Author: Denis Avetisyan
A large-scale analysis of open-source Android and iOS projects reveals how AI coding agents are performing in real-world development workflows.
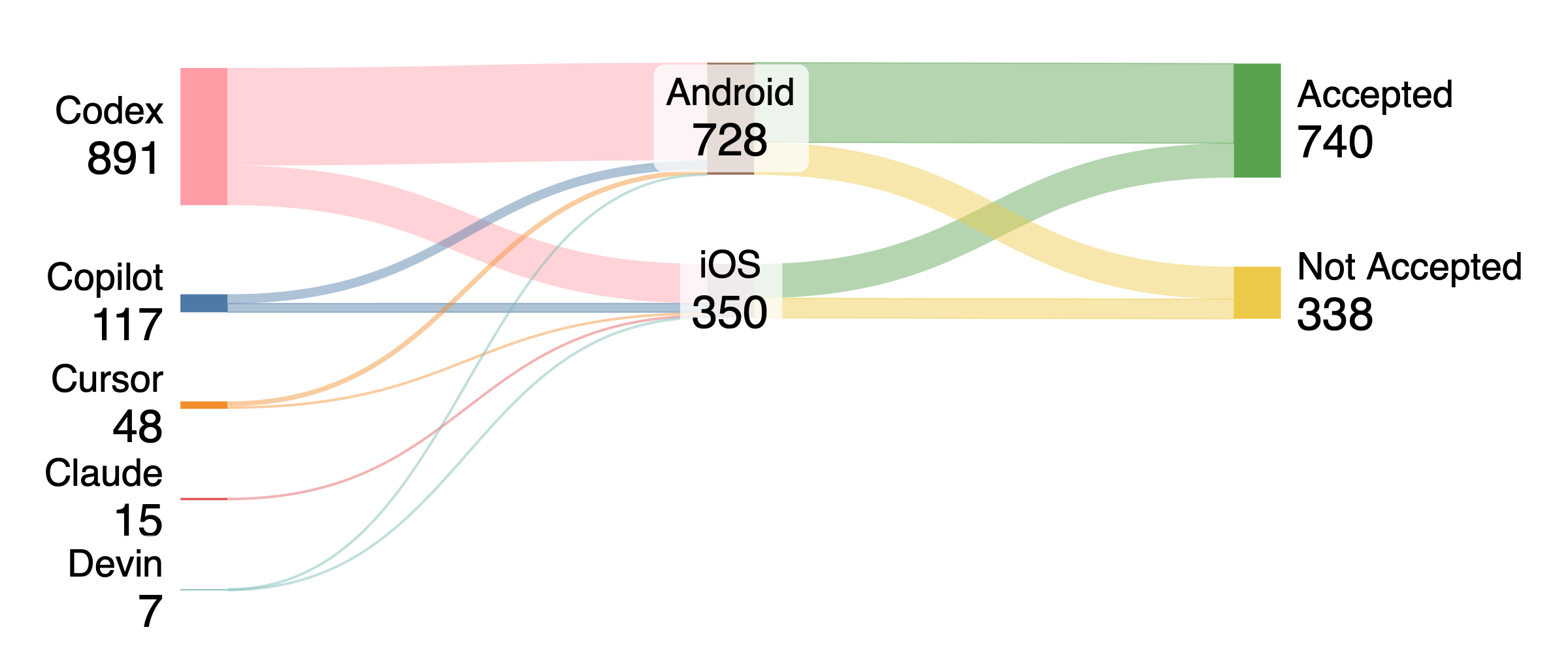
Nearly 3,000 AI-authored pull requests were analyzed to determine acceptance rates and resolution times across both Android and iOS platforms, revealing performance differences in routine tasks and platform variability.
While artificial intelligence is rapidly transforming software engineering, empirical understanding of its impact on mobile development remains limited. This paper, ‘On the Adoption of AI Coding Agents in Open-source Android and iOS Development’, presents the first large-scale analysis of nearly 3,000 AI-authored pull requests across open-source Android and iOS projects, revealing that agents excel at routine coding tasks and demonstrate platform-specific acceptance patterns. Specifically, Android projects receive twice the volume of AI contributions as iOS and exhibit greater variability in pull request acceptance rates, while tasks like refactoring consistently face longer review times. These findings establish critical baselines for evaluating AI agents in mobile ecosystems, but how can we design agentic systems that consistently improve code quality and developer productivity across diverse platforms and task complexities?
