Author: Denis Avetisyan
Researchers can now leverage a new multi-agent system that uses natural language to simplify and accelerate the complex process of causal inference.
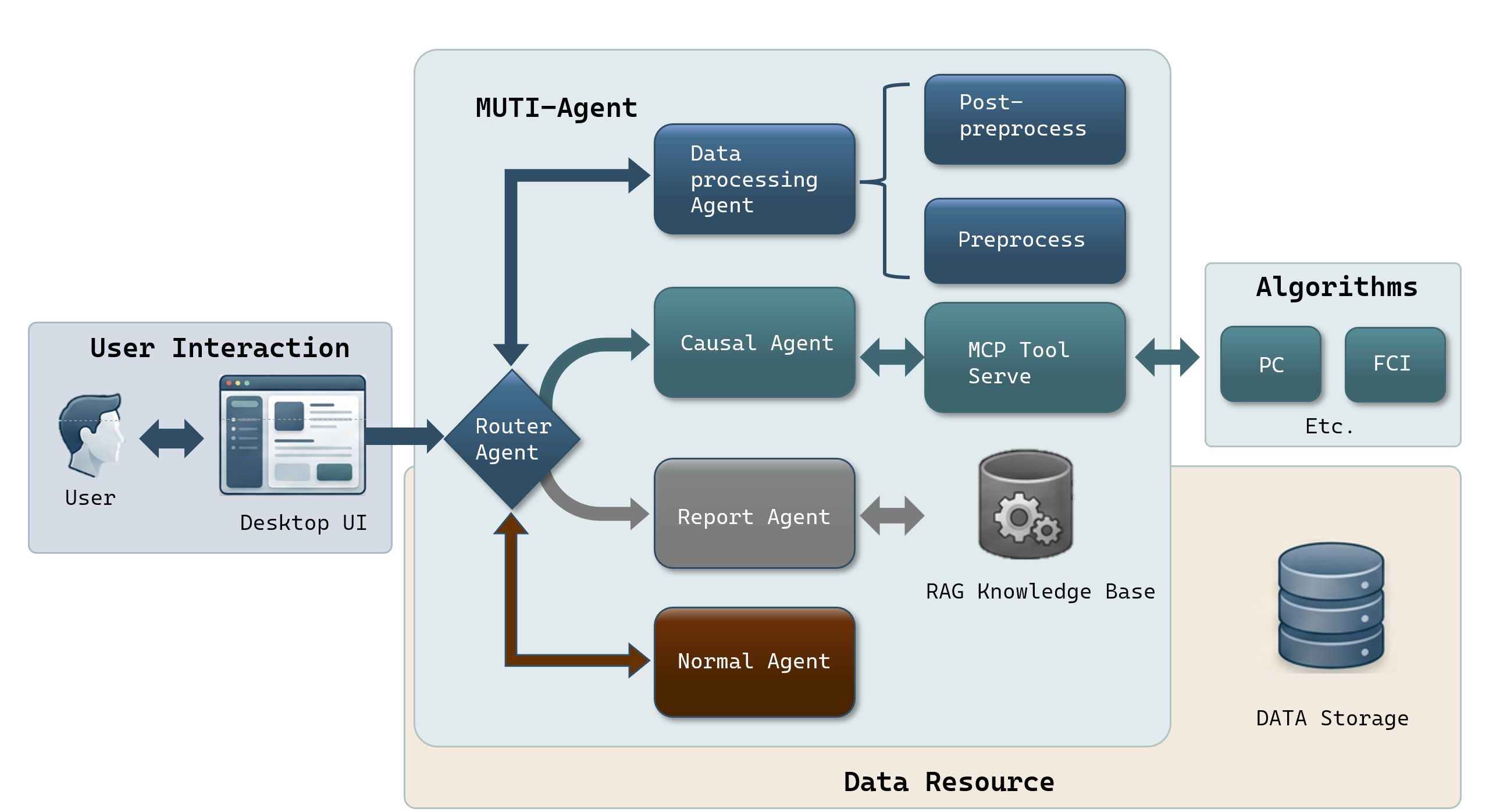
This work introduces CausalAgent, a system integrating large language models, retrieval-augmented generation, and causal algorithms for interactive data analysis.
Despite the immense potential of causal inference across disciplines, its practical application remains hindered by significant technical expertise required for data processing, algorithm selection, and result interpretation. To address this barrier, we present ‘CausalAgent: A Conversational Multi-Agent System for End-to-End Causal Inference’, a novel system that automates the entire causal analysis pipeline through natural language interaction. By integrating multi-agent systems, retrieval-augmented generation, and the Model Context Protocol, CausalAgent streamlines workflows from data cleaning to report generation, lowering the barrier to entry for researchers. Could this user-centered, interactive approach redefine how causal relationships are discovered and applied across diverse fields?
