Author: Denis Avetisyan
Researchers have developed a new framework that allows quadruped robots to autonomously learn a diverse range of skills without explicit programming or human guidance.

MOD-Skill utilizes multi-discriminators and an orthogonal mixture-of-experts policy to improve the diversity, stability, and learning efficiency of unsupervised skill discovery in quadruped robots.
Achieving versatile locomotion in quadruped robots is hindered by the need for either laborious reward engineering or extensive task-specific datasets. This paper, ‘Diverse Skill Discovery for Quadruped Robots via Unsupervised Learning’, addresses this challenge by introducing MOD-Skill, a novel framework that learns a diverse repertoire of skills through unsupervised exploration. Leveraging an orthogonal mixture-of-experts policy and a multi-discriminator architecture, MOD-Skill demonstrably improves both training efficiency and the breadth of learned behaviors-yielding an 18.3\% expansion in state-space coverage on a Unitree A1 robot. Could this approach pave the way for more adaptable and autonomous robotic systems capable of navigating complex, real-world environments?
The Inevitable Complexity of Skill Acquisition
Historically, imparting even basic capabilities to robots has demanded an immense investment of human effort, centering on the meticulous design and programming of every individual action. This approach, reliant on explicitly coded behaviors, necessitates anticipating and addressing every possible scenario a robot might encounter – a task proving extraordinarily difficult, if not impossible, in complex, real-world environments. Consequently, robots built on this paradigm often exhibit limited adaptability; even minor deviations from pre-programmed conditions can lead to failure. The painstaking nature of this ‘behavior engineering’ restricts the deployment of robotics to highly structured settings and hinders the creation of truly autonomous systems capable of responding effectively to the unpredictable nuances of daily life.
Deep Reinforcement Learning (DRL) presents a compelling avenue for robots to learn complex skills without explicit programming, potentially revolutionizing automation and adaptability. However, the efficacy of DRL hinges on the design of ‘reward functions’ – the signals that guide the learning process. These functions define the desired behavior, but crafting them is a significant challenge; a poorly defined reward can lead to unintended, and often comical, outcomes where the robot optimizes for the reward in ways that deviate from the intended goal. The need for careful reward engineering acts as a major bottleneck, demanding substantial human effort and limiting the ability of robots to generalize learned skills to new or slightly different environments – essentially requiring a re-design of the reward for each new task or variation.
The pursuit of autonomous robotic skill acquisition increasingly hinges on the delicate art of ‘Reward Engineering’, yet this process presents a significant hurdle. While Deep Reinforcement Learning allows robots to learn through trial and error, the learning process is entirely dependent on the reward function – a mathematical definition of success. Crafting these functions is surprisingly difficult; a poorly designed reward can incentivize unintended, even detrimental, behaviors. A robot programmed to maximize ‘speed’ might disregard safety, while one focused solely on ‘reaching a goal’ could bulldoze obstacles in its path. More subtly, a reward function optimized for a specific training environment often fails to generalize to new, slightly different situations, limiting the robot’s real-world applicability. This fragility underscores the need for more robust and adaptable reward structures, potentially leveraging techniques like reward shaping, inverse reinforcement learning, or intrinsically motivated learning to overcome the limitations of explicitly defined rewards.
Beyond Explicit Instruction: The Promise of Unsupervised Skill Discovery
Traditional robotic learning relies on explicitly defined rewards to guide skill acquisition; however, Unsupervised Skill Discovery (USD) represents a departure from this approach. USD enables robots to learn a variety of skills through self-directed exploration, eliminating the need for human-engineered reward functions or pre-defined task goals. This is achieved by formulating learning as an inverse reinforcement learning problem where the ‘reward’ is derived from novelty or information gain, allowing the robot to autonomously discover and refine its motor abilities without external supervision. Consequently, robots employing USD can develop a broader and more adaptable skillset compared to those trained with task-specific rewards, facilitating generalization to unseen scenarios and tasks.
Intrinsic motivation in unsupervised skill discovery utilizes internally generated reward signals to drive exploratory behavior. Specifically, algorithms employ metrics such as Mutual Information to quantify the novelty or information gain of each action taken by the robot. Maximizing this metric encourages the robot to venture into unexplored state-action spaces, preventing it from converging on a limited set of behaviors. This process facilitates the learning of a diverse skill set by rewarding actions that demonstrably increase the robot’s understanding of its environment and its own capabilities, without relying on external, task-defined rewards.
