Author: Denis Avetisyan
A new framework enables robots to acquire complex manipulation skills simply by observing human videos, offering a low-cost path to advanced automation.
EasyMimic leverages visual alignment and action retargeting to facilitate cross-embodiment transfer, allowing robots to learn from readily available human demonstrations with improved data efficiency.
Despite advances in robot learning, acquiring large datasets for imitation remains a significant bottleneck, particularly for affordable home robots. This work introduces ‘EasyMimic: A Low-Cost Framework for Robot Imitation Learning from Human Videos’, a novel approach that enables robots to learn manipulation skills directly from readily available human video demonstrations. By extracting 3D hand trajectories, aligning actions to robot control space, and employing a user-friendly visual augmentation strategy, EasyMimic bridges the human-robot domain gap with minimal reliance on costly robot-specific data. Could this framework unlock more intuitive and accessible human-robot interaction in everyday environments?
Deconstructing the Robotic Embodiment Bottleneck
Robot learning, particularly when tasked with intricate manipulation, frequently encounters a substantial data bottleneck. Unlike humans who learn through extensive, unsupervised interaction with the world, robots typically require vast amounts of precisely labeled data – specifying desired actions for every conceivable situation. Gathering this data is not only time-consuming and expensive but also proves impractical for tasks with high variability. This limitation stems from the difficulty of generalizing learned behaviors to novel scenarios, as even slight deviations from the training data can lead to failure. Consequently, advancements in areas like grasping, assembly, and in-hand manipulation are significantly hampered by this scarcity of labeled examples, driving research toward methods that can leverage fewer, more efficiently utilized data points, or even learn from observation without explicit labeling.
A fundamental hurdle in teaching robots human-like manipulation skills lies in the significant differences between human and robotic anatomy – a challenge known as the ‘action space gap’. Human hands possess a remarkable 27 degrees of freedom, enabling intricate movements and adaptable grasping strategies, while most robotic grippers operate with far fewer, typically around 6 to 7. This discrepancy means a human demonstrator can effortlessly perform a task using nuanced finger movements, but directly translating those actions to a robot requires complex mappings and adaptations. Consequently, imitation learning algorithms struggle to effectively bridge this gap, often resulting in robotic movements that are jerky, inefficient, or simply fail to replicate the dexterity observed in human demonstrations. Researchers are actively exploring methods to overcome this limitation, including dimensionality reduction techniques, action primitives, and learning algorithms that can generalize across different kinematic structures.
Effective robotic manipulation hinges on a robot’s ability to accurately interpret visual information, yet a significant challenge arises from the stark difference in appearance between human hands and typical robotic grippers. Current vision systems, often trained on datasets featuring human hands, struggle to generalize to the geometries and textures of robotic end-effectors. This ‘visual appearance gap’ hinders a robot’s capacity to accurately map observed actions to appropriate grasping strategies, impacting both perception and control. Researchers are actively exploring techniques like domain adaptation and sim-to-real transfer learning to bridge this divide, allowing robots to recognize and replicate manipulations performed by humans despite the differences in physical form. Overcoming this gap is not merely an aesthetic concern; it directly impacts the robustness and adaptability of robots operating in human-centric environments, paving the way for more intuitive and collaborative interactions.
EasyMimic: A Framework for Efficient Replication
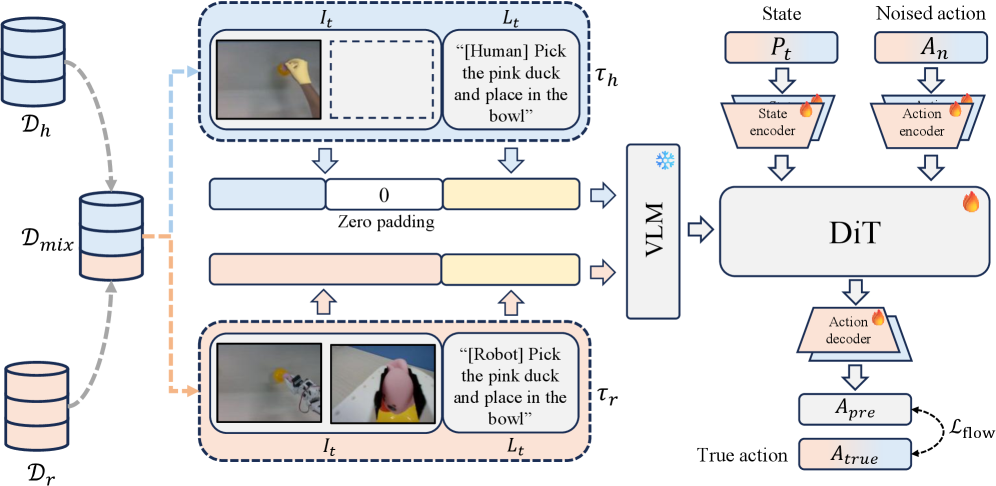
The EasyMimic framework mitigates the challenge of limited training data by strategically combining two data sources: human demonstration data and robot teleoperation data. Human demonstrations provide examples of desired task execution, while robot teleoperation data, gathered through human control of the robot, offers a broader range of robot states and actions. This combined dataset enables the framework to learn a mapping between human intentions and robot behaviors with increased efficiency, reducing the need for extensive, manually labeled datasets typically required for imitation learning. The utilization of both sources provides robustness and allows the system to generalize better to novel situations.