Beyond Correlation: The Imperative of Causal Understanding
Conventional statistical analyses often falter when applied to the intricacies of real-world systems. These methods frequently rely on assumptions of linearity and independence, which rarely hold true in complex scenarios involving numerous interacting variables. A significant limitation arises from the presence of unobserved confounders – hidden factors influencing both the presumed cause and effect – that distort the apparent relationship between them. Consequently, correlations identified through traditional statistics may not reflect genuine causal links, leading to inaccurate conclusions and potentially flawed decision-making. The inability to account for these hidden variables and systemic complexities underscores the need for more sophisticated approaches to discerning cause and effect, particularly when dealing with observational data where controlled experiments are impractical or unethical.
Despite their remarkable ability to identify correlations within vast datasets, large language models currently fall short of genuine causal understanding. These models thrive on recognizing patterns – predicting the next word in a sequence or classifying images – but this proficiency doesn’t equate to discerning why something happens. A model might accurately predict that ice cream sales increase with crime rates, but it cannot independently deduce that neither is caused by the other – a third, unobserved variable like warm weather is the true driver. True causal inference demands more than pattern recognition; it requires the ability to formulate and test hypotheses, consider counterfactuals – “what if?” scenarios – and reason about interventions, capabilities that remain a significant challenge for even the most advanced artificial intelligence systems. This limitation underscores the critical need for developing new methodologies that imbue AI with robust reasoning skills, moving beyond correlation to establish genuine causal links.
CausalAgent: A System for Distributed Inference
CausalAgent utilizes a Multi-Agent System (MAS) architecture where distinct agents, each with specialized functions, work in concert to perform causal inference. This approach moves beyond monolithic systems by distributing the analytical workload. Agents are designed to handle specific sub-tasks within the causal analysis pipeline, such as hypothesis generation, evidence retrieval, confounder identification, and effect estimation. Communication and coordination between these agents are managed by a central orchestrator, enabling a collaborative workflow and facilitating the decomposition of complex causal problems into manageable components. The MAS architecture enhances both the flexibility and scalability of the system, allowing for the easy addition of new analytical capabilities or adaptation to different data types and causal structures.
The Model Context Protocol within CausalAgent establishes a clear separation between the reasoning process and the actual execution of tasks. This decoupling is achieved by defining a standardized interface for agents to exchange contextual information – specifically, the reasoning steps, intermediate results, and required data – without dictating how those steps are performed. This design promotes modularity by allowing individual agents to be swapped or updated without impacting the overall system, and enables scalability as components can be distributed across different computational resources. The protocol facilitates parallel processing and allows for the independent optimization of reasoning and execution pipelines, improving both performance and maintainability.
CausalAgent utilizes the GLM-4.6 large language model as its core reasoning engine. This LLM is employed not as a monolithic processor, but as the basis for multiple specialized agents within the system. Task distribution is achieved by assigning specific sub-problems of the causal inference process to individual agents, each powered by GLM-4.6. Conflict resolution between agents, which can arise from differing interpretations or proposed solutions, is managed through a consensus mechanism also driven by GLM-4.6, evaluating agent outputs and selecting the most coherent and logically sound approach based on pre-defined criteria and the overall causal graph construction.