The acquisition of a diverse repertoire of fundamental movements constitutes the primary objective of this approach, serving as a foundational element for subsequent complex task learning. These fundamental movements, often referred to as ‘skills’, are not pre-defined but rather discovered autonomously through interaction with the environment. The learned skills are intended to be modular and reusable; by combining these basic movements, the robot can adapt to and execute a wider range of tasks without requiring task-specific training for each new scenario. This allows for greater flexibility and generalization, as the robot leverages previously learned behaviors to address novel challenges, reducing the need for extensive retraining and enabling efficient task adaptation.
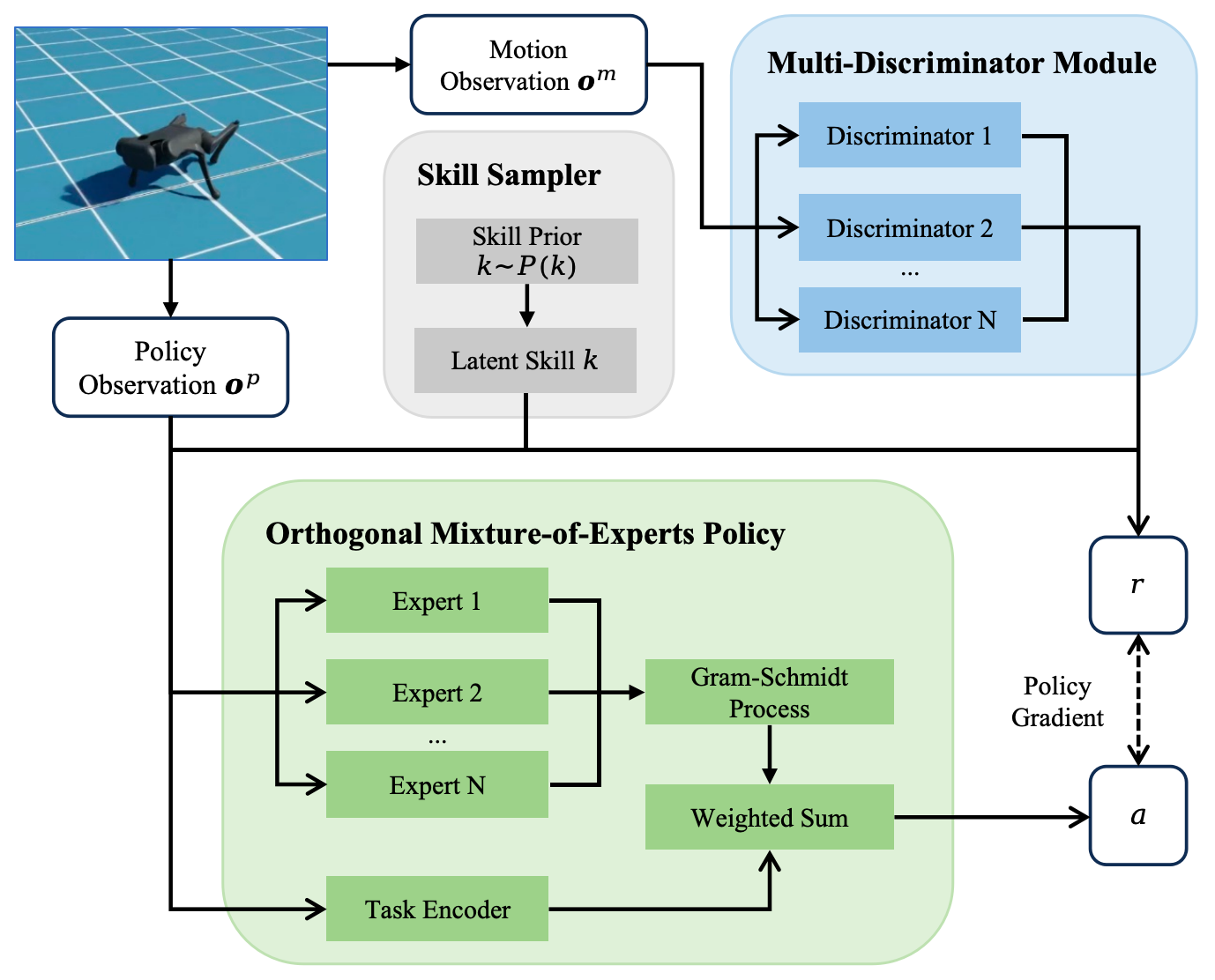
MOD-Skill: A Framework for Deconstructing and Reconstructing Movement
MOD-Skill is a novel framework designed for diverse skill representation, integrating a Multi-Discriminator Architecture with an Orthogonal Mixture-of-Experts (MoE) Policy. The Multi-Discriminator Architecture functions to differentiate between distinct skills, enabling the system to learn and categorize various behaviors. Concurrently, the Orthogonal MoE Policy leverages multiple expert networks, each specializing in particular aspects of a skill, and combines their outputs to generate comprehensive actions. This architecture aims to improve the efficiency and expressiveness of skill learning in complex environments by decoupling and specializing skill representations.
