Author: Denis Avetisyan
New research demonstrates a pathway to more robust and efficient robotic manipulation in dynamic environments, crucial for off-world operations and beyond.
Learning adaptive grasping policies in a latent space conditioned on environmental factors significantly improves sample efficiency and stability under open-loop control.
Reliable robotic manipulation remains a challenge in unstructured environments, often hindered by sparse rewards and poor generalization despite advances in reinforcement learning. This work, ‘Towards Space-Based Environmentally-Adaptive Grasping’, addresses these limitations through a novel approach to learning grasping policies in a latent space explicitly conditioned on environmental factors. We demonstrate that this method achieves over 95% success in single-shot manipulation tasks with significantly improved sample efficiency compared to state-of-the-art baselines, even under continuously varying conditions. Can explicitly reasoning about environmental context within a compact latent representation unlock truly adaptive and generalizable grasping capabilities for deployment in the extreme conditions of space?
The Fragility of Embodied Control
Conventional robotic control systems frequently depend on meticulously crafted models of the robot and its environment. These models, while effective in controlled laboratory settings, often falter when confronted with the inherent uncertainties of the real world. Minute discrepancies – an unexpected slippery surface, a slightly misaligned object, or even subtle changes in lighting – can introduce significant errors, leading to instability or failure. This brittleness stems from the fact that these models assume a level of predictability that rarely exists outside of simulations; any deviation from the anticipated conditions can quickly overwhelm the control system, highlighting the need for more adaptable and resilient robotic control strategies.
The effective integration of robots into unstructured environments demands control policies capable of weathering unforeseen circumstances. Real-world scenarios present a constant stream of variability – shifting terrains, unexpected obstacles, and the complex physics of contact – that can easily derail systems reliant on precise pre-programmed movements. Researchers are therefore prioritizing the development of robust policies, often leveraging techniques like reinforcement learning and adaptive control, that allow robots to maintain functionality even when faced with unpredictable environmental changes and the nuanced dynamics of physical interaction. These policies don’t attempt to prevent disturbances, but rather enable robots to recover from them, ensuring reliable performance in dynamic and uncertain conditions and paving the way for broader robotic deployment beyond highly controlled settings.
