Author: Denis Avetisyan
A new analysis reveals that traditional graph theory methods can be surprisingly competitive with complex machine learning models for predicting missing links in real-world economic and financial networks.
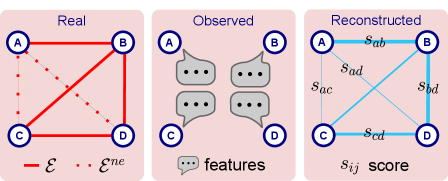
This review compares the performance of machine learning and physics-rooted approaches to link prediction, highlighting the value of interpretability and data efficiency.
Predicting missing connections within complex networks remains a central challenge in network science, despite the proliferation of both machine learning and physics-inspired algorithms. This study, ‘Missing links prediction: comparing machine learning with physics-rooted approaches’, systematically compares the performance of these two distinct methodological families-statistical physics models identifying likely links via maximum-entropy principles, and machine learning approaches associating edge presence with node-specific variables. Results demonstrate that the accuracy of these physics-rooted, interpretable algorithms is comparable to, and sometimes exceeds, that of the Gradient Boosting Decision Tree method, even on economic and financial network datasets. Does this suggest a path toward more transparent and computationally efficient link prediction, particularly in data-scarce environments?
The Inevitable Web: Predicting Connections in Complex Systems
The prediction of connections, or LinkPrediction, has become indispensable across a surprisingly broad spectrum of fields. In social networks, it powers friend suggestions and identifies influential users, while within financial systems, it’s vital for detecting fraudulent transactions and assessing systemic risk. Beyond these, the technique informs biological research by predicting protein interactions, enhances recommendation engines by anticipating user preferences, and even plays a role in knowledge graph completion, filling gaps in interconnected data. This ability to infer missing relationships isn’t merely an academic exercise; it’s a powerful tool for understanding complex systems and making informed decisions, driving innovation and security in an increasingly interconnected world.
Predicting connections within complex networks presents a significant challenge for conventional link prediction methods. These approaches frequently falter when faced with the subtleties of nuanced relationships, often relying on simplistic assumptions about network structure. While techniques might perform adequately on relatively homogenous networks, their accuracy diminishes considerably when confronted with the heterogeneous characteristics – varying node types, relationship strengths, and dynamic interactions – common in real-world systems like social media or financial markets. The inherent difficulty lies in capturing the intricate interplay of factors influencing connections, meaning that methods focused solely on node similarity or immediate neighborhood often fail to identify latent relationships or anticipate future link formations with sufficient reliability.
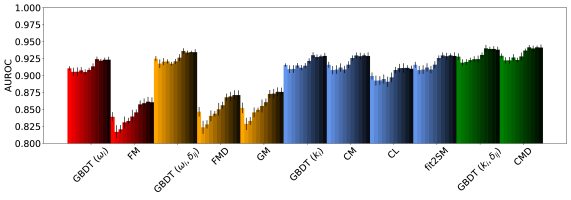
Determining the validity of predicted connections necessitates careful evaluation using established performance metrics. This study employed three key indicators – Accuracy, True Positive Rate (TPR), and Area Under the Receiver Operating Characteristic curve (AUROC) – to assess the reliability of link prediction models. Accuracy, measuring the overall correctness of predictions, ranged from approximately 0.7 to 0.9, indicating a generally high rate of correct predictions. However, TPR, which focuses on the ability to identify actual positive connections, exhibited greater variability, falling between 0.2 and 0.8. The AUROC, providing a comprehensive measure of the model’s ability to distinguish between connected and unconnected node pairs, demonstrated consistent performance with values between 0.6 and 0.8, suggesting a robust capacity to discriminate between potential links.
Intrinsic Structure: The Language of Endogenous Features
EndogenousFeatures represent characteristics derived from the network’s structure itself, rather than external variables. A primary example is NodeDegree, which quantifies the number of direct connections a node possesses. This metric serves as a proxy for a node’s local influence; nodes with higher degrees are typically more central and have increased potential to disseminate information or exert control within the network. Beyond simple counts, degree can indicate a node’s role – high-degree nodes often function as hubs, while low-degree nodes may represent peripheral elements. Analysis of degree distributions, such as the prevalence of power-law distributions in many real-world networks, provides insights into the network’s overall organization and resilience.