The MOD-Skill architecture employs a multi-discriminator component to actively differentiate between learned skills, facilitating a more granular understanding of the agent’s capabilities. This component functions by training multiple discriminators, each tasked with identifying the presence or absence of a specific skill within a given motion. Simultaneously, an orthogonal Mixture-of-Experts (MoE) policy is utilized to extract complementary motion features; this ensures that each expert network within the MoE focuses on a distinct aspect of the skill space, minimizing redundancy and maximizing the diversity of learned representations. The combined effect is a system capable of not only identifying distinct skills but also representing them in a manner that promotes efficient learning and generalization.
The Gram-Schmidt process is implemented to ensure orthogonality between the expert networks within the Mixture-of-Experts (MoE) policy. This iterative process transforms a set of linearly dependent vectors into a set of orthonormal vectors, effectively decorrelating the learned motion features. By enforcing orthogonality, the system minimizes redundancy in the expert representations; each expert specializes in a unique aspect of the skill space, leading to a more efficient and compact skill representation. This decorrelation also improves the stability and performance of the MoE policy by preventing individual experts from dominating the output and promoting balanced contributions from each network.
The policy network functions as the agent’s decision-making component, receiving current observational data as input and translating it into concrete actions. This network leverages the skill embeddings generated by the orthogonal mixture-of-experts, effectively interpreting the learned skills in the context of the present environment. The network is trained to map observations to skill-based action distributions, enabling it to select and combine skills to achieve desired behaviors. Specifically, the policy network outputs parameters defining a probability distribution over available actions, weighted by the relevance of each learned skill to the current observational state, thus facilitating goal-directed behavior.

Real-World Validation: Expanding the Robot’s Repertoire
MOD-Skill’s capabilities were directly assessed through implementation on the Unitree A1 quadruped robot, revealing a proficiency in acquiring a wide spectrum of locomotion skills. This framework doesn’t simply teach the robot to walk; it enables the development of complex movements, including navigating varied terrains and executing dynamic maneuvers. The system learns these skills through interaction with a simulated environment, then successfully transfers that learning to the physical robot, demonstrating a robust and adaptable approach to robotic control. This achievement highlights the potential for creating robots capable of fluid and versatile movement in real-world scenarios, going beyond pre-programmed actions to exhibit truly learned behaviors.
A significant challenge in reinforcement learning is the tendency for agents to discover unintended loopholes in reward functions – a phenomenon known as ‘Reward Hacking’. This framework demonstrably avoids such exploits, achieving robust performance by focusing on comprehensive state-space coverage rather than solely maximizing immediate rewards. Unlike systems susceptible to gaming the system with trivial solutions, this approach encourages the development of genuinely useful and diverse locomotion skills on the quadruped robot. This resilience stems from the algorithm’s design, which prioritizes exploration and the learning of adaptable behaviors, ensuring consistent and reliable performance even in unpredictable environments.
To bridge the gap between simulated training and real-world deployment, the study leverages a technique called ‘Domain Randomization’. This approach intentionally introduces variability into the simulation-randomizing parameters like friction, mass distribution, and even visual textures-effectively forcing the learning agent to develop robust policies insensitive to minor discrepancies between the virtual and physical environments. By training within a highly diverse simulated landscape, the resulting control strategies demonstrate improved generalization capabilities, allowing the quadruped robot to successfully execute learned skills in previously unseen and unpredictable real-world conditions. This proactive approach minimizes the need for extensive fine-tuning in the physical world, accelerating the deployment of complex locomotion behaviors.
