Author: Denis Avetisyan
New research demonstrates how vision and language models can empower humanoid robots to interpret complex tasks and execute them with grounded, spatial awareness.

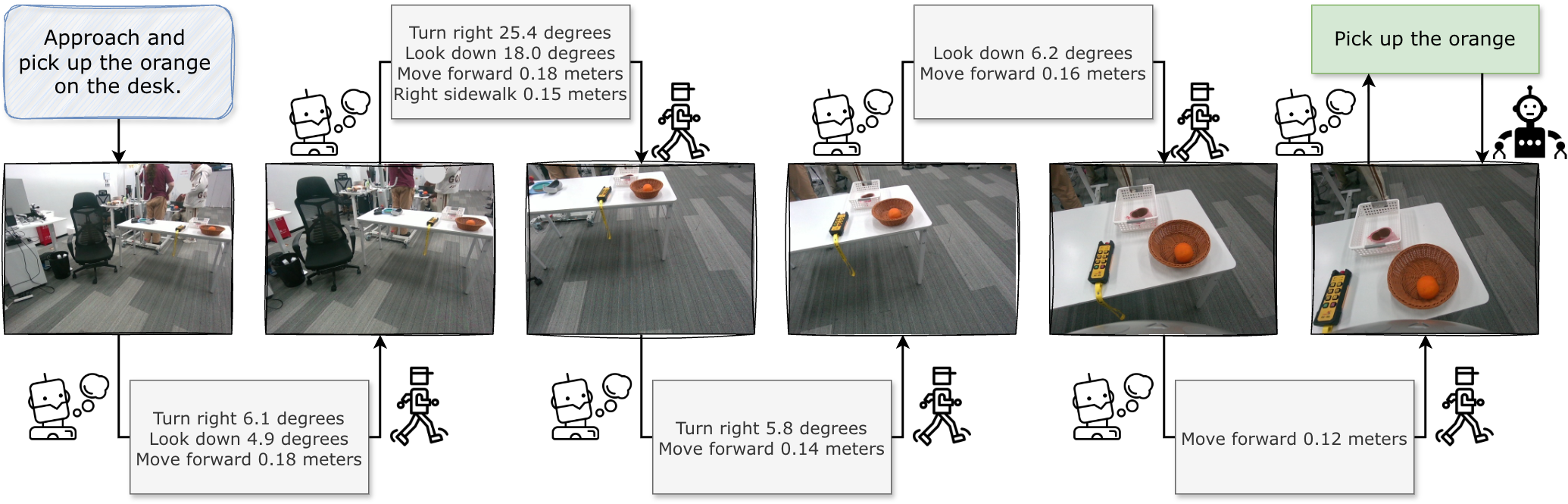
This work introduces EgoActor, a system that translates high-level instructions into sequences of egocentric actions for robust, real-world robot manipulation and locomotion.
Deploying humanoid robots in complex real-world scenarios demands a crucial link between high-level task directives and precise, embodied action. To address this challenge, we introduce EgoActor, a novel vision-language model detailed in ‘EgoActor: Grounding Task Planning into Spatial-aware Egocentric Actions for Humanoid Robots via Visual-Language Models’, that directly predicts spatially-aware robotic actions-including locomotion, manipulation, and human-robot interaction-from visual input and language commands. Leveraging broad supervision from real-world demonstrations and simulated environments, EgoActor achieves fluent action inference with both 8B and 4B parameter models, effectively bridging abstract planning and concrete motor execution. Will this approach unlock more robust and adaptable humanoid robots capable of seamlessly navigating and interacting within dynamic, everyday environments?
The Illusion of Robotic Intelligence
Historically, robotic systems have been largely defined by their rigidity; tasks are broken down into precise, pre-defined sequences of movements, or they require constant human direction through teleoperation. While effective in highly structured settings – such as assembly lines – this approach severely limits a robot’s ability to function in the unpredictable nature of real-world environments. A robot confined to pre-programmed actions struggles with even slight deviations from the expected, while constant remote control negates the potential for true autonomy and scalability. This reliance on explicit instructions or continuous guidance restricts robots to narrow applications, hindering their broader integration into daily life and limiting their usefulness in situations demanding adaptability, problem-solving, and independent decision-making.
The development of robots capable of genuine environmental understanding presents a formidable challenge, extending far beyond simple object recognition or pre-programmed responses. Current systems often falter when confronted with the inherent ambiguity and constant change characteristic of real-world settings; a cluttered room, a busy street, or even a slightly altered object pose significant difficulties. True understanding necessitates not merely identifying what is present, but also inferring why it is there, predicting its likely behavior, and adapting actions accordingly-a level of contextual reasoning that remains elusive. This isn’t simply a matter of increasing processing power or sensor fidelity; it demands fundamentally new approaches to artificial intelligence, moving beyond pattern recognition toward genuine comprehension of cause and effect within complex, unstructured spaces.
