Author: Denis Avetisyan
A new framework empowers humanoid robots to perform intricate loco-manipulation tasks by learning directly from human demonstrations captured through egocentric vision.

EgoHumanoid aligns visual and action data from robot-free human demonstrations to bridge the embodiment gap and enable robust in-the-wild performance.
While robot learning has benefited from human demonstrations, scaling this approach to the complex task of humanoid loco-manipulation remains a significant challenge. This paper introduces EgoHumanoid: Unlocking In-the-Wild Loco-Manipulation with Robot-Free Egocentric Demonstration, a novel framework that co-trains human and robot data to enable humanoids to perform manipulation while navigating diverse real-world environments. By systematically aligning egocentric human vision and action spaces-addressing discrepancies in morphology and viewpoint-we demonstrate a [latex]51\%[/latex] performance gain over robot-only baselines, particularly in unseen scenarios. How can we further leverage the abundance of human data to unlock even more robust and adaptable humanoid robots?
The Illusion of Control: Bridging the Gap Between Simulation and Reality
Historically, robotic control systems have been painstakingly designed for highly structured environments. This approach demands precise knowledge of the surroundings and predictable interactions, effectively restricting a robot’s functionality to laboratory settings or pre-defined operational zones. Such systems often falter when confronted with the inherent messiness of the real world – uneven terrain, unexpected obstacles, or variations in object properties. The need for meticulous environmental control represents a significant bottleneck, hindering the broader deployment of robots in more practical, dynamic contexts like homes, warehouses, or disaster relief scenarios where adaptability, rather than precision in a static setting, is paramount. This reliance on engineered perfection ultimately limits a robot’s potential for true autonomy and robust performance.
A significant hurdle in robotics lies in the difficulty of translating skills acquired in simulated environments to the complexities of the physical world. While simulations offer a safe and cost-effective means of training robots, they often fail to accurately capture the subtle nuances of real-world physics – friction, imprecise movements, and unexpected contact forces. Consequently, a robot expertly navigating a virtual landscape may falter when confronted with even minor discrepancies in a physical setting. This “reality gap” manifests as jerky motions, failed grasps, and an inability to adapt to unforeseen circumstances, demanding researchers develop techniques that bridge the divide between perfect simulation and imperfect reality through robust adaptation and sensor integration.
The inability of robots to reliably perform tasks in ever-changing environments significantly restricts their practical application. Current robotic systems, while proficient in structured settings, often falter when confronted with the inherent unpredictability of the real world – think cluttered homes, busy warehouses, or disaster zones. This limitation stems from difficulties in coordinating locomotion and manipulation – the ability to move and interact with objects – in the face of unexpected obstacles, varying lighting conditions, or imprecise sensor data. Consequently, the deployment of robots capable of robust loco-manipulation – essential for tasks like search and rescue, in-home assistance, or flexible manufacturing – remains a considerable challenge, hindering progress towards truly autonomous and versatile robotic assistants.
The challenge of imbuing robots with truly adaptable behavior is increasingly addressed through the study of human demonstrations. Rather than relying on pre-programmed instructions or exhaustive simulations, researchers are exploring methods for robots to learn directly from observing human performance of a task. This ‘learning by demonstration’ approach involves capturing human motion and force data – effectively, a blueprint of skilled action – and translating it into control policies the robot can execute. By mirroring human strategies, robots can bypass the complexities of explicitly modeling the physical world, exhibiting more natural and intuitive movements. This paradigm shift holds particular promise for loco-manipulation – tasks requiring coordinated movement and object interaction – as it allows robots to generalize learned skills to novel situations and overcome the limitations of rigidly defined control schemes, paving the way for more versatile and robust robotic systems.
Echoes of Intent: Aligning Human and Robot Action
The EgoHumanoid framework resolves the disparity between human and robot action spaces by integrating data from two primary sources: egocentric human demonstrations and teleoperated robot control. Human demonstrations, captured from a first-person perspective, provide examples of desired task execution. These are then combined with teleoperated robot data, which represents actions directly controlled by a human operator on the robot. This fusion allows the system to learn a mapping between human intent, as expressed through demonstration, and the robot’s physical capabilities, effectively bridging the gap caused by differences in kinematic structures and operational limitations. The combined dataset facilitates the training of policies that can generalize human-level performance to the robot platform.