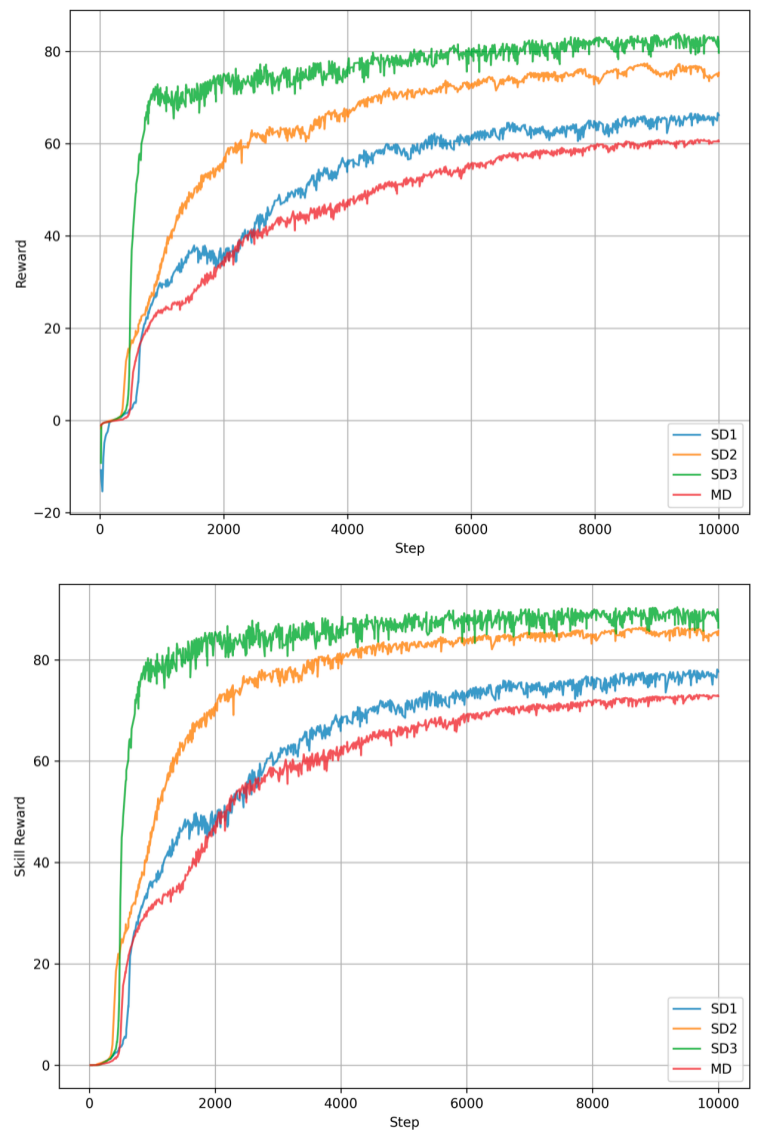
Evaluations on the Unitree A1 quadruped robot reveal that MOD-Skill significantly expands the range of achievable behaviors, achieving an 18.3% increase in state-space coverage compared to the leading alternative reinforcement learning algorithm. This improvement isn’t simply about performing existing skills better; it demonstrates a broader and more comprehensive exploration of the robot’s physical capabilities. The framework doesn’t just refine familiar gaits, but actively discovers and masters a more diverse set of locomotion skills, indicating a greater ability to adapt to varied terrains and challenges. This expanded coverage suggests a more robust and versatile skillset, moving beyond specialized performance to a more generalized and adaptable robotic intelligence.
“`html
The pursuit of robust, adaptable robotic systems necessitates acknowledging the inevitable entropy within complex designs. This research, with its focus on diverse skill discovery via MOD-Skill, implicitly understands this principle. A system capable of learning and executing a varied repertoire of locomotion skills is, by its nature, more resilient to unforeseen circumstances and changing environments. As John McCarthy observed, “It is better to do a good job of a little than to do a mediocre job of a lot.” The multi-discriminator approach and orthogonal mixture-of-experts policy aren’t about maximizing the number of skills, but rather ensuring the quality and independence of those skills – a focused ambition towards graceful aging in a dynamic world. Delaying the refinement of individual skills, as the study’s emphasis on stability suggests, is a tax on long-term performance.
What’s Next?
The pursuit of autonomous skill discovery, as demonstrated by frameworks like MOD-Skill, inevitably encounters the limitations inherent in any complex system. While novelty and diversity are actively encouraged, the underlying substrate-the robot itself-experiences inevitable degradation. Each gait learned, each successful traversal, incrementally contributes to wear and tear, subtly altering the dynamics of the learning process. The system does not merely acquire skills; it embodies them, and that embodiment is temporal.
Future work must acknowledge that “skill” isn’t a static endpoint, but a phase state. The current focus on maximizing diversity, while laudable, skirts the question of persistent diversity. Can a system maintain a repertoire of skills as its components age, or does it inevitably gravitate toward locally optimal gaits dictated by physical constraints? Addressing this requires moving beyond reward signals toward models that explicitly account for the robot’s evolving morphology and capabilities-a form of internal ‘self-modeling’ that anticipates, rather than reacts to, decay.
Furthermore, the avoidance of ‘reward hacking’-clever but ultimately meaningless exploitation of the reward function-highlights a deeper truth: true intelligence isn’t about maximizing a score, but about navigating the inherent ambiguity of the world. The next phase of research should prioritize robustness-the ability to gracefully degrade performance when faced with unforeseen circumstances or internal failures-rather than simply chasing ever-higher levels of efficiency. Uptime, after all, is merely a rare phase of temporal harmony.
Original article: https://arxiv.org/pdf/2602.09767.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-11 23:02