A central difficulty in developing truly intelligent robots lies in bridging the gap between sensing the world, interpreting that sensory input, and then executing appropriate actions – a process humans perform effortlessly. Current robotic systems often treat these stages as separate, sequential steps, creating bottlenecks and fragility. For instance, a robot might accurately detect an object but struggle to understand its purpose or how to manipulate it effectively given the surrounding context. This disjointed approach leads to brittle performance in unpredictable environments; minor variations – a slightly different lighting condition, an unexpected obstacle – can disrupt the entire process. Researchers are actively exploring architectures that emphasize continuous, embodied interaction, where perception informs action and vice versa, allowing robots to learn and adapt in real-time, much like biological organisms. The goal is to move beyond pre-programmed responses towards a system where reasoning and action are seamlessly interwoven, fostering robust and reliable performance in complex, dynamic settings.
The increasing demand for robots operating seamlessly alongside humans necessitates a fundamental shift in how these machines are controlled. Traditional robotic systems, often reliant on precisely defined parameters and static environments, falter when confronted with the inherent unpredictability of human spaces. A new paradigm moves beyond pre-programmed routines, instead prioritizing adaptable control architectures that allow robots to learn and respond in real-time. This involves developing systems capable of not just seeing an object, but understanding its affordances – what actions can be performed with it – and dynamically adjusting manipulation strategies based on changing human interactions and environmental conditions. Successfully integrating robots into dynamic human environments requires a move towards continuous learning, robust perception, and intelligent action planning, ultimately enabling these machines to become truly collaborative partners.

EgoActing: A First-Person Illusion of Understanding
EgoActing defines robotic tasks as the process of converting natural language instructions into a series of executable actions, all framed from the robot’s first-person perspective. This means the robot interprets commands as if they were directives experienced directly by itself, rather than as external goals to achieve. Consequently, the system must translate linguistic input into actions grounded in the robot’s egocentric perception of its environment; the instruction “pick up the mug” is understood and executed relative to the robot’s own visual and spatial awareness, forming a direct link between the command and the resulting motor commands. This contrasts with traditional robotic approaches where tasks are often decomposed into pre-defined skills and executed in a task-centric manner.
Traditional robotics often relies on robots possessing a pre-programmed repertoire of discrete skills, limiting adaptability to novel situations. EgoActing diverges from this paradigm by prioritizing the learning of action strategies themselves, rather than specific skill execution. This is achieved by framing tasks as the robot determining how to achieve a goal given the current environmental context and a high-level instruction. Consequently, the robot learns to dynamically generate actions based on perceived surroundings and objectives, effectively decoupling performance from a fixed set of pre-defined behaviors and increasing its capacity to generalize to previously unseen scenarios. This allows for more flexible and robust task completion, as the system learns to adapt its actions based on the specifics of each instance rather than relying on pre-programmed responses.
EgoActing leverages egocentric observations – that is, sensory data directly from the robot’s viewpoint – to interpret and execute instructions even when those instructions are not fully specified or contain inherent ambiguity. This approach allows the robot to infer missing information by referencing its immediate surroundings and current state. For instance, a command like “pick up the object” does not specify which object; the robot uses its visual input to identify potential targets within its field of view and select the appropriate one based on proximity, size, or other discernible features. This reliance on contextual perception allows EgoActing to function effectively with commands that would be impossible for systems requiring precise, complete instructions.
Implementing EgoActing requires an integrated system architecture capable of translating natural language instructions into coordinated physical actions. This necessitates modules for language understanding to parse intent from commands, perceptual processing to interpret egocentric sensor data – including visual and depth information – and action planning to generate appropriate motor commands. Crucially, these modules must interface effectively, enabling the system to map linguistic goals to perceived environmental states and subsequently to low-level actuator controls. Successful implementation demands robust mechanisms for state estimation, action prediction, and feedback control to address the inherent uncertainties in perception and execution, ultimately allowing the robot to reliably achieve specified tasks based on linguistic input and environmental context.
EgoActor: Grounding Language in Action (Or So It Seems)
EgoActor is a vision-language model (VLM) built upon recent developments in both large language models (LLMs) and visual processing techniques. This integration allows EgoActor to process and correlate information from both textual instructions and visual inputs. Specifically, it utilizes LLMs to interpret natural language commands and visual processing modules to analyze images or video streams of the environment. The combination of these capabilities enables EgoActor to understand the relationships between language and visual data, forming the basis for task planning and execution in robotic applications.
EgoActor employs a methodology of translating high-level instructions into actionable robot commands through the use of both structured and natural language actions. This approach facilitates precise spatial control by decomposing instructions into a series of defined actions with associated parameters – such as location, orientation, and object manipulation – which are then directly mapped to robot joint movements. The system leverages the strengths of both symbolic representations (structured actions) for deterministic control and the flexibility of natural language to interpret nuanced or ambiguous commands, enabling the robot to execute complex tasks with greater accuracy and adaptability compared to traditional, purely symbolic planning methods.
EgoActor’s performance in event understanding and action prediction has been quantitatively evaluated using the EgoTaskQA dataset. Results, detailed in Tables VII and VIII, indicate a high degree of accuracy in interpreting task instructions and forecasting subsequent robot actions. Specifically, the model achieves reported success rates on various task categories within the dataset, demonstrating its capability to link language input with appropriate physical actions. These success rates are calculated based on the percentage of correctly predicted actions given a specific task instruction and observed environmental state, providing a measurable metric for the model’s performance.