The Evolving Landscape of Automated Contribution
The landscape of software development is undergoing a rapid transformation with the proliferation of AI coding agents. Tools like Codex, Copilot, and Devin are no longer theoretical curiosities, but increasingly integrated into daily workflows, actively authoring code contributions across a wide spectrum of projects. This shift represents a fundamental change in how software is created, moving beyond simple code completion to genuine automated contribution. These agents are designed to assist developers, and, in some cases, operate autonomously, generating code snippets, entire functions, or even complete features. The growing adoption of these tools necessitates a rigorous evaluation of their capabilities and impact on the software development lifecycle, prompting research into their effectiveness and the quality of their contributions.
Determining the true efficacy of AI coding agents necessitates the application of quantifiable metrics that move beyond simple code compilation. Researchers are increasingly focused on pull request (PR) acceptance rate – the proportion of AI-authored contributions successfully integrated into a project – as a key indicator of practical utility. However, acceptance rate alone provides an incomplete picture; resolution time – the duration from PR submission to merging – reveals crucial information about the agent’s ability to address reviewer feedback and navigate the collaborative coding process. A shorter resolution time suggests the AI not only generates functional code but also produces contributions that align with existing project standards and require minimal iterative refinement, ultimately streamlining development workflows and maximizing developer productivity. These metrics, when considered in tandem, offer a robust framework for benchmarking AI agent performance and tracking improvements in code quality and collaborative efficiency.
A comprehensive analysis of 2,901 pull requests generated by AI coding agents, sourced from the publicly available AIDev Dataset, reveals crucial details about their performance in real-world software development scenarios. This large-scale investigation moves beyond anecdotal evidence, offering statistically significant insights into how these agents function across a diverse range of projects – varying in size, programming language, and complexity. The dataset’s breadth allows for a nuanced understanding of agent capabilities, identifying patterns in successful contributions and pinpointing areas where performance lags. Such granular data is essential for guiding future development of AI coding tools and establishing realistic expectations for their integration into professional software engineering workflows, ultimately informing strategies for maximizing their potential and addressing existing limitations.
Categorizing the Work of Automation
The categorization of pull request (PR) contributions was achieved through a mixed-methods approach utilizing GPT-5 and open-card sorting. Initially, GPT-5 was used to generate a broad set of potential PR categories based on analysis of a large corpus of code contributions. These were then refined and validated through open-card sorting, where human participants grouped and labeled PR descriptions according to their perceived task type. This iterative process resulted in the identification of 13 distinct categories that represent both the addition of new functionality (functional tasks) and improvements to existing code without altering its core behavior (non-functional tasks), such as bug fixes, performance optimizations, and documentation updates.
The resulting categorization scheme identifies thirteen distinct types of pull request contributions, extending beyond simple feature additions to encompass a comprehensive range of development tasks. These categories include, but are not limited to, new feature implementation, bug fixes, performance optimization, code refactoring, security enhancements, test creation and modification, documentation updates, dependency upgrades, configuration changes, build system modifications, and infrastructure adjustments. This granular approach allows for a more detailed analysis of contribution patterns and a more precise understanding of the diverse work undertaken within a software project, moving beyond broad classifications of “change” or “improvement”.
Inter-rater reliability of the pull request categorization scheme was quantitatively assessed using Cohen’s Kappa statistic. The resulting Kappa score of 0.877 indicates a strong level of agreement between independent raters, demonstrating the consistency and robustness of the categorization process. Generally, Kappa values above 0.80 are considered to represent excellent agreement, validating the scheme’s reliability for classifying diverse types of code contributions within the analyzed dataset. This high level of agreement minimizes the impact of subjective interpretation on the categorization results.
