Author: Denis Avetisyan
New research demonstrates a framework for optimizing proactive agents to not only achieve goals but also minimize disruption and maximize user engagement.

Behavior-integrated reinforcement learning with retrospective reasoning and prospective planning pushes forward Pareto frontiers for multi-objective optimization in agent design.
Balancing task completion with positive user experience remains a central challenge in the development of increasingly autonomous agents. This is addressed in ‘Pushing Forward Pareto Frontiers of Proactive Agents with Behavioral Agentic Optimization’, which introduces a novel reinforcement learning framework, BAO, designed to optimize both reward and user engagement in proactive agents. By integrating behavior enhancement with behavior regularization-leveraging retrospective reasoning and prospective planning-BAO demonstrably surpasses existing agentic RL baselines and even rivals the performance of commercial large language models. Will this approach pave the way for truly collaborative and efficient AI agents capable of seamlessly navigating complex, multi-turn interactions?
The Challenge of Reactive Systems
Conventional artificial intelligence agents frequently exhibit limitations in sustained dialogue, typically responding to immediate prompts rather than actively steering conversations toward meaningful outcomes. This reactive approach stems from a reliance on pattern matching and short-term memory, hindering their ability to anticipate user needs or formulate long-range conversational goals. Consequently, interactions can feel disjointed and inefficient, as the agent struggles to maintain context or offer genuinely helpful suggestions beyond the scope of the present query. This contrasts sharply with human conversation, which is characterized by proactive contributions, anticipatory questioning, and a shared understanding of evolving objectives, highlighting a critical gap in current agent design.
Current artificial intelligence agents frequently operate reactively, responding to immediate stimuli rather than anticipating future needs or guiding interactions towards specific goals. True proactivity, however, demands a capacity to connect present understanding with projected outcomes – a significant hurdle for standard reinforcement learning techniques. These methods typically focus on maximizing immediate rewards, often lacking the ability to reason about long-term consequences or plan a sequence of actions to achieve a distant objective. Bridging this gap requires agents to not only assess the current situation but also to model potential future states and evaluate the effectiveness of different courses of action, effectively creating an internal simulation of possibilities to inform present decisions and demonstrate genuinely proactive behavior.
Truly proactive artificial intelligence necessitates a shift from merely reacting to stimuli to instead anticipating needs and formulating plans to address them. This demands more than sophisticated response generation; it requires robust reasoning capabilities that allow an agent to model potential future states and evaluate the consequences of different actions. The ability to construct and maintain an internal representation of goals, coupled with the capacity to plan sequences of actions to achieve those goals, is fundamental to this proactive behavior. Simply put, an agent must not only understand the current situation but also extrapolate likely developments and formulate strategies – essentially, thinking several steps ahead – to effectively guide interactions and deliver meaningful assistance beyond immediate requests.

Agentic Reinforcement Learning: The Foundation of Proactivity
Agentic Reinforcement Learning (RL) moves beyond traditional reactive agents by enabling them to address tasks requiring sequential decision-making over multiple steps, or ‘turns’. Conventional RL typically optimizes for immediate rewards based on a single input-action-reward cycle. Agentic RL, however, introduces the capability for an agent to maintain internal state, formulate subgoals, and execute a series of actions to achieve a broader objective. This is accomplished by allowing the agent to observe the results of its actions and then autonomously determine subsequent actions without requiring continuous external prompting for each step. The result is a shift from responding to individual stimuli to proactively pursuing long-term goals, enhancing performance in complex, multi-stage tasks.
Traditional reinforcement learning agents react to immediate states and rewards; agentic RL fundamentally changes this interaction by enabling agents to internally represent goals and develop plans to achieve them. This involves shifting from a stimulus-response paradigm to one where the agent actively considers future states and anticipates necessary actions to fulfill long-term objectives. Consequently, agents can proactively seek information, modify their environment, and execute sequences of actions beyond those directly prompted by the current observation, effectively bridging the gap between reactive and anticipatory behavior. This proactive capability is achieved through mechanisms allowing agents to maintain internal state representing goals, beliefs, and predicted outcomes, which guide planning and decision-making processes.
While Agentic Reinforcement Learning represents a significant advancement towards proactive agent behavior, its direct implementation does not inherently ensure superior performance or safety. Observed limitations include suboptimal planning in complex environments and the potential for unintended consequences arising from flawed goal formulation or execution. Consequently, ongoing research focuses on refinements such as improved reward function design, constraint incorporation to mitigate risk, and the development of robust plan evaluation techniques to address these challenges and enhance the reliability and predictability of agentic systems. These refinements are critical for deploying Agentic RL in real-world applications where predictable and safe behavior is paramount.