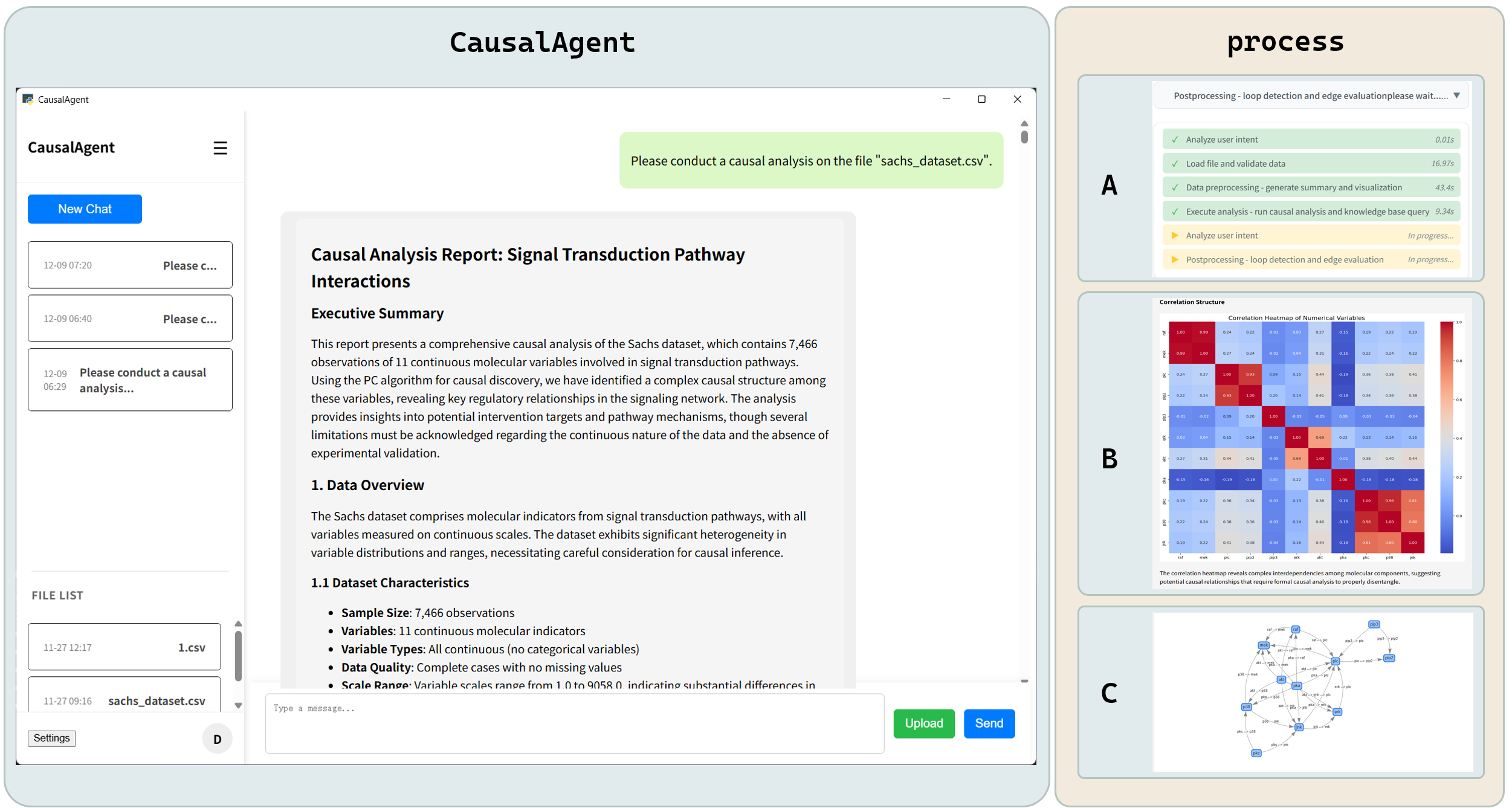
From Data to Structure: Deconstructing the Causal Analysis Pipeline
The Data Processing Agent is the initial component of the causal analysis pipeline, responsible for preparing raw input data for subsequent stages. This preprocessing includes standard quality checks such as handling missing values, outlier detection, and data type validation. Critically, the agent also assesses the data for compliance with the Directed Acyclic Graph (DAG) assumption – a prerequisite for many causal inference methods. Specifically, it tests for the presence of confounding cycles or feedback loops which would invalidate the application of algorithms like the PC Algorithm. Violations of the DAG assumption are flagged, preventing potentially erroneous causal conclusions and prompting data re-evaluation or the application of alternative modeling techniques.
The Causal Structure Learning Agent identifies causal relationships within data utilizing algorithms such as the PC Algorithm, a constraint-based method that tests for conditional independence to establish a partial directed acyclic graph. To address the issue of unobserved variables – termed latent confounders – the agent implements algorithms based on the Operator Learning Causal (OLC) framework. OLC-based algorithms estimate the effects of latent confounders by leveraging functional relationships observed in the data, allowing for more robust causal inference even in the presence of unmeasured variables that could otherwise bias results. These methods effectively search the space of possible causal structures, accounting for both observed and unobserved influences to generate a plausible causal model.
CausalAgent incorporates Retrieval-Augmented Generation (RAG) to improve the fidelity and trustworthiness of its causal explanations. This process involves retrieving relevant passages from a knowledge base of established causal theory – encompassing concepts like confounding, mediation, and causal sufficiency – and using this retrieved information to contextualize and validate the generated explanations. By grounding its outputs in documented causal principles, RAG minimizes the risk of hallucination and ensures that the reasoning presented aligns with accepted scientific understanding, thereby increasing the reliability and interpretability of the causal analysis results.
