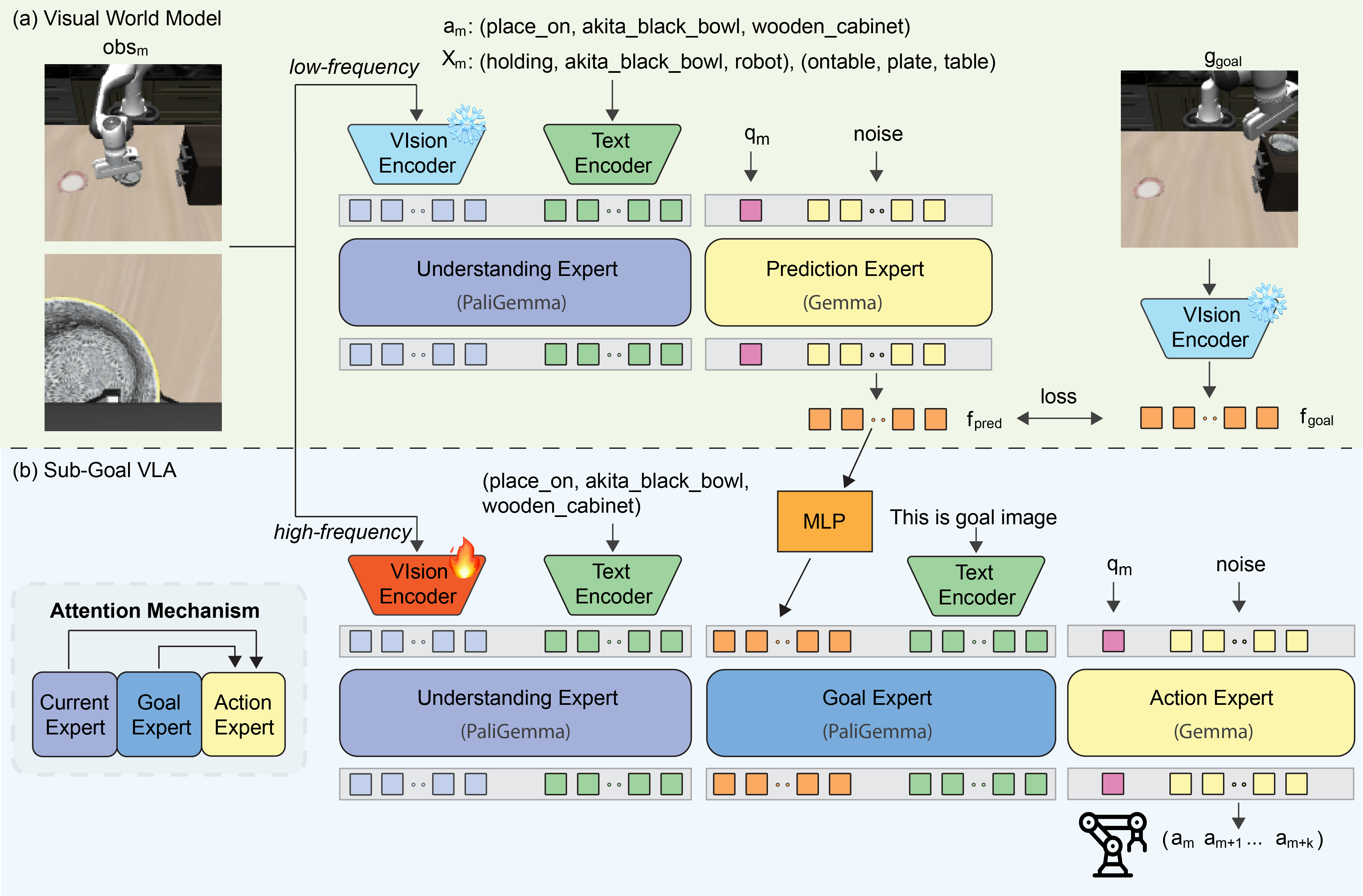
A Hierarchical Echo of Reality: Modeling the World
The Hierarchical World Model represents an advancement over conventional world modeling techniques by simultaneously predicting changes in both logical and visual states. Traditional world models typically focus on predicting either the next visual frame or the evolution of symbolic representations of the environment; this model integrates these two approaches. Specifically, it forecasts future states by jointly estimating the subsequent logical state – representing abstract relationships and properties – alongside the corresponding visual representation. This joint prediction capability allows the model to anticipate not only what will be seen, but also why, creating a more complete and actionable understanding of the environment’s dynamics and supporting more effective planning and decision-making.
The architecture integrates a Logical World Model and a Visual World Model to achieve environmental understanding. The Logical World Model operates on symbolic representations, enabling reasoning about abstract concepts and relationships within the environment. Concurrently, the Visual World Model processes perceptual inputs, grounding the symbolic representations in visual observations. This dual approach allows the system to represent the environment both abstractly and concretely; the Logical World Model provides high-level planning capabilities while the Visual World Model provides perceptual context and handles ambiguities present in real-world sensory data. This synergistic combination enables a more robust and comprehensive environmental understanding than either model could achieve independently.
The Hierarchical World Model’s predictive capabilities in both logical and visual modalities enable intermediate guidance during task execution, which is crucial for robust long-horizon planning. This approach allows the model to anticipate future states and refine its actions accordingly, resulting in improved performance on complex tasks. Quantitative evaluation demonstrates that this predictive guidance yields a significantly higher Q-Score and Success Rate when compared to baseline methods lacking this ability, indicating a more effective strategy for navigating and achieving goals in dynamic environments.