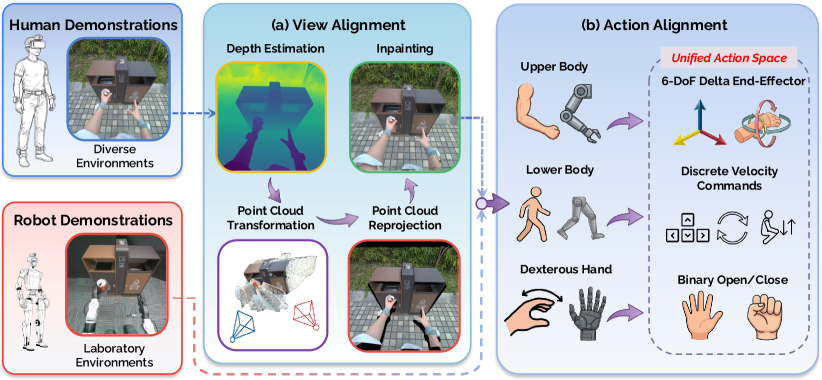
Action Alignment within the EgoHumanoid framework establishes a unified action space for both human and robot control by representing actions as changes in end-effector pose – specifically, delta positions and rotations – and discrete locomotion commands. This approach decouples actions from the specific kinematic structures of the human demonstrator and the robot, allowing for direct transfer of learned behaviors. Delta end-effector poses define movements relative to a starting point, simplifying the mapping between human and robot kinematics. Discrete locomotion commands, such as “walk forward” or “turn left”, provide a high-level control layer for navigating the environment, further bridging the gap between human instruction and robot execution. This standardized action representation facilitates the learning of robot policies from human demonstrations and teleoperation data.
Action data collected from human demonstrations and robot teleoperation is inherently noisy, potentially leading to unstable or erratic robot behavior. To address this, the EgoHumanoid framework employs smoothing techniques, prominently featuring the Savitzky-Golay filter. This digital filtering algorithm operates by fitting a polynomial to a sliding window of data points, effectively reducing high-frequency noise while preserving important signal features. The filter parameters, specifically the window length and polynomial order, are tuned to balance noise reduction with responsiveness. Applying the Savitzky-Golay filter to both end-effector pose data and discrete locomotion commands results in a more consistent and stable action stream, improving the overall robustness and reliability of the robot’s movements and enabling more accurate imitation of human actions.
Representing rotations using the [latex]SO(3)[/latex] Tangent Space offers advantages in robotic control by avoiding the complexities of representing rotations directly with Euler angles or quaternions. Directly manipulating [latex]SO(3)[/latex] elements can lead to gimbal lock and singularities, while the Tangent Space-a vector space approximation of [latex]SO(3)[/latex]-allows for the application of standard vector algebra for smooth and predictable movement. This representation simplifies calculations related to velocity and acceleration, improving the efficiency of control algorithms and reducing computational load. Furthermore, the Tangent Space avoids the need for normalization typically required when working with rotational representations, contributing to more stable and accurate control, particularly in high-dimensional robotic systems.
Reconstructing Perception: From Human Eye to Robot Vision
The View Alignment module addresses the inherent discrepancy between the visual perspective of a human demonstrator and the perception system of a robot. This misalignment arises because humans and robots typically operate with different sensor placements and orientations, resulting in differing fields of view and image projections of the same environment. Consequently, direct interpretation of human visual demonstrations by the robot is often impossible without first normalizing these viewpoint differences. The module functions as a preprocessing step, transforming human-captured images into a format more readily interpretable by the robot’s vision system, thereby enabling effective imitation learning and task execution.
The View Alignment module utilizes MoGe (Motion Geometry) to construct 3D point maps directly from egocentric images captured during human demonstrations. MoGe operates by analyzing the sequential frames of the egocentric video to estimate the 3D location of visible points in the environment. This process involves identifying feature points within each frame and then triangulating their positions using the known camera pose derived from visual odometry or other tracking methods. The resulting point map provides a sparse 3D representation of the demonstrated task environment, effectively bridging the gap between the 2D visual input and the robot’s need for spatial understanding. This allows the robot to interpret human actions within a reconstructed 3D space, regardless of initial viewpoint discrepancies.
Latent Diffusion Models (LDMs) are integrated into the reconstruction pipeline to address incomplete data and improve scene fidelity. These models operate in the latent space, enabling efficient and high-resolution image completion. Specifically, LDMs are utilized to inpaint occluded areas or regions lacking sufficient visual information in the 3D point maps derived from egocentric human images. This process effectively fills in missing geometric details and textures, resulting in more complete and visually coherent reconstructed scenes. The use of LDMs mitigates the impact of partial observations, improving the robustness and accuracy of the perception alignment process and contributing to a more detailed representation of the environment for robotic interpretation.
Accurate alignment of visual information is critical for robotic imitation learning, as it bridges the perceptual gap between human demonstrators and the robot’s sensor input. The framework achieves effective interpretation of demonstrations by transforming the human’s egocentric view into a robot-centric representation, enabling the robot to correlate observed actions with its own capabilities and workspace. This alignment process facilitates the robot’s ability to extract relevant features from the demonstration, such as object locations and trajectories, and subsequently reproduce the demonstrated task. Without this alignment, discrepancies in viewpoint and sensor characteristics would hinder the robot’s comprehension and successful execution of the learned behavior.