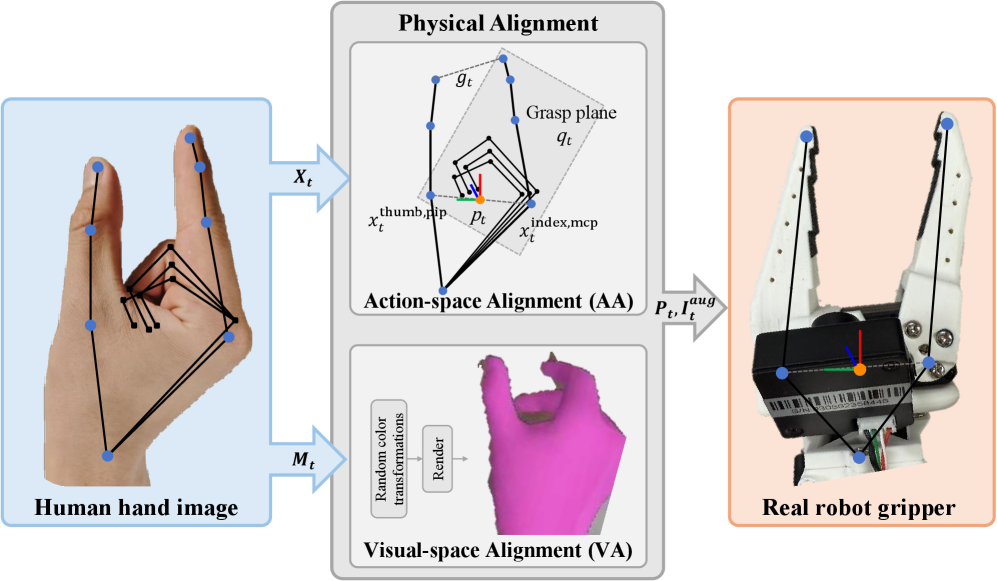
EasyMimic utilizes 3D hand pose estimation to capture human demonstration data, converting visual information into a quantifiable representation of hand movements. This data is then used in an action alignment process, which maps the estimated 3D hand poses to corresponding robot actions. Specifically, the system identifies key hand configurations during task execution and correlates these with the necessary joint movements of the LeRobot SO100-Plus. This alignment is crucial for translating human intent, as expressed through demonstration, into executable robot commands, forming the foundation for imitation learning within the framework.
To enhance the framework’s ability to generalize to new scenarios, EasyMimic incorporates visual augmentation during training. This process randomly alters the observed color of the human hand, mitigating the model’s reliance on specific visual textures and increasing robustness to variations in lighting and appearance. Concurrently, the HaMeR (Hand Articulation and Motion Representation) Model is employed to distill complex 3D hand pose data into a concise set of key features. These features focus on essential kinematic information, such as joint angles and fingertip positions, effectively reducing the dimensionality of the input data and improving the model’s capacity to learn transferable representations of hand movements.
The EasyMimic retargeting algorithm establishes a correspondence between human hand movements captured via 3D pose estimation and the control of the LeRobot SO100-Plus robotic hand. This is achieved by using the center of the thenar eminence – the fleshy mound at the base of the thumb – as a fixed anchor point during motion transfer. By consistently referencing this anatomical landmark, the algorithm minimizes positional drift and rotational errors when scaling and adapting human motions to the robot’s kinematic structure. This approach ensures that the robot replicates the intended actions with improved accuracy and stability, facilitating precise manipulation of objects within the robot’s workspace.