The [latex]ConfigurationModel[/latex] and [latex]ChungLuModel[/latex] are foundational network generation models that explicitly utilize node degree as a primary determinant of link formation probability. The [latex]ConfigurationModel[/latex] generates networks by randomly connecting stubs, ensuring that the degree sequence of the resulting graph matches a specified input degree sequence. The [latex]ChungLuModel[/latex] extends this by assigning connection probabilities proportional to the degrees of the nodes, effectively creating a weighted random graph where higher-degree nodes are more likely to connect. Both models predict that nodes with higher degrees will tend to attract additional connections, reflecting the “preferential attachment” phenomenon, and provide a baseline for evaluating the performance of more complex network models and machine learning approaches.
The [latex]DegreeCorrected2StarModel[/latex] and [latex]FitnessInduced2StarModel[/latex] represent advancements over simpler network generation models by incorporating both the degree distribution of the network and node-specific fitness parameters. These models aim to more accurately predict link formation by accounting for the non-random preferential attachment often observed in real-world networks. Empirical results demonstrate that these white-box models, when leveraging endogenous features like node degree and fitness, achieve performance comparable to that of machine learning models in link prediction tasks. This suggests that incorporating established network properties can provide a strong baseline and competitive results without the need for complex, data-intensive learning algorithms.

External Forces: The Influence of Exogenous Variables
Exogenous features represent external variables that influence relationships between entities within a network, but are not directly determined by the network itself. Common examples include Gross Domestic Product (GDP) and Geographic Distance. GDP provides a measure of economic size and activity, impacting the potential for interaction, while Geographic Distance quantifies the physical separation between entities, creating logistical and cost-related constraints. These features are incorporated into models as independent variables to explain observed connections; for instance, higher GDPs in both entities or shorter distances generally correlate with stronger relationships, offering contextual information beyond the inherent network structure.
The Gravity Model, originating from physics, posits that interaction between two entities is directly proportional to their ‘masses’ and inversely proportional to the distance between them. In the context of network analysis, particularly trade networks, ‘mass’ is typically represented by the Gross Domestic Product (GDP) of each country, and distance is measured as geographic distance. This model effectively predicts connection strength – the volume of trade, for example – based on these two variables; countries with larger GDPs and closer geographic proximity tend to have stronger trade relationships. The foundational equation is often expressed as [latex]T_{ij} = k \frac{GDP_i \cdot GDP_j}{D_{ij}}[/latex], where [latex]T_{ij}[/latex] represents trade flow between countries i and j, [latex]GDP_i[/latex] and [latex]GDP_j[/latex] are their respective GDPs, [latex]D_{ij}[/latex] is the geographic distance, and k is a constant of proportionality. Empirical studies consistently demonstrate the model’s predictive power across various bilateral trade datasets.
Gradient Boosting Decision Trees offer a method for predictive modeling by incorporating both endogenous and exogenous features within a training set. While these complex models demonstrate strong performance, evaluation across metrics including Accuracy, True Positive Rate (TPR), and Area Under the Receiver Operating Characteristic curve (AUROC) reveals comparable results to those achieved by white-box models. This suggests that, despite their increased complexity, these models do not consistently outperform simpler, interpretable alternatives, offering a robust, though not necessarily superior, predictive option.

The Crucible of Reality: Validation and Real-World Impact
The efficacy of link prediction models hinges on rigorous testing against real-world data, and two datasets stand out as particularly valuable resources: the WorldTradeWeb and the ElectronicMarketForInterbankDeposits. The WorldTradeWeb, representing global trade relationships between countries, offers a complex network structure suitable for evaluating a model’s ability to predict future trade partnerships. Simultaneously, the ElectronicMarketForInterbankDeposits, which maps financial transactions between banks, presents a different, yet equally challenging, landscape for assessing predictive capabilities within the financial sector. By applying link prediction models to these distinct domains, researchers can gain a comprehensive understanding of their generalizability and identify potential limitations specific to either trade or financial networks. These datasets, therefore, are not merely benchmarks, but crucial tools for refining and validating the performance of link prediction algorithms across diverse, practical applications.