![Problem resolution time decreases across task groups, as demonstrated by the [log-scaled] trend of decreasing values indicating improved efficiency.](https://arxiv.org/html/2602.12144v1/x2.png)
Platform Performance and Agent Differentiation
Analysis of Pull Request (PR) acceptance rates and resolution times was conducted separately for the Android and iOS platforms to determine platform-specific performance characteristics. This comparative study revealed variations in how quickly PRs are accepted and resolved depending on the operating system. Data was collected and analyzed to identify trends and statistically significant differences in these metrics between the two platforms, providing insights into potential areas for optimization in the development process. The study considered both the acceptance rate-the percentage of PRs successfully merged-and the resolution time-the duration from PR creation to closure.
Analysis of pull request (PR) acceptance rates revealed a statistically significant disparity between the Android and iOS platforms. The Android platform demonstrated a 71.0% PR acceptance rate, exceeding the 63.7% rate observed on iOS. This indicates a greater proportion of submitted PRs are approved on Android compared to iOS, suggesting potential differences in code review processes, testing rigor, or the nature of contributions submitted for each platform. The observed difference warrants further investigation to determine the root causes and potential areas for improvement on the iOS platform to align with Android’s acceptance rate.
Analysis of pull request (PR) resolution times indicates a substantial performance difference for AI-authored PRs based on the platform. Specifically, AI-generated PRs were resolved 18 times faster on iOS devices compared to their resolution on Android devices. This disparity suggests platform-specific factors impacting the efficiency of AI-driven code integration, potentially related to testing infrastructure, build processes, or the nature of PRs generated for each operating system. Further investigation is required to pinpoint the root causes of this difference and optimize AI-assisted workflows across both platforms.
Statistical analysis using the Chi-Square Test and the Mann-Whitney U Test demonstrated statistically significant differences in pull request (PR) acceptance rates when comparing various agents and PR categories. The Chi-Square Test was employed to assess the relationship between categorical variables – specifically, agent and PR category – and PR acceptance, revealing associations beyond random chance. The Mann-Whitney U Test, a non-parametric test, was utilized to compare acceptance rates between two groups of PRs, further validating the observed differences. These tests confirm that PR acceptance is not uniform across all agents and categories, indicating performance variations warranting further investigation.
Analysis of pull request (PR) resolution times across both Android and iOS platforms demonstrates a substantial performance difference based on PR functionality. Functional PRs, those addressing core operational aspects, resolved at a significantly accelerated rate compared to non-functional PRs. Specifically, on Android, functional PRs resolved approximately 400 times faster than non-functional PRs. A similar, though less pronounced, acceleration was observed on iOS, where functional PRs resolved approximately 7 times faster than their non-functional counterparts. This disparity highlights the impact of PR scope on resolution efficiency across both platforms.
The Kruskal-Wallis test was employed to analyze resolution time disparities among multiple agents. This non-parametric test determined statistically significant differences in PR resolution efficiency between agents, indicating variations in individual performance. The test facilitated a comparative assessment without assuming a normal distribution of resolution times, which is crucial given the potential for outliers or skewed data. Results indicated that some agents consistently resolved PRs faster than others, suggesting opportunities for knowledge sharing or targeted training to improve overall team efficiency. The test’s output provided a ranked understanding of agent performance based on median resolution times, allowing for data-driven performance evaluations.
The Trajectory of Automated Contribution
The study reveals that AI coding agents are not uniformly skilled across all development tasks, displaying notable variations in proficiency depending on the category of work. This suggests a promising pathway toward specialization, where agents can be purposefully trained and deployed for specific tasks – such as localization, UI development, or bug fixes – to maximize efficiency and code acceptance rates. Rather than a single, general-purpose AI coder, the future of AI-assisted development may lie in a diverse ecosystem of specialized agents, each excelling in a defined area and contributing to a more streamlined and effective software creation process. This targeted approach could significantly improve the overall quality and speed of development cycles, and ultimately reduce the burden on human developers.