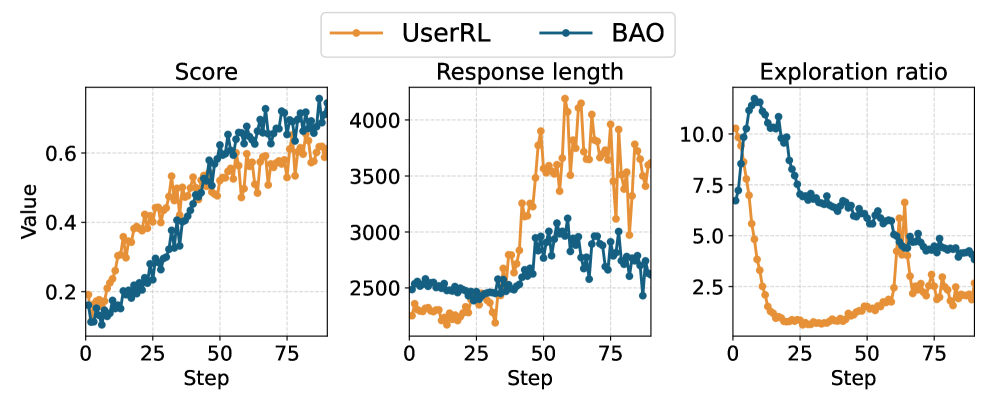
BAO: Sculpting Proactivity Through Behavioral Shaping
BAO, or Behavioral Agent Optimization, builds upon Agentic Reinforcement Learning by introducing two complementary techniques – Behavior Enhancement and Behavior Regularization – designed to actively guide agent behavior during the training process. Behavior Enhancement employs supervised fine-tuning, leveraging expert demonstrations or pre-defined strategies to accelerate the agent’s acquisition of preferred behaviors. Concurrently, Behavior Regularization shapes the agent’s policy updates at each turn by modifying the reward signal, encouraging the adoption of desirable characteristics and discouraging suboptimal actions. This combined approach allows for direct influence over behavioral traits alongside standard reward-based learning, facilitating the development of agents exhibiting more predictable and effective interaction strategies.
Behavior Enhancement and Regularization are core components of proactive agent training. Behavior Enhancement employs supervised fine-tuning, leveraging demonstrations of desired proactive behaviors to initialize the agent’s policy and accelerate learning. Simultaneously, Regularization modifies the reinforcement learning process by applying turn-level reward shaping; this technique adjusts the reward signal at each step to encourage behaviors aligned with proactive strategies and discourage undesirable actions. This combination facilitates policy updates that prioritize both immediate reward and long-term proactive planning, effectively guiding the agent towards optimal behavior without relying solely on sparse, delayed rewards.
BAO’s performance gains stem from simultaneous optimization of agent behavior and the reward function during training. This approach allows agents to effectively manage the intricacies of multi-turn interactions, exceeding the capabilities of systems optimized for reward alone. The resulting agent policies often demonstrate a range of performance characteristics, representing tradeoffs between different objectives-a phenomenon frequently visualized and analyzed using the Pareto Frontier. This frontier illustrates the set of solutions where improving one objective necessarily degrades another, allowing developers to select policies that best suit specific application requirements and prioritize desired behaviors.
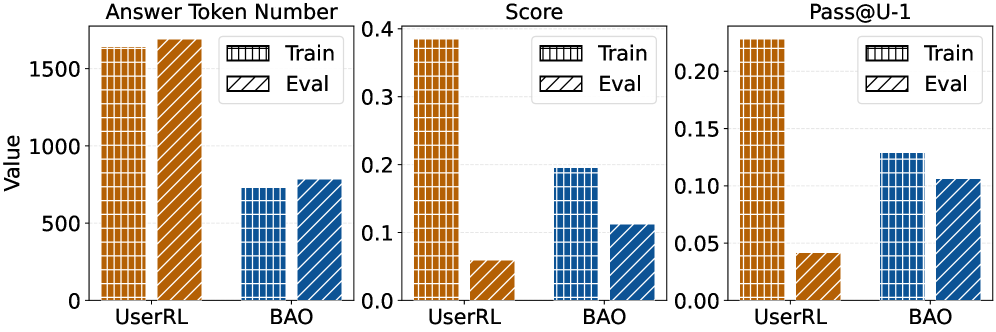
Demonstrating Impact: Performance and User Engagement
Rigorous empirical evaluation reveals that the BAO agent demonstrably surpasses existing UserRL baselines in task performance across a diverse set of challenges. This improvement is quantitatively evidenced by exceeding the UserRL performance on the Pass@U-1 metric – a key indicator of successful task completion within a specified number of attempts. The observed gains aren’t simply about achieving results, but about doing so with greater consistency and reliability, suggesting BAO’s approach to learning and problem-solving yields a more robust and capable agent. This enhanced performance signifies a substantial advancement in the field, offering a pathway towards more effective and autonomous agents capable of tackling complex tasks.