Evaluations of the EasyMimic framework demonstrate an average task success rate of 0.88 when applied to a suite of tabletop manipulation tasks. This performance metric represents a statistically significant improvement over existing baseline methods used for robotic imitation learning. The success rate was determined through repeated trials across diverse task scenarios, including object grasping, placement, and rearrangement. Comparative analysis confirms that EasyMimic consistently achieves higher completion rates and reduced error instances than alternative approaches, indicating its efficacy in translating human demonstrations to robotic actions.

Co-Training: Forging Robustness Through Iteration
The EasyMimic framework employs a co-training strategy to improve learning performance by integrating data from both human demonstrations and robot self-exploration. This approach leverages the strengths of both data sources: human demonstrations provide initial guidance and examples of successful task completion, while robot self-exploration allows the system to discover diverse experiences and refine its policy in environments not explicitly covered by the human data. By training on a combined dataset, the framework aims to enhance both the robustness and generalization capabilities of the learned policy, enabling it to perform reliably in a wider range of scenarios and with greater adaptability to unforeseen circumstances.
The EasyMimic framework employs absolute actions – specifically, 6-DoF end-effector poses and gripper states – to establish a unified action space for both human and robot data. This representation defines the desired position and orientation of the robot’s end-effector in Cartesian coordinates, alongside the state of the gripper (open or closed). By utilizing these absolute action values, the framework can directly compare and combine data collected from human demonstrations with robot-executed actions, facilitating the co-training process and enabling the transfer of knowledge between modalities without requiring complex mappings or relative motion interpretations.
The EasyMimic framework employs a diffusion transformer (DiT) architecture as its central policy network. This DiT is initialized and built upon the Gr00T N1.5-3B Vision-Language-Action (VLA) model, leveraging its pre-trained capabilities in understanding and generating action sequences. The Gr00T N1.5-3B model provides a strong foundation for robotic manipulation tasks, and the DiT further refines this through a diffusion-based approach to policy learning. This allows the framework to generate diverse and robust action plans by modeling the distribution of successful trajectories, ultimately improving performance in complex manipulation scenarios.
Evaluations demonstrate that the EasyMimic co-training strategy achieves a 0.13 point improvement in task success rate when compared to a traditional Pretrain-Finetune approach. This performance gain indicates the effectiveness of combining data from both human demonstrations and robot interactions during the learning process. The observed difference in task success rate quantitatively validates the benefits of co-training as a method for enhancing robot learning capabilities and improving overall task performance.
Employing independent action heads within the EasyMimic framework yields a 0.40 point improvement in task success rate when contrasted with a single, shared action head. This architecture allocates separate output layers for predicting actions, allowing the model to learn modality-specific action distributions without imposing constraints from the opposing data source. The performance gain indicates that direct sharing of action predictions can hinder learning, and that maintaining independent representations for each modality – human demonstrations and robot data – enhances the model’s ability to generalize and execute tasks effectively.
Visual alignment within the EasyMimic framework demonstrably improves robotic task performance. Quantitative analysis indicates a 0.47 point increase in task success rate when visual alignment is incorporated into the learning process. This alignment facilitates a more effective transfer of knowledge between human demonstrations and robot execution by establishing a correspondence between visual inputs and desired actions. The methodology used to achieve this alignment allows the system to better interpret the relationship between observed scenes and the appropriate robotic movements, ultimately leading to a statistically significant improvement in task completion.
Action alignment within the EasyMimic framework contributes a 0.27 point improvement in task success rate. This process involves ensuring consistency between the robot’s actions, represented as 6-DoF end-effector poses and gripper states, and the corresponding actions observed in human demonstrations. By explicitly aligning these action spaces during the co-training process-combining data from both modalities-the diffusion transformer (DiT) policy network can more effectively learn a shared representation of successful task execution. This alignment facilitates knowledge transfer between the human and robot datasets, resulting in improved generalization and robustness of the learned policy.
