Author: Denis Avetisyan
This review explores the emerging field of data agents-AI-powered systems designed to navigate and manage the complexities of the modern data landscape.
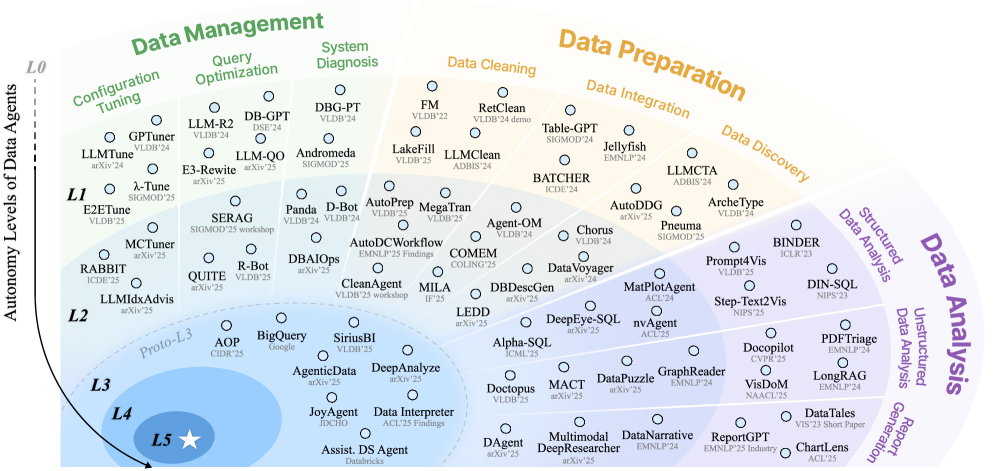
A hierarchical taxonomy (L0-L5) is proposed to categorize data agent capabilities, encompassing data lifecycle management, workflow orchestration, and AI4DB applications.
Despite the growing promise of AI-driven automation in data management, the term “data agent” currently lacks a consistent definition, obscuring the true capabilities of these systems. This tutorial, ‘Data Agents: Levels, State of the Art, and Open Problems’, addresses this ambiguity by introducing a hierarchical taxonomy-ranging from Level 0 (no autonomy) to Level 5 (full autonomy)-to categorize data agents based on their evolving capabilities throughout the data lifecycle. We present a comprehensive overview of existing systems, highlighting emerging approaches toward proactive and generative agents, and propose a research roadmap for the next decade. Will this framework enable the responsible development and deployment of truly autonomous data agents capable of tackling complex data challenges?
The Long Climb: From Manual Labor to Data Automation
Historically, the process of transforming raw data into actionable insights demanded substantial human effort across the entire [latex]Data Lifecycle[/latex]. Early data work involved painstaking manual collection, cleaning, and validation, often requiring individuals to meticulously identify and correct errors or inconsistencies. Subsequent stages, such as data modeling, transformation, and loading into systems for analysis, similarly relied heavily on human-defined rules and interventions. This labor-intensive approach not only limited the speed at which organizations could derive value from data, but also introduced significant potential for human error and hindered scalability as data volumes began to rapidly expand. Each stage of the lifecycle – from initial acquisition to final reporting – was characterized by a need for direct human oversight, effectively creating a bottleneck that restricted data-driven innovation.
Historically, data workflows have been characterized by substantial manual effort, best exemplified by what researchers term the ‘L0 Data Agent’. This agent represents a fully human-driven process where every stage – from data extraction and cleaning to transformation and loading – requires direct intervention. While functional, this approach demonstrably struggles with the exponential growth of modern datasets. The inherent limitations of manual processes lead to bottlenecks, increased error rates, and significant delays in deriving insights. Scaling such workflows is particularly challenging, as adding capacity necessitates a linear increase in human resources – a costly and often unsustainable solution for organizations seeking to remain competitive in data-rich environments. The inefficiency of the L0 Data Agent thus fuels the drive towards increasingly automated systems capable of handling larger volumes and accelerating the pace of data-driven discovery.