Supervised Fine-Tuning (SFT) is employed to optimize CausalAgent’s performance following initial model training. This process utilizes a curated dataset of instruction-response pairs specifically designed to enhance both the model’s ability to accurately interpret user instructions and the precision of its generated outputs. The SFT process adjusts the model’s weights based on the error between its predicted responses and the provided ground truth, iteratively improving its alignment with desired behavior. Datasets are constructed to cover a wide range of causal reasoning tasks and instruction styles, ensuring robustness and generalization capability. Quantitative metrics, such as accuracy and instruction-following rate, are used to monitor and validate the effectiveness of the fine-tuning process.
Beyond Validation: Realizing the Impact of Causal Discovery
Rigorous testing of CausalAgent utilized the well-established Sachs Protein Signaling Dataset, a benchmark in causal discovery research. This dataset, comprising measurements of ten proteins involved in cellular signaling, presented a complex network of potential interactions. The agent successfully reconstructed a substantial portion of the known causal relationships within this network, demonstrating its capacity to move beyond simple correlation and identify true drivers of biological processes. This validation, against a dataset frequently used to evaluate causal inference methods, provides strong evidence for the agent’s reliability and accuracy in discerning cause-and-effect relationships – a crucial step toward applying this technology to more complex systems and real-world challenges.
The system culminates in a detailed report generated by the Reporting Agent, which doesn’t merely present the discovered causal relationships, but contextualizes them with crucial diagnostic metrics. This synthesis provides a holistic view of the inference process, detailing the confidence levels associated with each causal link and highlighting the data supporting those conclusions. The resulting report is designed for accessibility, translating complex computational findings into an interpretable format suitable for experts and non-experts alike. By combining structural insights with quantifiable assessments, the Reporting Agent ensures that the system’s outputs are not only insightful, but also rigorously documented and readily understandable – facilitating effective communication of causal discoveries across diverse fields.
The system’s capacity to discern causal relationships hinges on meticulously crafted prompts that guide interactions between its agents and external tools. This ‘prompt engineering’ isn’t simply about asking questions; it involves strategically designing instructions that elicit precise responses and leverage the strengths of each tool. By carefully phrasing requests and specifying desired output formats, the system minimizes ambiguity and maximizes the quality of information retrieved, leading to more accurate causal inferences. This iterative process of prompt refinement ensures that the agents effectively collaborate, accessing and interpreting data in a manner that directly supports the identification of meaningful causal links – a crucial factor in achieving robust and reliable results.
The capacity to discern causal relationships extends far beyond theoretical inquiry, offering transformative potential across diverse sectors. In healthcare, identifying the true drivers of disease-distinguishing correlation from causation-promises more effective treatments and preventative strategies, moving beyond symptom management to address root causes. Similarly, within policy making, a robust understanding of causal links allows for the design of interventions that are not merely reactive, but proactively address the underlying factors influencing societal challenges, such as economic inequality or public health crises. This capability transcends simple prediction; it enables targeted, evidence-based decisions with a higher probability of achieving desired outcomes, fostering greater accountability and optimizing resource allocation in complex systems. Ultimately, a system capable of reliably uncovering causal connections empowers stakeholders to move beyond observing what happens, to understanding why it happens, and leveraging that knowledge for positive change.
The pursuit of causal inference, as demonstrated by CausalAgent, benefits greatly from a reductionist approach. The system’s architecture, integrating Large Language Models with Retrieval-Augmented Generation and established causal algorithms, isn’t about adding complexity, but about distilling the process into manageable, interactive components. This aligns with the sentiment expressed by Claude Shannon: “The most important thing is to get the message across.” CausalAgent effectively delivers that message-causal understanding-by removing barriers to entry and emphasizing clear communication between data, algorithms, and the researcher. It’s a testament to the power of simplicity in tackling intricate analytical challenges.
Further Directions
The automation of causal inference, as demonstrated, shifts the central difficulty. It is no longer the mechanics of estimation, but the framing of the question. Systems like CausalAgent offer a compelling interface, yet remain dependent on the user’s prior understanding of the domain, and the biases embedded within the retrieved data. Reducing this dependency requires a more rigorous treatment of uncertainty – not simply in the estimates themselves, but in the very definition of the causal graph.
Future work must address the problem of ‘garbage in, plausible conclusions.’ Sophisticated algorithms cannot rescue flawed assumptions. The focus should turn to methods for validating the user’s initial causal hypotheses, perhaps through automated sensitivity analysis or the generation of counterfactual scenarios that actively test the model’s limits. A system that highlights what it doesn’t know may prove more valuable than one that confidently asserts a spurious relationship.
Ultimately, the true measure of progress will not be in the complexity of the agents, but in their restraint. The goal is not to replicate human intuition, but to externalize the logical steps, making the process transparent, and, ideally, revealing the places where intuition fails. The pursuit of causal knowledge is, after all, a process of controlled subtraction.
Original article: https://arxiv.org/pdf/2602.11527.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-13 13:40