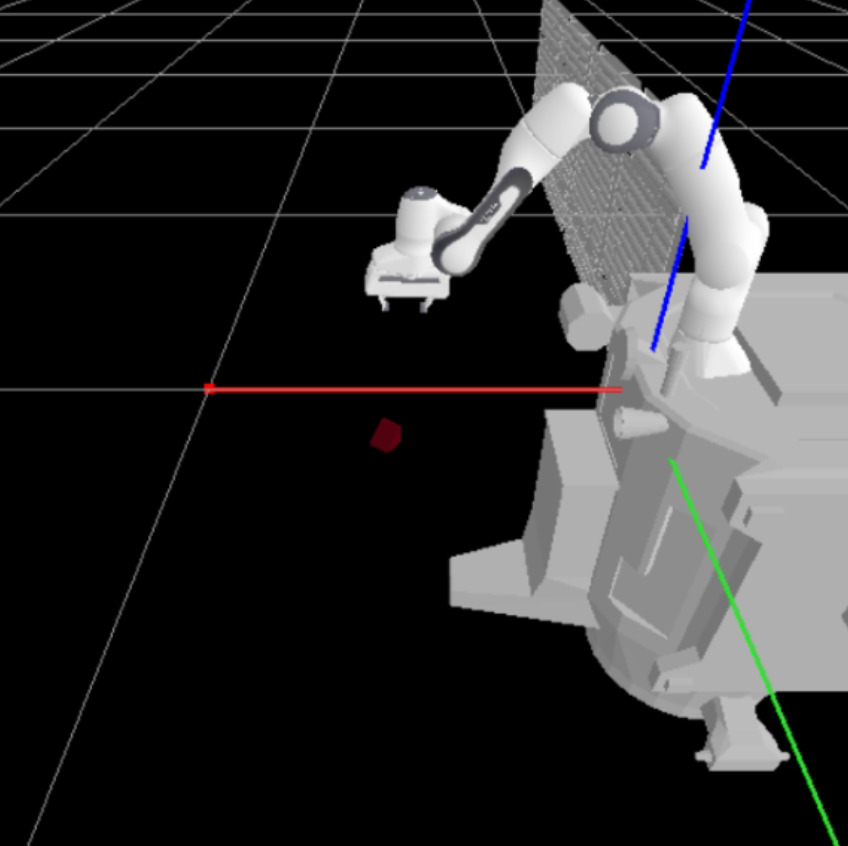
![The policy operates open-loop, utilizing a single initial observation-incorporating [latex]RGB[/latex], depth, and segmentation data-of a morphed cubic target to guide subsequent actions.](https://arxiv.org/html/2601.21394v1/Grammarization/mani_skill_image.png)
Leveraging Simulation for Policy Optimization
The Soft Actor-Critic (SAC) algorithm is a model-free, off-policy reinforcement learning method suited for continuous action spaces. It maximizes a trade-off between expected return and entropy, encouraging exploration and robustness by learning a stochastic policy. This approach differs from deterministic policy gradient methods by maintaining an ensemble of Q-functions to mitigate overestimation bias, a common issue in Q-learning. SAC utilizes automatic entropy tuning to adapt the exploration rate during training, allowing the agent to efficiently learn complex behaviors. The algorithm’s off-policy nature enables efficient data reuse, accelerating the learning process and reducing sample complexity compared to on-policy methods. This combination of features allows SAC to learn control policies that are demonstrably more robust to disturbances and variations in the environment.
Training robotic control policies within a simulated environment like ManiSkill offers significant advantages in terms of data acquisition and exploration efficiency. ManiSkill provides a platform for generating large datasets of robot interactions with varying task parameters and environmental conditions, a process that would be time-consuming and potentially damaging to hardware in a real-world setting. The simulation allows for parallelization of training episodes, drastically reducing the time required to explore the policy space. Furthermore, the ability to reset the environment to specific states after each trial enables focused learning on critical skills and accelerates the convergence of reinforcement learning algorithms. This efficient data collection is crucial for training complex policies that require a substantial amount of experience to achieve robust performance.
Transferring policies learned in simulation to real-world robotic systems presents significant challenges due to discrepancies between the simulated and physical environments. These discrepancies, often referred to as the “sim-to-real” gap, arise from inaccuracies in the simulation’s physics engine, sensor models, and actuator representations. Furthermore, unmodeled dynamics and external disturbances in the real world are not typically accounted for in the simulation. Consequently, a policy that performs well in simulation may exhibit degraded performance or even fail completely when deployed on a physical robot, necessitating techniques like domain randomization, system identification, or adaptive control to mitigate these effects and improve generalization.
