Author: Denis Avetisyan
New research demonstrates a method for robots to learn complex tasks from limited human demonstrations by focusing on predicting 3D scene flow and leveraging cropped point cloud data.
This work introduces a flow-based approach to few-shot imitation learning, enabling robust generalization in robot manipulation across varied environments and even to different robot embodiments.
Collecting sufficient robot demonstration data remains a key bottleneck in imitation learning, despite its promise for skill acquisition without explicit task modeling. This challenge motivates the work presented in ‘Flow-Enabled Generalization to Human Demonstrations in Few-Shot Imitation Learning’, which investigates leveraging predicted 3D scene flow to enable robots to learn from fewer, and even human, demonstrations. The authors introduce a novel approach that combines scene flow prediction with cropped point cloud processing to achieve robust generalization to new tasks and environments. Could this method unlock a new era of robot learning where skills are readily transferred from human expertise, even with limited robotic experience?
Bridging the Gap: The Challenge of Cross-Embodiment
Conventional imitation learning techniques, such as behavior cloning, frequently encounter difficulties when attempting to transfer learned policies between markedly different physical systems or sensory modalities. These methods typically rely on directly mapping observed states to actions, a process that proves brittle when the observing and imitating agents possess dissimilar morphologies or perceptual capabilities. For instance, a robot with six legs and infrared vision will interpret and execute a human demonstration – captured via video and intended for a two-legged creature – with limited success. The core issue isn’t simply a difference in scale or speed, but a fundamental mismatch in the state spaces; what constitutes a relevant observation or a feasible action for one agent may be entirely meaningless to another, hindering the robot’s ability to generalize learned behaviors beyond the specific conditions of the original demonstration.
Attempts to directly translate human movements captured in video into robotic actions frequently encounter significant obstacles stemming from fundamental differences in physical structure and sensory input. Robotic systems, unlike humans, possess distinct kinematic chains – the arrangement of rigid bodies and joints – limiting their ability to replicate complex human gestures without modification. Furthermore, robots rely on sensors that operate within different perceptual ranges and modalities than human vision; what appears as a simple visual task for a person might require extensive processing and interpretation for a robot. This disparity in both mechanical capabilities and perceptual frameworks necessitates a robust approach to transfer learning, one that accounts for these inherent discrepancies to achieve successful imitation and adaptation of demonstrated behaviors.
The successful transfer of learned behaviors between agents-be they human, robot, or simulated-hinges on a shared understanding of not just what action is being performed, but also why and where. Disparate agents often interpret the same visual input or sensor data differently due to variations in morphology, perceptual systems, and prior experiences. This creates a fundamental challenge in cross-modality learning, where a robot attempting to mimic a human demonstrator, for instance, must bridge the gap in contextual awareness. Without a common framework for interpreting motion within a scene-understanding object affordances, spatial relationships, and intended goals-direct replication of actions will inevitably fail. Establishing this shared understanding requires methods that go beyond simple observation, potentially incorporating mechanisms for inferring underlying intentions, predicting future states, and representing the environment in a way that is meaningful to both agents.

Scene Flow Prediction: A Foundation for Generalization
The Scene Flow Completion and Regression (SFCr) model generates predicted 3D trajectories for any point within a defined scene, providing a continuous depiction of motion. This differs from agent-centric approaches by decoupling motion prediction from the specific characteristics of the demonstrating agent; the model focuses solely on the scene’s dynamic elements. Consequently, SFCr can extrapolate movement patterns for arbitrary points, even those not directly involved in the initial demonstration, and accurately represent the overall flow of motion within the environment. This agent-agnostic approach enhances generalization capabilities and allows for prediction across varied scenarios and agent behaviors.
The Scene Flow Prediction model employs a Transformer architecture to model complex inter-point relationships within a 3D scene, facilitating accurate prediction of future states. This architecture processes point cloud data, representing the scene as a set of discrete points in space, allowing the model to reason about spatial arrangements and dynamics. The Transformer’s attention mechanism enables the model to weigh the importance of different points when predicting the future location of a given point, capturing long-range dependencies and nuanced interactions. This approach differs from recurrent models, which process data sequentially, and allows for parallel computation and more effective modeling of complex, multi-object scenes.