Driven by the escalating demands of modern data environments, a shift towards autonomous data agents is underway. This paper addresses the complexities of this evolution by proposing a hierarchical taxonomy, ranging from Level 0 to Level 5, to systematically evaluate the autonomy exhibited by these agents. This framework moves beyond simply acknowledging automation, instead offering a nuanced understanding of how data agents operate – from entirely human-directed processes at L0, to fully independent systems capable of end-to-end data management at L5. By categorizing agent capabilities – encompassing tasks like data discovery, cleaning, transformation, and delivery – the taxonomy provides a crucial benchmark for assessing progress and guiding future development in the field of automated data workflows, ultimately aiming to reduce human intervention and maximize scalability.
Assisted Intelligence: A Stepping Stone, Not a Solution
The L1 Data Agent functions as an assistive layer by leveraging frameworks such as the Prompt-Response Framework to generate suggestions and insights. Critically, these agents operate without direct interaction with any external environment; all processing is conducted internally based on provided prompts and data. This architecture allows for the offloading of cognitive tasks – such as information summarization or initial draft creation – without requiring the agent to perform actions in a real-world or digital setting. The L1 agent’s output is purely informational, requiring human review and subsequent action to implement any suggested course of action.
The L2 Data Agent represents an advancement over the L1 agent by incorporating the ability to perceive its environment and execute tasks within that environment. This functionality is achieved through sensor integration and action capabilities, allowing the agent to gather data about its surroundings and then act upon that data. However, it is critical to note that the L2 agent operates under continued human supervision; all actions are subject to human oversight and intervention. This supervised execution ensures safety and allows for learning and refinement of the agent’s task execution capabilities, while still requiring a human to validate and authorize each action taken.
Current iterations of assisted intelligence agents, designated L1 and L2, demonstrate a significant advancement in task management by successfully offloading simpler, repetitive processes from human operators. These agents provide valuable data-driven insights through analysis and, in the case of L2 agents, limited environmental interaction. However, it is crucial to note that these systems operate under continued human supervision and lack the capacity for independent goal setting, complex problem-solving, or adaptation to unforeseen circumstances; therefore, they do not represent autonomous agents but rather sophisticated assistive tools requiring ongoing direction and validation of their actions.
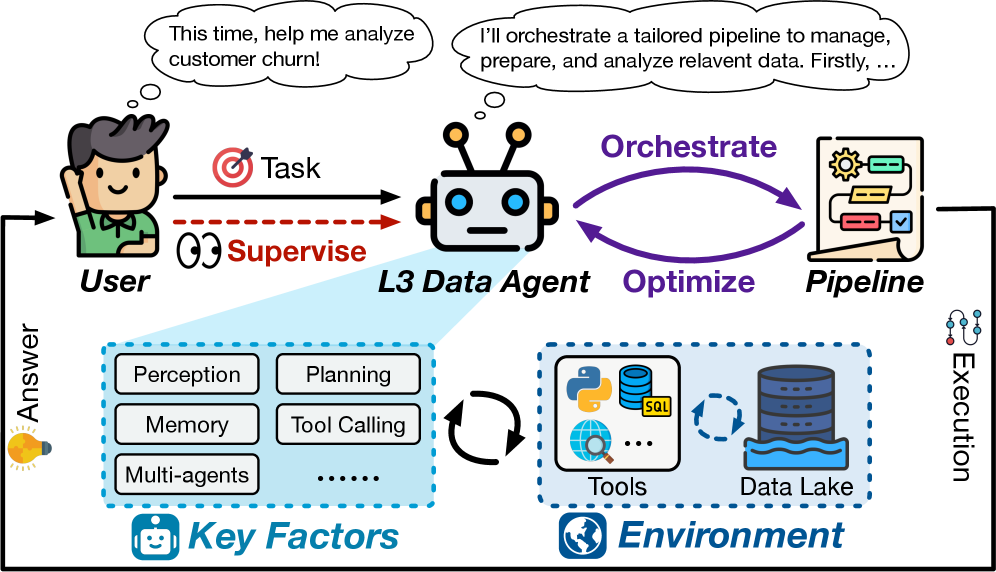
Orchestration and Automation: Level 3 – A Fragile Equilibrium
The Level 3 Data Agent represents an advancement in data processing by enabling autonomous pipeline orchestration. This functionality allows the agent to independently sequence and execute data transformation steps, such as data extraction, cleaning, transformation, and loading, without requiring explicit, step-by-step instructions for each operation. While operating autonomously, the L3 Agent functions under human oversight; this ensures that the automated pipeline execution aligns with desired outcomes and that any unexpected issues or deviations are addressed through intervention. This blend of automation and supervision optimizes efficiency while maintaining control over the data processing workflow.