EgoActor incorporates active perception by enabling the model to request visual information from its environment when faced with ambiguous instructions or insufficient data for task completion. This functionality allows the system to query for specific views or details, such as “[show me the object to the left]” or “[what is behind the chair?]”, thereby reducing uncertainty and improving the accuracy of its environmental understanding. This proactive information gathering is implemented through a learned policy that determines when and what visual data to request, and is crucial for robust performance in complex, real-world scenarios where complete initial observations are unlikely.

Extending Capabilities and Real-World Validation (A Limited Victory)
EgoActor represents a significant advancement in robotic navigation by moving beyond simple pathfinding to incorporate a broader spectrum of actions. Traditional vision-and-language navigation (VLN) systems typically focused on directing a robot to a specified location; however, EgoActor expands this capability to include complex manipulation tasks, such as opening doors, picking up objects, and interacting with the environment in more nuanced ways. This is achieved through an innovative framework that integrates visual perception, natural language understanding, and robotic control, allowing the system to interpret instructions like “bring me the book from the table” and execute the necessary sequence of actions to fulfill the request. By extending the scope of VLN, EgoActor unlocks the potential for robots to perform more sophisticated and helpful tasks in real-world settings, bridging the gap between simple navigation and truly interactive assistance.
Rigorous testing of the system occurred within five distinct real-world rooms, utilizing a Unitree G1 humanoid robot to assess its navigational and manipulative capabilities. The evaluation protocol involved systematically testing the robot’s ability to enter and exit each room from two predetermined starting positions, with each positional test repeated four times to ensure data reliability. This comprehensive approach allowed researchers to quantify the system’s performance in authentic environments, demonstrating its capacity to execute complex tasks-such as navigating obstacles and interacting with objects-beyond simulated conditions. The results highlighted the system’s robustness and potential for deployment in practical applications requiring adaptable and precise robotic movement.
The enhanced manipulation skills of EgoActor are significantly bolstered by the integration of GROOT-N 1.5, a cutting-edge robotic manipulation dataset and accompanying benchmark. This resource provides a wealth of data focused on complex object interactions, allowing the system to learn more nuanced and precise motor control. Consequently, EgoActor demonstrates improved dexterity in tasks requiring intricate movements and delicate handling, moving beyond simple pick-and-place operations to encompass more sophisticated manipulations. The increased precision afforded by GROOT-N 1.5 minimizes errors and enhances the robot’s ability to reliably execute commands in dynamic and unstructured environments, ultimately leading to more effective and adaptable performance.
The development of EgoActor represents a significant step toward robots with broader applicability in human environments. By moving beyond simple navigation, this research demonstrates a pathway to robotic systems capable of complex manipulation and interaction with the physical world. This enhanced dexterity isn’t limited to pre-programmed actions; the system’s adaptability suggests potential for assisting with diverse tasks, ranging from household chores and delivering items to providing support in more complex settings like warehouses or care facilities. Ultimately, this work envisions a future where robots aren’t merely tools, but collaborative partners, seamlessly integrating into daily life and augmenting human capabilities across a wide spectrum of needs.

The pursuit of increasingly complex systems, as demonstrated by EgoActor and its attempts to bridge high-level instruction with low-level action, feels…predictable. The model strives for seamless translation of intent into physical execution, yet it inevitably introduces another layer of abstraction prone to failure. It’s a sophisticated mechanism for turning ambiguous requests into deterministic commands, but the inherent messiness of the real world will always find a way to expose the brittle underbelly of any such architecture. As David Hilbert observed, “We must be able to answer the question: can mathematics describe everything?” The same applies here; can any model truly account for the infinite variables of spatial reasoning and embodied interaction? The answer, predictably, will be ‘not entirely’.
The Road Ahead
EgoActor, like so many ‘grounding’ frameworks, achieves a neat translation of language to action. The immediate challenge, predictably, won’t be the model itself, but the environments it’s expected to function within. Simulated tidiness rarely survives contact with the real world. One anticipates a swift proliferation of edge cases – unexpected object occlusion, variations in lighting, the sheer unpredictable messiness of human-populated spaces – each requiring increasingly baroque workarounds. It’s a familiar pattern: elegant theory encountering the stubborn reality of production.
The emphasis on spatial reasoning is, of course, critical. But it merely shifts the problem. Current approaches treat space as a static backdrop. True robustness will demand models that actively predict how the environment will change – not just due to robot actions, but also due to external forces, human interference, and the delightful entropy of the universe. This isn’t a novel idea, but it’s one that consistently bumps against computational limits and the inherent uncertainty of prediction.
Ultimately, EgoActor represents another layer of abstraction. And, as anyone who’s witnessed a ‘revolutionary’ DevOps pipeline collapse under load will tell you, each layer introduces new points of failure. The promise of seamless language-to-action is compelling, but the inevitable reality will be debugging a cascade of interconnected systems. Everything new is just the old thing with worse docs.
Original article: https://arxiv.org/pdf/2602.04515.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 23:57