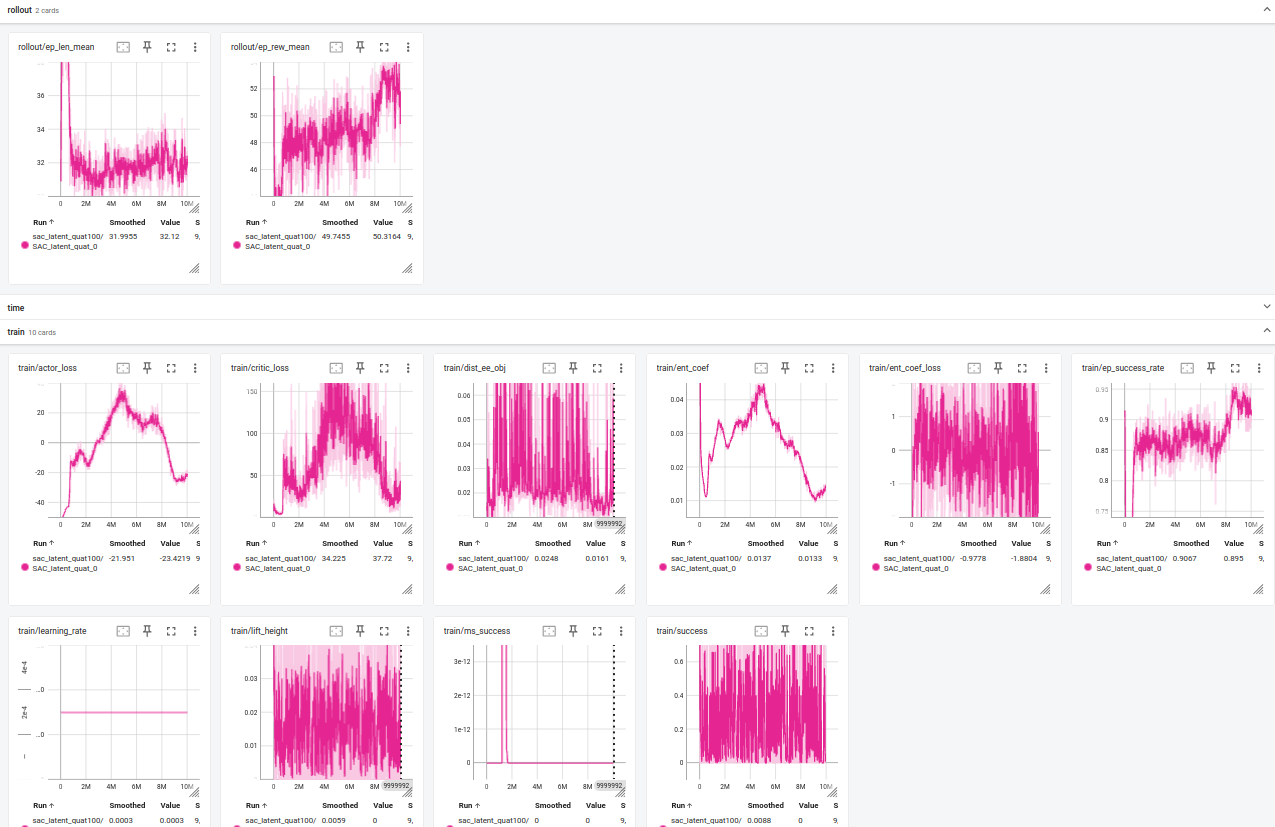
![Training curves reveal that a policy combining latent state and environmental observations ([latex]Run\ A[/latex]) converges fastest and achieves sustained success rates above 0.95 after 8.5 million environment steps, outperforming both one-shot visual ([latex]SAC[/latex]) and latent-only ([latex]Run\ B[/latex]) approaches.](https://arxiv.org/html/2601.21394v1/train__critic_loss_el.png)
Enhancing Robustness Through Environmental Perturbation
Physics Parameter Randomization is a training methodology where physical properties of the simulated environment, specifically parameters like friction coefficients and object masses, are randomly sampled from predefined distributions during each training episode. This introduces variability in the dynamics of the simulation, forcing the learning agent to adapt to a wider range of physical conditions. The randomization is applied to relevant physics engine settings, creating a distribution of environments encountered throughout training. The ranges for these parameters are typically determined through domain knowledge or exploratory analysis to ensure realistic and challenging scenarios.
Training with physics parameter randomization requires an episodic training structure where the values of physical parameters are resampled at the beginning of each episode. This creates a distribution of environments encountered during training; the breadth and characteristics of this distribution are directly determined by the ranges and probability distributions used when sampling parameters such as friction, mass, and damping. Consequently, the policy learns to adapt not to a single, static environment, but to a statistical ensemble of environments defined by these episode-wise parameter variations, enabling generalization to previously unseen configurations within that distribution.
Training reinforcement learning policies across a distribution of environments demonstrably improves generalization to previously unseen conditions. Specifically, subjecting the policy to varied physical parameters during training – such as friction and mass – increases robustness and reduces reliance on specific environmental configurations. Empirical results indicate that this approach yields a sustained success rate of 95% in novel environments, representing a significant improvement over policies trained in single, fixed conditions. This performance gain is attributable to the policy learning features that are invariant to these environmental variations, enabling successful operation across a broader range of possible scenarios.