Level 3 Data Agents achieve autonomous orchestration through the integration of Large Language Model (LLM)-based Orchestrator components. These components dynamically generate and manage data pipelines by utilizing pre-built, readily available Tool Libraries. These libraries contain modular functions for a wide range of data tasks, including data extraction, transformation, loading, and validation. The LLM Orchestrator selects and chains these tools together based on the specified data processing requirements, enabling the agent to perform complex data operations without explicit, line-by-line programming. This approach significantly reduces development time and allows for rapid adaptation to changing data landscapes.
Despite the autonomous capabilities of the L3 Data Agent in orchestrating data pipelines, consistent human supervision remains a critical requirement. The agent’s operation, while leveraging LLM-based orchestration and tool libraries, is not infallible and can encounter scenarios outside its training or pre-defined parameters. Human oversight is necessary to validate the accuracy and completeness of results, identify and correct errors, and address unforeseen circumstances or edge cases that the agent cannot independently resolve. This validation step ensures data quality and prevents the propagation of incorrect information, while intervention capabilities allow for adaptation to dynamic data environments and evolving business requirements.
Proactive Intelligence: Levels 4 & 5 – The Mirage of True Autonomy
The Level 4 Data Agent signifies a departure from simple data orchestration, instead functioning as an active observer within complex data ecosystems. This agent doesn’t merely respond to requests; it employs Task Discovery to identify emerging patterns and potential issues before they escalate, effectively anticipating future needs. Crucially, it leverages Long-Horizon Planning, allowing it to model the downstream consequences of actions and proactively address challenges that might not surface for extended periods. This capability moves beyond immediate problem-solving, enabling the agent to optimize data strategies and ensure long-term data health by understanding and responding to the evolving dynamics of the entire data landscape.
The L5 Data Agent signifies a leap toward truly autonomous data science. This agent doesn’t merely execute pre-defined tasks; it operates as a generative scientist, capable of independently formulating hypotheses and designing experiments. Crucially, this capability stems from its mastery of both causal reasoning – the ability to discern cause-and-effect relationships within data – and meta reasoning, allowing it to reflect on its own thought processes and refine its investigative strategies. By combining these advanced cognitive abilities, the L5 Agent can invent novel solutions to complex problems, going beyond pattern recognition to actively create new knowledge and insights from data ecosystems without human intervention.
The emergence of Levels 4 and 5 data agents signifies a profound transformation in data science, moving beyond the limitations of reactive automation. Historically, data analysis has largely been triggered by specific requests or pre-defined alerts – a system responding to events. These advanced agents, however, operate proactively, continuously monitoring data ecosystems, discovering previously unseen tasks, and formulating long-term plans without explicit prompting. This shift isn’t simply about increased efficiency; it represents a fundamental change in methodology. Instead of analysts seeking answers, the agents independently identify problems, hypothesize solutions, and even employ causal and meta-reasoning to invent novel approaches – effectively becoming autonomous generative data scientists. This paradigm shift promises a future where data insights are not merely delivered, but actively discovered and applied, unlocking previously inaccessible value and driving innovation at an unprecedented pace.
