Author: Denis Avetisyan
New research explores how to make the inner workings of machine learning models accessible to everyone, without requiring programming expertise.
This study evaluates a user-friendly explainability module for no-code machine learning, demonstrating its usability and identifying distinct needs for novice and expert users.
Despite the increasing reliance on machine learning in critical domains, the ‘black box’ nature of many models hinders trust and understanding, particularly for non-experts. This challenge is addressed in ‘Explaining AI Without Code: A User Study on Explainable AI’, which presents and evaluates a novel, integrated explainability module within a no-code machine learning platform. The user study-involving both novice and expert participants-demonstrated high usability and positive user satisfaction with explanations generated via techniques like Partial Dependence Plots, Permutation Feature Importance, and KernelSHAP. However, the research also revealed differing needs for explanation detail between user groups; how can XAI tools effectively balance accessibility for novices with the demands of experienced data scientists?
The Illusion of Understanding: Why We Trust (or Don’t) Black Boxes
Despite the remarkable progress in machine learning, a significant challenge persists: many advanced models function as opaque ‘black boxes’. These systems, while capable of achieving high accuracy, often lack transparency in their decision-making processes, making it difficult to understand how a particular prediction was reached. This lack of interpretability isn’t merely an academic concern; it actively hinders the widespread adoption of these powerful tools, particularly in critical domains. Users are naturally hesitant to trust predictions without knowing the underlying reasoning, especially when those predictions impact important life decisions or financial outcomes. Consequently, the inability to peer inside these models creates a barrier to accountability and fosters skepticism, limiting their potential benefit even when demonstrably effective.
The opacity of machine learning models presents unique challenges when deployed in critical sectors such as healthcare and finance. In these high-stakes environments, decisions directly impact human well-being and financial stability, demanding a level of accountability that ‘black box’ algorithms struggle to provide. For instance, a loan application denied by an inscrutable AI offers no recourse for understanding – or challenging – the rationale behind the decision. Similarly, in medical diagnoses, the inability to trace how an algorithm arrived at a particular conclusion hinders a physician’s ability to validate the assessment and potentially overrides crucial clinical judgment. This lack of interpretability doesn’t simply erode trust; it creates significant ethical and practical barriers to widespread adoption, as regulatory bodies and end-users alike require a clear understanding of the factors driving automated decisions.
The opacity of many machine learning models presents a significant challenge to their responsible deployment, particularly regarding the identification of inherent biases and the guarantee of reliable outcomes. Without insight into the reasoning behind a prediction, it becomes exceedingly difficult to discern whether the model is basing its conclusions on legitimate correlations or spurious, potentially discriminatory, patterns within the data. This lack of interpretability hinders effective debugging; errors or unfair outcomes may go unnoticed, eroding confidence in the system’s fairness and accuracy. Consequently, stakeholders struggle to validate the model’s behavior, assess its limitations, and ultimately, trust its decisions – a critical requirement for widespread adoption in sensitive areas like loan applications, medical diagnoses, and criminal justice.
The pursuit of Explainable AI, or XAI, represents a fundamental shift in machine learning development, moving beyond mere predictive accuracy to prioritize interpretability. These emerging models aren’t designed simply to forecast outcomes, but to articulate the rationale behind those predictions in a manner understandable to humans. This involves techniques that highlight the specific features or data points driving a decision, providing insights into the model’s internal logic. By offering this transparency, XAI aims to foster trust, facilitate debugging, and enable meaningful human oversight, particularly crucial in sensitive domains where accountability and fairness are paramount. Ultimately, XAI seeks to transform machine learning from an opaque ‘black box’ into a collaborative tool, empowering users to understand, validate, and confidently leverage its power.
Demystifying the Algorithm: No-Code and the Promise of Transparency
DashAI distinguishes itself by integrating no-code machine learning functionality with a robust explainability framework. This combination allows users to construct and deploy predictive models without needing to write code, thereby broadening access to artificial intelligence applications. The platform’s core innovation lies in its ability to not only generate predictions but also to provide insights into why those predictions were made, offering a level of transparency often absent in traditional machine learning systems. This dual focus on usability and interpretability is intended to accelerate AI adoption across various sectors and user skill levels.
DashAI facilitates model creation and deployment through a user interface designed to minimize the need for manual coding. The platform employs a visual, drag-and-drop methodology for data ingestion, feature engineering, and model selection, abstracting away complex scripting requirements. Users can train and deploy machine learning models by defining parameters and workflows through the graphical interface, rather than writing code in languages such as Python or R. This approach allows individuals with limited programming experience to leverage the benefits of machine learning for their specific applications, significantly reducing the time and resources required for model development and implementation.
The DashAI platform incorporates an ‘Explainability Module’ designed to provide insights into the factors driving model predictions. This module functions by analyzing feature importance and identifying the specific data points most influential in generating a given output. It delivers explanations through techniques such as feature attribution and counterfactual analysis, allowing users to understand why a model made a particular decision. The module outputs are presented in a user-friendly format, facilitating interpretation by both technical and non-technical stakeholders and supporting model debugging, validation, and trust.