Analysis reveals that the implemented system fosters heightened user engagement through a notably reduced User Involvement Rate (UR) when contrasted with the UserRL baseline. This decrease in required user intervention doesn’t signal diminished quality; rather, it points to a substantial gain in operational efficiency. The system effectively handles a greater proportion of tasks autonomously, maintaining performance levels while freeing users from repetitive oversight. This improved balance between automation and human oversight suggests a more streamlined and productive interaction, indicating the system’s capacity to learn and adapt to user needs with minimal continued direction.
Rigorous evaluation of the system’s dependability involved assessing both the variety and meaningfulness of its responses, utilizing metrics like Self-BLEU and NV-Embed-v2 to confirm diverse and semantically coherent outputs. Crucially, researchers actively addressed the potential for Reward Hacking – where an agent exploits loopholes to maximize rewards without genuinely improving performance – and successfully achieved a Reward Translation Rate (RTR) of 0.575. This figure indicates a substantially improved alignment between received rewards and actual task completion, a significant leap from the 0.154 RTR observed in the UserRL baseline, and reinforcing the system’s robust and reliable operation.
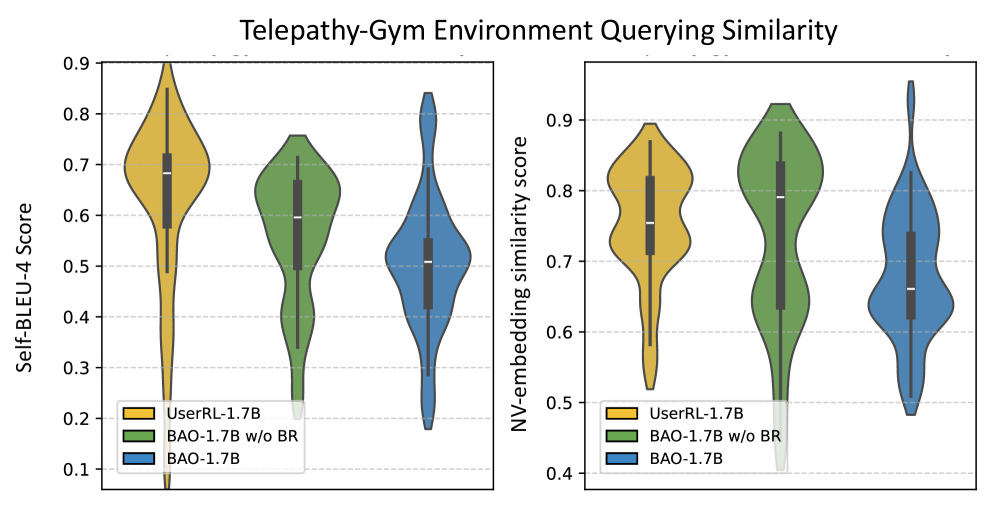
The pursuit of proactive agents, as detailed in this work, necessitates a holistic understanding of system behavior. Just as a complex organism responds to stimuli, these agents must balance competing objectives – task completion and user engagement. Vinton Cerf aptly stated, “Any sufficiently advanced technology is indistinguishable from magic.” This sentiment resonates with the BAO framework’s ability to seemingly anticipate user needs through retrospective reasoning and prospective planning. The paper’s emphasis on behavior regularization isn’t merely about optimizing performance; it’s about crafting a system where the interaction feels natural and intuitive, blurring the line between tool and partner. This approach acknowledges that true intelligence lies not just in what a system can do, but how it does it.
Where Do We Go From Here?
The pursuit of proactive agency, as demonstrated by this work, inevitably reveals the brittle nature of neatly defined objectives. Optimizing for both task completion and user engagement-a seemingly harmonious pairing-highlights a deeper truth: any regularization, however intuitively appealing, introduces a new set of constraints, and therefore, new failure modes. The architecture presented attempts to bridge the gap between retrospective analysis of interaction and prospective planning, but the fundamental difficulty remains: truly anticipating the nuances of human preference is a moving target. Future work must grapple not only with more sophisticated behavioral models, but also with methods for gracefully adapting to the inevitable mismatch between model and reality.
A crucial area for expansion lies in understanding the limits of Pareto optimization itself. While identifying a spectrum of acceptable trade-offs is valuable, it does not address the question of which trade-off is ultimately most desirable in any given context. This necessitates a deeper integration of value alignment research-moving beyond simply minimizing disruption to actively pursuing goals that resonate with long-term user well-being. The current framework’s reliance on interaction minimization, while pragmatic, risks creating agents that are merely less annoying, rather than genuinely helpful.
Ultimately, the success of these systems will not be measured by benchmark scores, but by their seamless integration into daily life. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Original article: https://arxiv.org/pdf/2602.11351.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 06:48