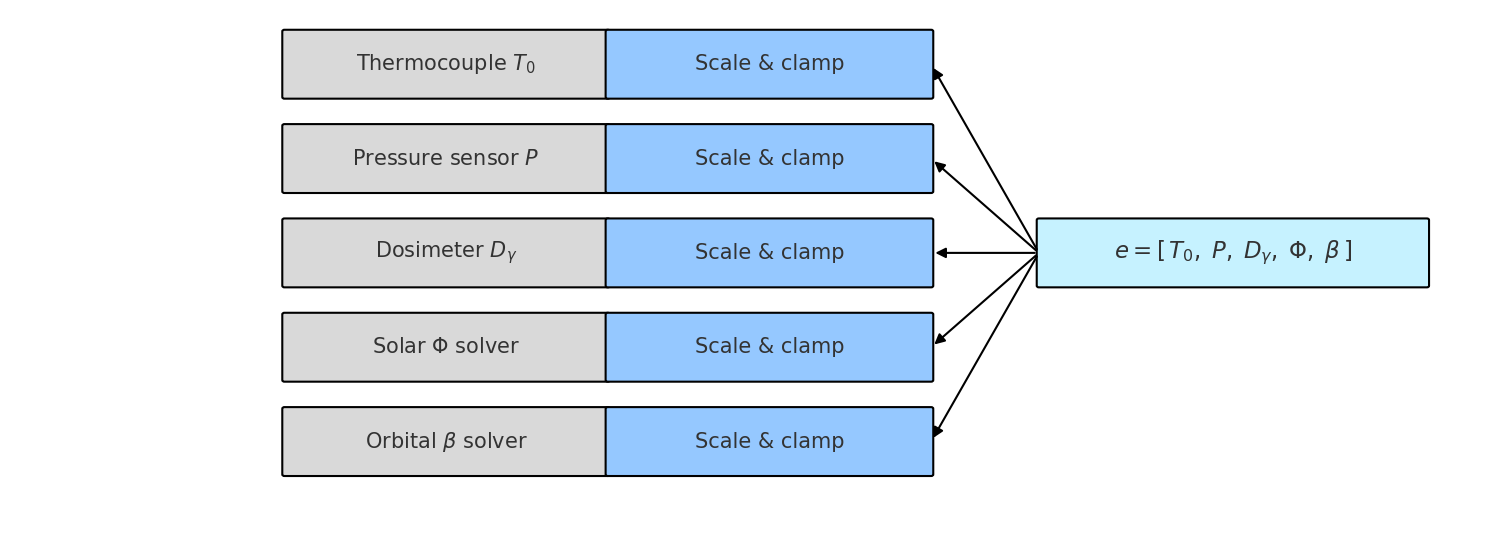
Abstraction Through Compact State Representation
Grammarization is a technique employed to reduce the dimensionality of observational data prior to processing by learning algorithms. This involves mapping inputs from a high-dimensional observation space – which may include visual data, proprioceptive feedback, and other sensor readings – into a lower-dimensional latent space. The process utilizes a variational autoencoder (VAE) architecture to learn a probabilistic mapping, effectively compressing the information while retaining key features relevant for downstream tasks. This reduction in dimensionality significantly improves computational efficiency and allows for more effective learning, particularly in complex environments where the original observation space is excessively large.
The compact representation generated through grammarization serves as a foundational element for both the Soft Actor-Critic (SAC) algorithm and Environment Conditioning techniques. SAC utilizes this lower-dimensional latent space for policy optimization and value function learning, reducing computational complexity and improving sample efficiency. Simultaneously, Environment Conditioning leverages the same compact representation to create a conditioned state space, allowing the agent to focus on relevant information and enhance generalization capabilities. This shared representation streamlines the learning process for both components, enabling more effective and efficient adaptation to the environment.
Mutual Information Decoupling enhances policy generalization by minimizing statistical dependencies between different components of the latent space representation. This is achieved by encouraging each dimension of the latent space to encode independent factors of variation within the observed data. The resulting disentangled representation allows the policy to more effectively learn and adapt to unseen states, ultimately yielding a final smoothed success rate of 0.979 across evaluated tasks. This decoupling process improves robustness and prevents the policy from relying on spurious correlations present in the training data.