![Our H-WM-guided policy outperforms the vanilla [latex]\pi_{0.5}[/latex] policy on long-horizon tasks by leveraging bilevel guidance and future visual subgoals to reason over the full task horizon, correctly identify target objects, and execute critical intermediate steps, leading to successful completion.](https://arxiv.org/html/2602.11291v1/x2.png)
The Illusion of Intelligence: Aligning Logic and Perception
The Visual World Model achieves perceptual realism through training with a Sliced Wasserstein Loss. This loss function minimizes the distance between predicted and observed visual distributions, effectively comparing the distributions of images rather than individual pixel values. By focusing on the overall distribution, the model learns to generate visually plausible outputs even if exact pixel-level accuracy isn’t achieved. The “sliced” aspect of the loss involves projecting the high-dimensional image distributions onto random lower-dimensional subspaces, which improves computational efficiency and stability during training. This approach allows the model to learn a robust representation of visual data and generate realistic imagery by matching the statistical properties of observed scenes.
The Logical World Model leverages Large Language Model (LLM) fine-tuning to enhance its predictive capabilities regarding action sequences and future states. This process adapts a pre-trained LLM by exposing it to data generated from the simulated environment, specifically training it to forecast structured action plans and subsequent world states given current conditions. Fine-tuning optimizes the LLM’s parameters to align its outputs with the dynamics of the learned environment, enabling it to predict likely future outcomes based on agent actions and environmental factors. The resulting model can then generate coherent and plausible action sequences, effectively serving as a predictive engine for planning and decision-making within the simulation.
Flow Matching is utilized to train the Vision-Language-Action Model by directly optimizing a probabilistic mapping from multimodal observations – encompassing visual data and language instructions – to corresponding actions within the established world model. This technique frames the training process as learning a continuous normalizing flow, enabling the model to efficiently estimate the probability of an action given an observation and linguistic prompt. By maximizing the likelihood of observed actions under the learned flow, the model learns to generate appropriate responses to both visual input and natural language commands, effectively bridging the gap between perception, language understanding, and action execution within the simulated environment.
The Mirage of Autonomy: Enabling Robust Long-Horizon Execution
The newly developed robotic framework demonstrates a capacity for executing complex, long-horizon tasks – sequences demanding numerous coordinated actions over extended periods. This capability stems from an architecture designed not simply to react to immediate stimuli, but to anticipate future states and plan accordingly. The system successfully manages intricate procedures, such as assembling objects with multiple components or navigating challenging terrains requiring precise movements and adjustments. By breaking down these lengthy tasks into manageable sub-goals, the framework achieves a level of performance previously unattainable, paving the way for robots capable of autonomously undertaking sophisticated operations in dynamic, real-world scenarios.
The Hierarchical World Model enhances a robot’s ability to navigate unpredictable situations by offering predictive guidance at each step of a complex task. Rather than rigidly following a pre-defined plan, the model anticipates future states and adjusts the robot’s actions accordingly, effectively creating a feedback loop that corrects for errors and accommodates unexpected changes in the environment. This intermediate guidance doesn’t merely react to disturbances; it proactively mitigates potential issues by considering the likely consequences of each action, fostering a level of resilience previously unattainable in long-horizon tasks. The system effectively ‘looks ahead’ and adapts, enabling continued successful execution even when faced with unforeseen obstacles or deviations from the initial plan, resulting in significantly improved robustness and adaptability.
The development of this framework signifies a considerable advancement in robotic autonomy, paving the way for more effective operation within challenging, real-world scenarios. Evaluations on the LIBERO-LoHo benchmark demonstrate a clear performance advantage over existing methods, highlighting the system’s improved capacity to manage intricate, extended tasks. This isn’t merely incremental progress; the ability to reliably execute long-horizon tasks represents a fundamental shift, moving robots closer to true independence and adaptability. By consistently achieving higher scores in complex environments, the research indicates a potential for broader application in fields such as logistics, search and rescue, and even domestic assistance, ultimately reducing reliance on pre-programmed routines and human intervention.
The pursuit of robust robotic systems, as detailed in this work on Hierarchical World Models, echoes a familiar pattern. One attempts to impose order, to predict every contingency, yet the system invariably evolves beyond initial design. It’s a constant negotiation with emergent behavior. As John McCarthy observed, “Every architectural choice is a prophecy of future failure.” This isn’t pessimism, but a recognition that complexity begets unpredictability. The model’s emphasis on logical state transitions and visual subgoals represents a striving for control, a mapping of the potential chaos. Yet, the very act of modeling introduces new avenues for divergence. The system doesn’t simply execute a plan; it grows through it, learning and adapting in ways unforeseen. It’s a beautiful, humbling process.
What Lies Ahead?
This work, predictably, does not solve robotic manipulation. It merely refines the scaffolding upon which future failures will be built. The hierarchical world model offers a more graceful degradation path than many preceding attempts, a virtue often mistaken for progress. A system that never breaks is, after all, a system that does nothing. The true test will not be achieving isolated successes on benchmark tasks, but observing how readily this framework adapts-or misadapts-when confronted with the inherent chaos of real-world deployment.
The reliance on symbolic reasoning, while currently effective, represents a point of brittle fragility. The world is rarely so obliging as to conform to pre-defined logical states. Future iterations must address the inevitable mismatch between symbolic representation and perceptual reality-perhaps by embracing controlled inconsistency, or by acknowledging that a perfectly accurate model is not merely unnecessary, but actively detrimental.
The field now faces a choice. It can pursue ever-more-complex architectures, striving for a complete and total understanding of the environment. Or it can accept that robotics is, fundamentally, an exercise in controlled improvisation. Perfection, it seems, leaves no room for people-or for robots that might, occasionally, surprise their creators.
Original article: https://arxiv.org/pdf/2602.11291.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 11:39