The Echo of Adaptation: Validating and Expanding the Framework’s Reach
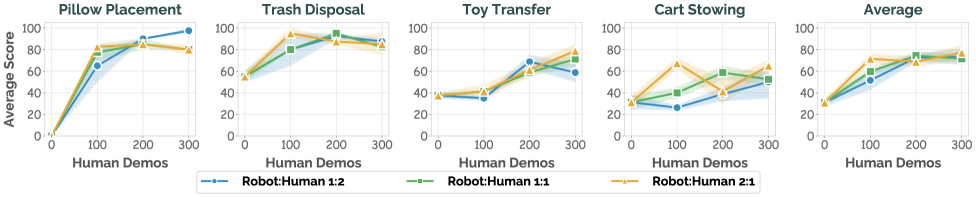
Rigorous evaluation confirms the framework’s robust performance across a spectrum of scenarios. The system underwent testing not only within the specific conditions of its training environment – termed ‘in-domain’ performance – but also in novel, unseen situations designed to assess its ability to generalize. This dual approach revealed substantial gains; the framework consistently outperformed methods relying solely on robot-derived data, demonstrating a significant capacity to adapt and maintain functionality even when confronted with unfamiliar challenges. This validation underscores the framework’s potential for real-world deployment, where environments are rarely static or perfectly predictable, and adaptability is paramount.
The EgoHumanoid framework facilitated the development of a VLA Policy demonstrably capable of executing intricate loco-manipulation tasks with significantly enhanced efficiency. Through the integration of human-derived data into the training process, the policy achieved an impressive overall performance increase of 51%. This substantial gain highlights the effectiveness of leveraging human expertise to guide robotic learning, enabling more fluid and successful navigation and object interaction. The resulting policy doesn’t simply mimic actions; it generalizes learned behaviors to accomplish complex tasks requiring both movement and precise manipulation, representing a considerable advancement in robot autonomy and dexterity.
Rigorous evaluation demonstrates a substantial performance increase when incorporating human data into the training process. Specifically, the framework achieved a 78% success rate in completing tasks within the training environment, a marked improvement over the 59% attained through robot-only training. More impressively, the system exhibited a significantly enhanced ability to generalize to unseen scenarios, reaching an 82% success rate-a leap from the 31% achieved when relying solely on robot-derived training data. These results highlight the considerable benefit of leveraging human demonstrations to accelerate learning and improve the robustness of robotic systems operating in complex, real-world environments.
The acquisition of training data crucial for the EgoHumanoid framework is streamlined through the utilization of the PICO VR System, offering a versatile platform for both human demonstration and remote robot operation. This system allows researchers to efficiently capture nuanced human movements as direct examples for the robot to learn from, and simultaneously enables teleoperation – where a human controls the robot remotely in a virtual environment. By integrating these two data collection methods, the framework benefits from a rich dataset encompassing both expert guidance and real-time adaptation, significantly boosting performance in complex loco-manipulation tasks. The immersive nature of the PICO VR system also contributes to the quality of the collected data, ensuring a high degree of fidelity between human intention and robot action.

The pursuit of embodied intelligence, as demonstrated by EgoHumanoid, inevitably reveals the limitations of prescriptive design. This framework doesn’t build a solution for loco-manipulation; it cultivates one from the messy, unpredictable data of human action. The alignment of vision and action, central to the system’s success, isn’t a matter of precise engineering, but of fostering a symbiotic relationship between data and robot. As Linus Torvalds once observed, “Talk is cheap. Show me the code.” EgoHumanoid delivers on that demand, not with a finished product, but with a functioning ecosystem capable of learning and adapting – a testament to the idea that robust systems aren’t constructed, they evolve.
What’s Next?
EgoHumanoid, in its attempt to bridge the embodiment gap, does not solve the problem of transferring skill. It merely delays it. The framework reveals, once again, that architecture is how one postpones chaos. Successful imitation learning isn’t about perfect alignment – vision to action, human to machine – but about building systems resilient enough to fail gracefully when inevitable misalignments occur. The current focus on VLA spaces, while yielding immediate gains, risks becoming another local optimum, a polished veneer over a fundamentally brittle core.
The true challenge lies not in teaching robots what humans do, but in enabling them to learn from the messy, unpredictable reality of existence – a reality where demonstrations are incomplete, environments are dynamic, and even the definition of ‘success’ is fluid. There are no best practices-only survivors. Future work must move beyond curated datasets and controlled environments, embracing the inherent ambiguity of the world.
One suspects that the pursuit of perfect imitation is a distraction. The interesting question isn’t how to replicate human skill, but how to unlock robot skill – to discover the unique capabilities that arise when a different embodiment interacts with the world. Order is just cache between two outages, and this framework, however elegant, is still built on sand.
Original article: https://arxiv.org/pdf/2602.10106.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-12 00:40