The study revealed a remarkable success rate for AI-generated pull requests focused on localization within the Android development environment, achieving a perfect 100% acceptance rate. This surpasses the performance observed across all other categories of proposed code changes, including user interface modifications and bug fixes. The complete acceptance of localization PRs suggests that the nature of this task – often involving well-defined translations and minimal code disruption – aligns particularly well with the current capabilities of AI coding agents. This finding indicates a promising avenue for leveraging AI to streamline the often-laborious process of software internationalization, potentially accelerating app deployment to global markets and reducing associated development costs.
Analysis of pull requests on the Android platform reveals a notable capacity for AI coding agents to successfully contribute user interface (UI) and bug fix modifications. Specifically, UI-related pull requests demonstrated an 88% acceptance rate, indicating a strong alignment between the agent’s proposed changes and the expectations of human developers. Furthermore, the agents achieved a 75% acceptance rate for fix pull requests, suggesting a reliable ability to identify and resolve common software defects. These high acceptance rates highlight the potential for AI to automate significant portions of routine Android development tasks, freeing developers to focus on more complex challenges and accelerate the overall development lifecycle. This proficiency in UI and fix contributions establishes a strong foundation for integrating AI agents into practical Android software engineering workflows.
The study reveals a crucial insight: an AI coding agent’s effectiveness isn’t universal, but deeply connected to the nuances of its operating environment. Performance varied considerably across development platforms, with Android localization pull requests demonstrating a 100% acceptance rate-a stark contrast to other categories. This suggests that the characteristics of each platform-its coding standards, review processes, and the nature of typical contributions-significantly influence how well an AI agent integrates and succeeds. Consequently, optimizing these agents necessitates a shift from generalized approaches to platform-specific tailoring, ensuring the agent’s behavior aligns with the unique demands and expectations of each development ecosystem for maximized contribution and acceptance rates.
This investigation establishes a crucial stepping stone toward significantly enhanced AI integration within software development lifecycles. By demonstrating quantifiable success – particularly with localized and user interface contributions on Android platforms – the research offers concrete evidence for the feasibility of automated code contributions. Future workflows can now be designed to strategically leverage AI agents, assigning tasks based on proven proficiencies and platform compatibility. Optimization efforts can focus on refining agent behavior within specific development environments, moving beyond generalized solutions to achieve higher acceptance rates and reduced human oversight. Ultimately, this work paves the way for a collaborative development paradigm where AI agents seamlessly contribute to real-world projects, boosting efficiency and accelerating innovation.
The study of AI-authored pull requests across Android and iOS platforms reveals a predictable pattern: systems, even those built on cutting-edge technology, are subject to the constraints of their environment. As Bertrand Russell observed, “The difficulty of modern analysis has been a consequence of men’s attempts to find a firm foundation for knowledge.” This mirrors the findings regarding pull request acceptance rates-Android’s greater variability suggests a less ‘firm foundation’ in its review processes compared to the more consistent iOS platform. While AI agents excel at routine coding tasks, their performance is inextricably linked to the underlying systems and human evaluations that determine acceptance, highlighting that every abstraction carries the weight of the past.
What’s Next?
The observed performance of AI coding agents, predictably, reveals a proficiency with patterned tasks. This isn’t innovation; it’s the efficient erosion of redundancy. Any improvement ages faster than expected, and the data suggests acceptance rates aren’t simply a measure of quality, but of familiarity – a preference for the predictable. The variability within the Android ecosystem, relative to iOS, isn’t necessarily indicative of a platform’s inherent complexity, but rather a wider range of tolerated deviations from established norms.
Future work must confront the limitations of pull request acceptance as a proxy for true integration. The system rewards convergence, not divergence. Examining the lifecycle of AI-authored code-its subsequent modifications, refactorings, and eventual obsolescence-will offer a more nuanced understanding of its long-term impact. Consider that rollback is a journey back along the arrow of time; the cost of reverting AI contributions may reveal hidden debts accrued during initial adoption.
Ultimately, the question isn’t whether these agents can write code, but whether they can gracefully accommodate the inevitable decay of any software system. The true test will be their ability to not simply automate existing practices, but to anticipate, and perhaps even mitigate, the entropic forces at play within a constantly evolving codebase.
Original article: https://arxiv.org/pdf/2602.12144.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-14 03:24