Beyond Replication: Toward Embodied Intelligence
EasyMimic signifies a notable advancement in the pursuit of embodied intelligence, a crucial capability for robots operating effectively in unpredictable, real-world environments. Traditional robotic manipulation often relies on painstakingly programmed sequences or extensive datasets for each new task, limiting adaptability and increasing development costs. This framework, however, prioritizes learning from limited demonstrations – even imperfect ones – allowing robots to quickly acquire the nuanced motor skills needed for complex actions. By bridging the gap between simple commands and sophisticated performance, EasyMimic doesn’t just enable robots to perform tasks, but to understand and generalize those abilities, representing a crucial step towards truly intelligent, adaptable robotic systems capable of seamlessly interacting with the physical world.
Traditional robotic manipulation systems often demand extensive, task-specific programming and substantial computational resources, creating a significant hurdle for researchers and developers. EasyMimic addresses these limitations through a novel approach that prioritizes learning from limited demonstration data and efficient imitation. This framework substantially lowers the barrier to entry by reducing the need for painstakingly crafted code or powerful hardware; instead, it enables robots to acquire new skills with minimal examples. Consequently, a broader range of individuals and organizations can now explore and implement robotic solutions, accelerating innovation in fields like automated assembly, personalized healthcare, and assistive technologies for the elderly or disabled – ultimately democratizing access to advanced robotic capabilities.
The potential of EasyMimic extends significantly due to its design for efficient data use and broad applicability; unlike systems requiring vast datasets for each new task, this framework generalizes learned skills across diverse scenarios. This characteristic makes it uniquely suited for deployment in dynamic environments like modern manufacturing, where robots must adapt to variations in parts and processes with minimal retraining. Similarly, in healthcare settings – assisting with surgery or patient care – the ability to generalize from limited demonstrations is crucial for safe and reliable operation. Perhaps most promisingly, EasyMimic offers a pathway toward truly versatile assistive robotics, enabling robots to learn and perform personalized tasks for individuals with varying needs, ultimately broadening access to robotic assistance and improving quality of life.
The progression of EasyMimic is not envisioned as a finished product, but rather as a foundational step towards increasingly sophisticated robotic capabilities. Current research endeavors are centered on expanding the framework’s reach to encompass more intricate tasks – moving beyond simple demonstrations to tackle multifaceted, real-world challenges. Crucially, this scaling process is intrinsically linked to the integration of advanced perception and planning algorithms; enabling robots not only to replicate movements, but to understand their environment and proactively strategize solutions. This synergistic approach promises to unlock a new era of robotic autonomy, where machines can adapt to unforeseen circumstances and perform tasks with a level of dexterity and intelligence previously unattainable.
The pursuit of robotic imitation, as demonstrated by EasyMimic, isn’t merely about replicating actions; it’s about deciphering the underlying principles governing those actions. This framework, by focusing on visual and action alignment, actively tests the boundaries of cross-embodiment transfer. One might recall the words of Henri Poincaré: “Mathematics is the art of giving reasons.” EasyMimic embodies this sentiment – it doesn’t simply show a robot what to do, but provides a reasoned pathway, a mathematical bridge if you will, from human demonstration to robotic execution. The system’s data efficiency stems from this rigorous analysis, effectively reverse-engineering human skill and translating it into a language the robot understands, revealing the fundamental rules governing manipulation.
Beyond Mimicry
The promise of EasyMimic – and indeed, much of imitation learning – rests on a subtle, often unacknowledged assumption: that skillful execution is simply accurate reproduction. This framework, by focusing on visual and action alignment, sidesteps the deeper question of why a particular action achieves a desired outcome. Future work should not merely refine the alignment algorithms, but actively probe the limits of purely mimetic learning. What happens when the environment deviates from the demonstration? Does the system generalize, or merely offer increasingly convincing, yet ultimately futile, reproductions of failure?
The current emphasis on data efficiency is laudable, given the scarcity of labeled robotic data. However, true robustness may require a shift in focus – from acquiring more demonstrations, to building systems capable of actively questioning them. A truly intelligent system wouldn’t simply mirror human action; it would analyze, critique, and, when necessary, improve upon it. The ultimate test isn’t whether a robot can copy a human, but whether it can surpass them, even if that means breaking the established pattern.
One can anticipate further development of cross-embodiment transfer, but this inevitably raises the question of embodiment itself. Is the goal to create robots that perfectly simulate human dexterity, or to discover entirely new forms of robotic manipulation, unconstrained by the limitations of the human form? The path toward general-purpose robotics may lie not in mimicking what has already been solved, but in embracing the unexplored possibilities of a fundamentally different architecture.
Original article: https://arxiv.org/pdf/2602.11464.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-13 17:08