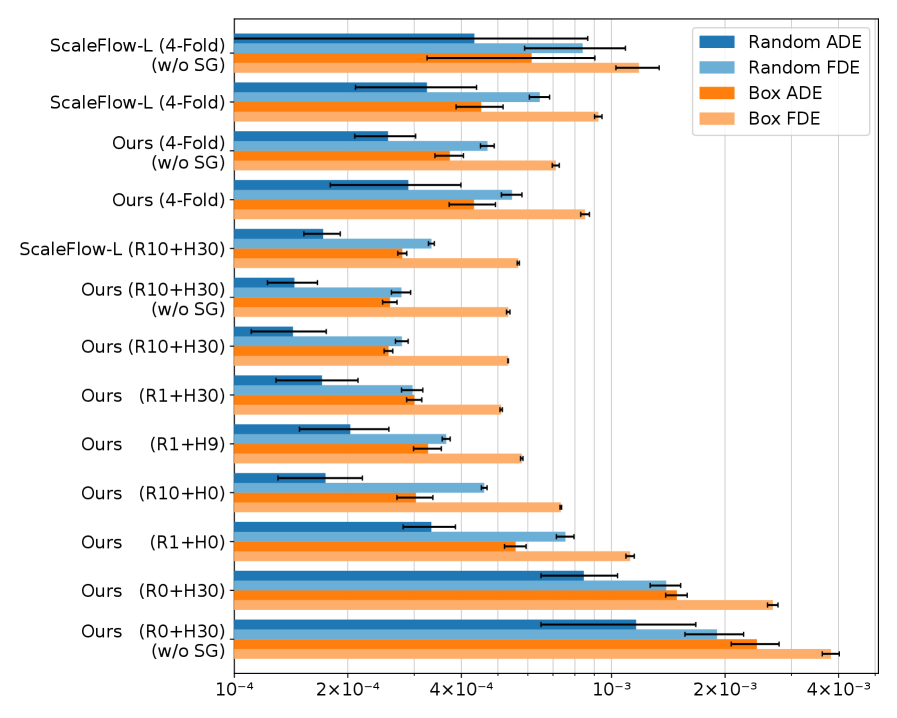
Quantitative evaluation demonstrates the superior performance of our flow prediction model, as measured by Average Displacement Error (ADE) and Final Displacement Error (FDE). Specifically, our model achieves lower ADE and FDE values than the ScaleFlow-L baseline in both the complete dataset and a 4-fold cross-validation setting. This consistent reduction in error metrics across different evaluation configurations indicates a more accurate and robust prediction of scene flow compared to the referenced model, suggesting improved generalization capabilities and predictive accuracy in dynamic 3D environments.
Voxel Downsampling and Segmentation Methods are integral to processing the large data volumes inherent in 3D environments. Voxel Downsampling reduces computational load by representing 3D space as a discrete grid of voxels, decreasing the number of data points while preserving essential geometric information. Segmentation Methods then categorize these voxels, identifying distinct objects or regions within the scene. This allows the model to focus on relevant elements, improving both processing speed and the accuracy of motion prediction by providing a structured understanding of the 3D environment. The combination of these techniques facilitates efficient analysis of complex scenes and enables the SFCr model to scale to diverse and detailed environments.
Flow-Conditioned Policy: Direct Control Through Predicted Motion
The Flow-Conditioned Policy (FCrP) utilizes predicted flow and cropped point cloud data as input to directly generate robot actions. This approach enables spatial generalization, allowing the policy to perform tasks in previously unseen environments. Furthermore, the policy exhibits instance generalization, meaning it can manipulate novel objects without requiring specific training data for those instances. The input point clouds are locally cropped to focus on relevant regions, and these cropped representations, combined with the predicted flow field, are processed to infer the appropriate robotic manipulation. This direct mapping circumvents the need for complex intermediate representations and facilitates adaptation to varying conditions and object types.
The FCrP policy utilizes Data Augmentation and Local Cropping techniques to improve performance across varied environments and object configurations. Data Augmentation artificially expands the training dataset by applying transformations such as rotations, translations, and scaling to existing data, increasing the policy’s generalization ability. Local Cropping focuses the policy’s attention on relevant regions of the point cloud by extracting smaller, centered crops around objects of interest; this reduces computational load and improves robustness to clutter and partial observability. Combining these techniques allows the policy to adapt to previously unseen scenarios and maintain consistent performance despite variations in input data.
The Flow-Conditioned Policy (FCrP) utilizes predicted flow fields as input, enabling the robot to anticipate desired movements and react accordingly. This is coupled with PointNet-based feature extraction, specifically employing both DP3 and RISE networks to process cropped point cloud data. DP3 provides a differentiable processing pipeline for point clouds, while RISE facilitates robust instance segmentation, allowing the policy to identify and understand individual objects within the scene. By integrating these two modalities – predicted motion and semantic scene understanding – the FCrP effectively translates high-level human intentions, expressed through demonstrations, into precise robotic actions, minimizing the discrepancy between desired behavior and actual execution.
The Flow-Conditioned Policy (FCrP) demonstrates significant data efficiency in robotic task learning, achieving a 70% success rate after receiving only a single demonstration for each task. This performance metric indicates a substantial reduction in the amount of training data typically required for robotic control policies. The ability to generalize effectively from a single demonstration suggests the policy is capable of rapidly adapting to new scenarios and exhibiting robust performance with minimal human guidance. This level of data efficiency is critical for real-world applications where obtaining large datasets of robotic demonstrations is often impractical or costly.
Enhancing Perception: A Foundation for Robust Action
The SFCr model incorporates FastSam and AprilTag to enhance scene understanding and object tracking capabilities. FastSam, a segmentation algorithm, provides pixel-level classifications enabling the identification of objects within the environment. AprilTag, a fiducial marker system, delivers precise pose estimation for identified tags, providing ground truth data for calibration and localization. Integrating these techniques allows SFCr to move beyond basic point cloud processing, enabling it to recognize and track specific objects, and improving the overall accuracy and robustness of its perception system in dynamic environments. This is particularly useful for tasks requiring interaction with known objects or navigation within a defined space.