DashAI’s approach to artificial intelligence deployment intentionally reduces complexities traditionally associated with model implementation, thereby broadening access for users without specialized programming expertise. This is substantiated by a documented task success rate of at least 80% across all explainability functions within the platform. This high success rate indicates that users are consistently able to understand the rationale behind model predictions, fostering increased trust and facilitating informed decision-making based on AI outputs. The ability to reliably interpret model behavior is a key component in driving user confidence and promoting wider adoption of machine learning solutions.
Under the Hood: Methods for Illuminating Model Reasoning
DashAI’s Explainability Module utilizes Permutation Feature Importance and Partial Dependence Plots to determine the influence of individual input features on model predictions. Permutation Feature Importance assesses this influence by randomly shuffling the values of a single feature and measuring the resulting decrease in model performance; larger decreases indicate greater importance. Partial Dependence Plots depict the average predicted outcome as a function of one or two features, holding all others constant, thus illustrating the marginal effect of those features. These methods provide quantitative metrics and visual representations of feature contributions, facilitating the identification of the most influential variables driving model behavior.
Partial Dependence Plots (PDPs) are used to visualize the relationship between a feature and the predicted outcome of a machine learning model, averaged over the values of all other features. Specifically, a PDP calculates the average prediction across the dataset for different values of the feature of interest, holding all other features constant. This allows for the identification of whether the feature has a positive or negative correlation with the prediction, and whether the relationship is linear or non-linear. By examining PDPs for multiple features, a global understanding of model behavior is achieved, and these visualizations directly support the creation of Global Explanations that summarize the overall impact of each feature on model predictions.
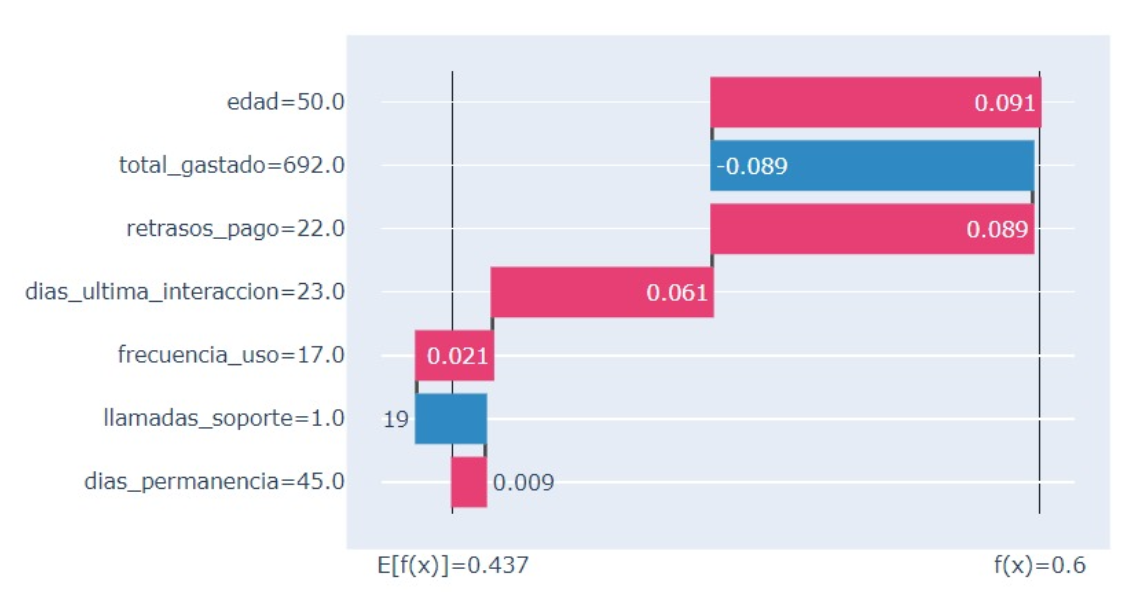
KernelSHAP, a unified approach to explainable AI, calculates the contribution of each feature to an individual prediction by considering all possible feature combinations. It leverages a weighted average of Shapley values, derived from game theory, to ensure fair attribution. This method approximates [latex] \phi_{i} = \sum_{S \subset eq F \setminus \{i\}} \frac{|S|! |F – S – \{i\}|!}{|F|!} f(S \cup \{i\}) [/latex], where [latex] \phi_{i} [/latex] is the Shapley value for feature i, F is the set of all features, and f is the model output. The result is a feature importance vector for a specific instance, indicating the positive or negative impact each feature had on the model’s prediction, providing local interpretability.