The true test of any link prediction model lies in its capacity to forecast connections within real-world networks, and validation using datasets like WorldTradeWeb and ElectronicMarketForInterbankDeposits provides precisely that opportunity. By applying these models to established transactional data, researchers can assess their predictive power – determining how accurately they anticipate future relationships or interactions. This process isn’t simply about achieving a high score; it’s about understanding whether the model’s internal logic reflects the underlying mechanisms driving network evolution. Successful prediction demonstrates a model’s potential for practical applications, ranging from identifying emerging risks in financial systems to optimizing the flow of information within complex organizations, and ultimately confirming the robustness of the proposed methodology.
The capacity to accurately predict connections within complex networks holds substantial promise for bolstering risk management strategies, enhancing fraud detection systems, and optimizing network infrastructure. Recent investigations demonstrate that white-box models, characterized by their interpretability and reliance on established network principles, can achieve levels of performance in link prediction-measured by metrics like Accuracy, True Positive Rate (TPR), and Area Under the Receiver Operating Characteristic curve (AUROC)-that are comparable to those of more complex machine learning algorithms. This finding suggests a compelling alternative for applications where transparency and understanding of the prediction process are paramount, offering a robust and potentially more reliable approach to network analysis and future connection forecasting.
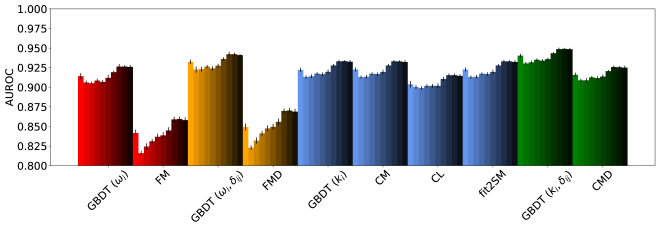
The study’s findings suggest a cyclical nature to predictive power; machine learning models initially demonstrate promise, yet their advantage diminishes as data becomes constrained. This echoes a fundamental truth about systems: every dependency is a promise made to the past. Pierre Curie observed, “One never notices what has been done; one can only see what remains to be done.” The research subtly demonstrates this principle; even as algorithms evolve, the inherent limitations of data-what remains unknown-constantly reshape the landscape of prediction. It’s not about achieving perfect control, but acknowledging the inherent ebb and flow of information within these complex networks, where simpler, interpretable models often offer a resilience born of necessity.
What’s Next?
The pursuit of link prediction inevitably reveals less about predicting the future, and more about the inherent limitations of static models applied to dynamic systems. This work, by demonstrating the continued relevance of simpler, interpretable methods, subtly underscores a crucial point: complex algorithms don’t solve the problem of incomplete information – they merely redistribute the uncertainty. Long stability in model performance isn’t a victory, but a prolonged deferral of inevitable divergence from the system’s true trajectory.
Future efforts will likely focus on hybrid approaches, attempting to blend the inductive power of machine learning with the deductive constraints of network theory. However, the real challenge lies not in achieving incremental improvements in predictive accuracy, but in fundamentally shifting the question. Instead of asking if a link will form, perhaps the more fruitful inquiry concerns how the network will reorganize in response to inevitable disruption. The system doesn’t need prediction; it needs resilience.
The datasets employed here, while valuable, represent only a narrow slice of possible network topologies. True understanding will require embracing the messiness of real-world systems – the incomplete data, the hidden variables, and the constant, unpredictable evolution. A model that excels today is simply a fossil of a past network, a testament to a system that no longer exists. The next step isn’t better algorithms, but a recognition that systems don’t fail – they become something else.
Original article: https://arxiv.org/pdf/2601.23061.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-02-03 01:11