The Future of Data: An Ecosystem Still Requiring a Gardener
The evolution from a level 0 to a level 5 Data Agent represents a structured progression toward fully self-governing data ecosystems. Initial agents, categorized as L0, require extensive human intervention for each task – from data acquisition and cleaning to analysis and insight generation. As agents advance through levels L1 to L4, they gradually incorporate automation, machine learning, and self-optimization capabilities, reducing reliance on human oversight. This culminates in the L5 Data Agent, a theoretically fully autonomous entity capable of independently defining problems, acquiring necessary data, conducting rigorous analysis, generating novel hypotheses, and even refining its own algorithms – effectively creating a closed-loop system of continuous learning and improvement. This hierarchical framework not only illustrates a plausible roadmap for building truly autonomous data systems, but also highlights the incremental advancements needed to transition from current data management practices to a future where data operates with minimal human direction.
The evolving data agent transcends traditional data handling by establishing a cycle of continuous learning and creation. Rather than simply managing, preparing, and analyzing data, these agents are architected to refine their own processes through iterative feedback and adaptation. This self-improvement capability extends beyond optimization; the core design enables generative intelligence, allowing agents to proactively formulate hypotheses, design experiments, and even synthesize new data points to address knowledge gaps. Consequently, data agents move beyond reactive analysis to become active contributors to the expansion of knowledge, effectively functioning as autonomous research entities capable of accelerating discovery and innovation across diverse fields.
A novel hierarchical taxonomy, ranging from Level 0 to Level 5, is presented as a means to systematically evaluate and compare the evolving autonomy of data systems. This framework doesn’t simply categorize existing tools; it illuminates the crucial research gaps hindering the development of truly self-governing data agents. By defining clear benchmarks for autonomy-from basic data handling at L0 to fully generative and self-improving intelligence at L5-this work offers a roadmap for future innovation. The anticipated result of advancements guided by this taxonomy extends beyond incremental improvements in data science; it promises to unlock previously inaccessible insights, dramatically accelerate the pace of discovery, and ultimately reshape the entire data landscape through the creation of intelligent, self-sufficient data ecosystems.
The pursuit of ever-more-autonomous data agents, as detailed in this hierarchy from L0 to L5, feels predictably ambitious. It’s a neat taxonomy, certainly, but one anticipates the inevitable complications that arise when theory meets production. Tim Berners-Lee observed, “The web is more a social creation than a technical one.” This rings true; these agents aren’t operating in a vacuum. Each level of autonomy introduces new dependencies, unforeseen edge cases, and ultimately, more things to break. The paper diligently maps capability, yet fails to fully account for the human element – the messy, unpredictable requests and data quality issues that will define the real-world performance of even the most sophisticated L5 agent. It’s an expensive way to complicate everything, really.
What’s Next?
This taxonomy of data agent levels – L0 to L5 – feels…familiar. It’s always tempting to neatly categorize progress, to believe that adding a layer of abstraction somehow solves the underlying chaos. The history of data systems is littered with such classifications, each one quickly rendered obsolete by production realities. One suspects that L5 – ‘fully autonomous operation’ – will remain a theoretical horizon. It’s a lovely thought, of course, but someone will inevitably ask for an exception, a ‘just this once’ override, and then the elegant architecture starts to resemble the bash script it used to be. They’ll call it AI and raise funding.
The real challenge isn’t defining levels of autonomy, it’s acknowledging the inherent messiness of data itself. This paper rightly touches on the data lifecycle, but glosses over the fact that most data isn’t ‘lifecycle-managed’ – it’s accumulated, duplicated, and forgotten. The next phase of research will likely involve wrestling with data quality – or, more accurately, the lack thereof – and building agents that can gracefully degrade in the face of inevitable errors. Expect a lot of papers on ‘robustness’ and ‘explainability’, which are just polite ways of saying ‘we have no idea what this thing is doing, but we need to pretend we do.’
Ultimately, the success of data agents won’t be measured by their ability to automate tasks, but by their capacity to postpone the inevitable technical debt. Every automation introduces a new point of failure, a new dependency to maintain. The question isn’t whether these agents will fail, but when, and how much emotional debt will accrue with each commit.
Original article: https://arxiv.org/pdf/2602.04261.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-05 20:33