The integration of Permutation Feature Importance, Partial Dependence Plots, and KernelSHAP provides a multi-faceted approach to model interpretability. Permutation Feature Importance assesses feature relevance by quantifying the decrease in model performance when a feature’s values are randomly shuffled. Partial Dependence Plots then illustrate the average marginal effect of one or two features on the predicted outcome. KernelSHAP refines this by calculating the contribution of each feature to an individual prediction, offering local interpretability. By combining global overviews of feature impact with local explanations for specific instances, users can not only identify the most influential features – the key drivers – but also detect potentially problematic relationships indicative of model bias.
Beyond Metrics: Validating Interpretability Through the User Experience
DashAI prioritizes practical effectiveness by centering its evaluation around the end-user experience. Recognizing that interpretability isn’t simply about technical accuracy, the platform employs user-centric methods to gauge how well explanations genuinely resonate with and inform those who interact with the system. This approach moves beyond purely algorithmic assessments, focusing instead on whether explanations are easily understood, intuitive to navigate, and ultimately build trust in the automated insights provided. By directly measuring user perceptions, DashAI ensures that its explainability features aren’t just theoretically sound, but actively contribute to meaningful human understanding and informed decision-making.
The effectiveness of DashAI’s explainability features hinges not only on the accuracy of the explanations themselves, but also on how easily users can interact with and understand the interface presenting them. To quantify this, the System Usability Scale (SUS) was employed – a widely-recognized tool for assessing perceived usability. This standardized questionnaire probes aspects like learnability, efficiency, error management, and overall satisfaction with the interface’s design. A higher SUS score indicates a more intuitive and user-friendly experience, suggesting that users can readily access and interpret the provided explanations without undue cognitive load. By prioritizing usability through SUS evaluation, DashAI aims to ensure that its explainability features are not just informative, but also genuinely accessible and beneficial to a broad range of users.
To rigorously assess how well DashAI’s explanations resonate with users, the platform employs the Explanation Satisfaction Scale, a dedicated metric for gauging comprehension and usefulness. This scale directly captures user perceptions of the provided explanations, moving beyond simple usability to pinpoint genuine satisfaction. Importantly, the scale demonstrated acceptable reliability, achieving a Cronbach’s alpha of 0.74 during testing. This statistical measure confirms internal consistency within the scale itself, indicating that it consistently measures the same construct – user satisfaction – and providing confidence in the validity of the gathered feedback. The resulting data offers valuable insights into whether the explanations effectively communicate the model’s reasoning, ultimately guiding improvements to enhance user understanding and trust.
Evaluation of user trust in the automated insights provided by DashAI revealed a Cronbach’s alpha of 0.60, a metric suggesting limited internal consistency within the measurement tool itself and raising concerns about the robustness of the findings. This score indicates that while some users expressed confidence in the system’s outputs, others did not, creating a potentially unreliable assessment of overall trust. Consequently, the developers identified a clear need for focused improvements to bolster user confidence, potentially through more transparent algorithmic explanations, enhanced data visualization, or the incorporation of user feedback mechanisms to address specific concerns and build a stronger foundation of trust in the automated decision-making process.
The study highlights a familiar pattern. The integrated explainability module, while lauded for usability, inevitably exposes the gap between theoretical understanding and practical application. It’s almost predictable; users, even those comfortable with no-code ML, reveal differing needs for explanation depending on expertise. This reinforces a core truth: elegant interfaces and simplified tools don’t eliminate complexity, they merely relocate it. As Donald Knuth observed, “Premature optimization is the root of all evil.” The drive to simplify explanation before fully understanding user needs is a similar optimization. The module functions, user satisfaction is positive, but the differing requirements suggest the ‘perfect’ explanation, universally understood, remains elusive. It’s a feature, not a bug; the system will always be shaped by production use, revealing unanticipated edge cases and demands.
What’s Next?
The demonstrated usability of explainable AI modules within no-code platforms is, predictably, not the destination. It’s merely a shifting of the problem. The current focus on presenting explanations-partial dependence plots, feature importance scores-assumes comprehension is the bottleneck. It isn’t. The bottleneck is trust, and then the inevitable discovery that explanations are post-hoc rationalizations, not guarantees of predictable behavior. The system will, at some point, contradict its own justifications. It always does.
Differentiation between novice and expert users suggests a familiar pattern: more sophisticated users demand explanations that match their pre-existing mental models, even if those models are flawed. This isn’t a search for truth, but a validation of existing bias, dressed up as interpretability. Future work will likely refine these presentation layers, but should also confront the uncomfortable truth that many ‘explanations’ simply obscure the inherent opacity of complex systems. The goal shouldn’t be to make models explainable, but to accept their fundamental unknowability.
The proliferation of no-code/low-code platforms ensures this problem will scale. The demand for ‘AI for everyone’ will inevitably outstrip the capacity to educate those users about the limitations of the tools they wield. The next generation of XAI research won’t be about better visualizations; it will be about damage control. Perhaps, instead of more microservices, we need fewer illusions.
Original article: https://arxiv.org/pdf/2602.11159.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 06:50