Ensuring Stability Through Valid Pose Representation
Representing a robot’s orientation in three dimensions presents a unique challenge – traditional Euler angles are susceptible to ‘gimbal lock’, a loss of one degree of freedom that can lead to unpredictable and potentially dangerous movements. To overcome this, researchers employ quaternion unit projection, a technique that constrains the learned representation of orientation to a valid four-dimensional hypersphere. This ensures the robot’s understanding of its own pose remains consistent and avoids the singularities inherent in Euler angles. By mathematically projecting the learned orientation values onto the unit quaternion space, the system effectively prevents invalid or physically impossible orientations from being adopted, thereby significantly enhancing the stability and predictability of robotic control, even over extended operational periods.
The integration of Quaternion Unit Projection with the Soft Actor-Critic (SAC) algorithm demonstrably enhances robotic system dependability and operational safety. By constraining the learned orientation representations, the system minimizes the risk of instability and unpredictable behavior during deployment. This combination allows the robot to navigate and interact with its environment more predictably, even when faced with challenging or novel situations. Consequently, the resulting control policies exhibit increased robustness, leading to fewer failures and a greater capacity for safe operation over extended periods, as evidenced by sustained success across approximately 8.5 million environment steps.
The culmination of these methodological improvements yields robotic systems exhibiting markedly increased resilience and adaptability when navigating intricate, real-world scenarios. Extensive trials demonstrate sustained operational success-maintaining consistent performance over approximately 8.5 million simulated environment steps-a benchmark indicating a significant leap in long-term reliability. This enhanced robustness isn’t merely about avoiding immediate failures; it signifies a capacity for continued learning and adjustment, allowing the robot to maintain proficiency even as environmental conditions shift or unexpected obstacles arise. The result is a platform capable of prolonged, autonomous operation in dynamic settings, representing a crucial step towards deploying robots in increasingly complex and unpredictable applications.
![A trained autoencoder compresses input into a latent manifold [latex] \mathbb{R}^n [/latex] at its bottleneck, which is then used as input to a reinforcement learning agent to facilitate grammarization.](https://arxiv.org/html/2601.21394v1/Grammarization/Target_encoding_plain.png)
The pursuit of robust robotic manipulation, as demonstrated in this work concerning environmentally-adaptive grasping, echoes a fundamental tenet of mathematical rigor. The paper’s focus on conditioning grasping policies on environmental parameters – achieving stability even under open-loop control – highlights the necessity of explicitly defining and accounting for all variables. This resonates deeply with the spirit of formal verification. As David Hilbert famously stated, “In every well-defined mathematical domain, one can, in principle, decide whether any given proposition is true or false.” Similarly, this research aims to create a system where robotic actions are predictable and reliable not through mere empirical success, but through a principled understanding of the underlying physics and environmental influences. The latent space approach, combined with physics randomization, represents a step towards that formal decidability in the realm of robotic control.
What Remains Constant?
The demonstrated efficacy of latent space control, conditioned on environmental parameters, is not, in itself, surprising. Reduction to a compact representation-a distillation of complexity-is a perennial pursuit. However, the question lingers: Let N approach infinity-what remains invariant? The current work establishes gains in sample efficiency, a pragmatic benefit, but sidesteps the fundamental problem of true generalization. Physics randomization, while effective as a training heuristic, is a brute-force approach. It masks the underlying need for a policy demonstrably robust to all perturbations, not merely those encountered during simulation.
Future investigations must address the limitations of open-loop control. The reliance on pre-computed actions, even within a learned latent space, introduces a fragility inherent in any system divorced from real-time sensory feedback. A truly elegant solution would necessitate a closed-loop architecture, where the policy adapts continuously to observed discrepancies between prediction and reality. This demands a deeper exploration of state estimation and control theory, not merely algorithmic refinement.
The pursuit of ‘environmentally-adaptive grasping’ is, ultimately, a search for invariants-the minimal set of principles that govern stable manipulation regardless of external conditions. While this work represents a step forward, the ultimate test lies not in achieving incremental improvements, but in formulating a policy provably correct, not merely empirically successful. The algorithm must stand up to scrutiny, not just ‘work on tests’.
Original article: https://arxiv.org/pdf/2601.21394.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
2026-01-30 14:43