Max-Pooling, implemented within the DP3 model, serves as a downsampling method for point cloud data, reducing computational complexity while retaining salient features. This technique operates by partitioning the input point cloud into a set of non-overlapping sub-volumes and, for each sub-volume, outputting the maximum value within that region. By focusing on maximum activations, Max-Pooling effectively filters out noise and irrelevant details, resulting in a more robust and concise feature representation. This efficient feature extraction process contributes directly to improved perception quality, enabling the DP3 model to more accurately interpret and understand the surrounding environment despite potential data sparsity or noise.
Flow State Alignment is a refinement process applied to the learned policy within the robotic control system. It operates by evaluating the consistency between the actions dictated by the policy and the predicted future state of the system’s motion. Discrepancies between these are quantified, and a corrective signal is generated to adjust the policy, thereby encouraging actions that conform to the anticipated flow of movement. This alignment process minimizes jerky or unnatural behaviors, resulting in smoother trajectories and more realistic robotic motions by explicitly addressing the temporal consistency of actions.

Towards Adaptive and Intelligent Robotics
Recent advancements in robotics are shifting the focus from robots merely replicating demonstrated actions to systems capable of genuine adaptation. This progress hinges on techniques like cross-embodiment learning, where a robot learns from data collected across diverse physical forms, and flow-conditioned policies, which allow robots to dynamically adjust their behavior based on the current situation. Unlike traditional imitation learning, which struggles when faced with novel circumstances, these methods enable robots to generalize their skills to new tasks and environments. By understanding the underlying principles of movement and applying them flexibly, robots can navigate unpredictable scenarios and collaborate more effectively with humans, ultimately paving the way for more versatile and intelligent robotic assistants.
The development of this robotic framework promises a significant shift in how humans and robots interact, moving beyond pre-programmed sequences towards genuine collaboration. By enabling robots to understand and respond to nuanced human cues and adapt to changing circumstances, the technology paves the way for assistance in increasingly complex and unstructured environments. Imagine robotic partners capable of seamlessly integrating into daily life – assisting in healthcare, manufacturing, disaster relief, and even domestic tasks – all achieved through intuitive, natural interactions. This isn’t simply about automation; it’s about creating robotic teammates that augment human capabilities and enhance productivity across a diverse spectrum of applications, ultimately fostering a more synergistic relationship between people and machines.
Continued development centers on extending the current framework’s capabilities to address increasingly intricate real-world challenges. Researchers aim to move beyond controlled environments and demonstrate robust performance in dynamic, unpredictable settings, requiring solutions for improved sensor data interpretation and adaptable motion planning. Crucially, the integration of reinforcement learning algorithms is anticipated to dramatically enhance the robot’s capacity for autonomous skill acquisition and refinement. This synergistic approach-combining cross-embodiment learning with reinforcement learning-promises to unlock a new generation of robotic systems capable of not merely executing pre-programmed tasks, but of intelligently learning and improving their performance over time, ultimately paving the way for truly versatile and adaptive robotic collaborators.
The pursuit of robotic imitation, as detailed in this work, hinges on distilling complex human actions into a simplified, executable form. This echoes a sentiment articulated by John von Neumann: “It is possible to carry out any desired end-run around logic.” The researchers achieve this ‘end-run’ by focusing on predicted 3D scene flow – a deceptively simple representation of movement – to bridge the gap between human demonstration and robotic execution. By prioritizing the essential elements of motion over exhaustive data replication, the method mirrors the principle of reducing complexity to achieve clarity, enabling robust generalization across diverse environments and robotic platforms. The emphasis on cropped point clouds further exemplifies this commitment to paring down information to its core, functional components.
Future Directions
The presented work, while demonstrating proficiency in mapping observed demonstrations to robotic action, merely postpones the inevitable confrontation with inherent ambiguity. Predicting scene flow, however precise, is still a prediction – a statistical guess at the underlying causal structure. The capacity to extrapolate beyond the training manifold remains, fundamentally, a measure of luck, not understanding. Future iterations must address the limitations of relying solely on perceptual input; integration with symbolic reasoning, however cumbersome, may prove necessary to navigate genuinely novel scenarios.
The claim of ‘cross-embodiment’ generalization warrants scrutiny. The transfer of learned policies across robotic platforms is less a triumph of abstraction and more a consequence of shared kinematic constraints. A more rigorous test would involve adaptation to radically different morphologies – systems where the observed human demonstrations offer only metaphorical guidance. The pursuit of truly generalizable imitation learning necessitates a decoupling of skill from specific embodiment, a goal that currently appears asymptotic.
Ultimately, the value of this line of inquiry lies not in achieving perfect imitation, but in illuminating the complexity of action itself. The persistent difficulty in replicating even simple human behaviors serves as a constant reminder: emotion is a side effect of structure, and clarity is compassion for cognition. Further research should focus not on minimizing error, but on precisely characterizing the nature of the irreducible uncertainty.
Original article: https://arxiv.org/pdf/2602.10594.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-12 14:06