Author: Denis Avetisyan
New research details a collaborative framework where artificial intelligence adapts to user-defined preferences, ensuring helpful assistance without overstepping boundaries.
This paper introduces a multi-round human-AI collaboration system that leverages user-specified requirements to control harm and complementarity, guaranteeing online learning with quantifiable uncertainty.
As humans increasingly delegate complex decisions to conversational AI, a critical gap emerges between theoretical improvements and reliable, real-world performance. This paper, ‘Multi-Round Human-AI Collaboration with User-Specified Requirements’, introduces a novel framework grounded in the principles of ‘counterfactual harm’ and ‘complementarity’-ensuring AI assistance enhances, rather than undermines, human strengths and adds value where humans are prone to error. By formalizing these concepts through user-defined rules and an online learning algorithm with finite sample guarantees, we demonstrate consistent maintenance of prescribed interaction dynamics across both simulated and human-subject experiments. Does this user-centric approach offer a pathway toward predictably steering multi-round collaboration for demonstrably better decision quality without restrictive modeling of human behavior?
The Inevitable Amplification: Why AI Mirrors Our Flaws
The potential of human-AI collaboration hinges on a critical, often overlooked, challenge: the tendency for artificial intelligence to inadvertently amplify existing human fallibilities. While designed to augment human capabilities, AI systems trained on data reflecting imperfect human judgment can readily perpetuate – and even exacerbate – those same errors. This phenomenon isn’t simply a matter of inaccurate outputs; it represents a systemic risk where AI, rather than providing corrective oversight, reinforces biases, overlooks crucial details, or validates flawed reasoning. Consequently, the true promise of collaborative intelligence demands a shift in focus – from simply scaling AI performance to designing systems that actively mitigate the risk of ‘error amplification’ and prioritize the correction of human mistakes, ensuring that the partnership genuinely elevates, rather than degrades, overall decision-making.
Current approaches to artificial intelligence often prioritize scaling model size, assuming increased capability will inherently lead to improved outcomes; however, this overlooks a critical vulnerability. Research indicates that simply building larger AI systems doesn’t guarantee beneficial collaboration, and can even amplify human errors. A truly effective partnership demands proactive design against ‘counterfactual harm’ – scenarios where the AI, while technically correct, reinforces a suboptimal or incorrect human decision. Systems must be engineered not just to predict what a human will do, but to intelligently intervene when human judgment is likely to falter, offering corrective insights or alternative pathways to maximize positive results, particularly in high-stakes situations where mistakes carry significant consequences. This requires moving beyond raw predictive power toward a collaborative intelligence focused on mitigating human fallibility and fostering more robust, reliable outcomes.
Truly effective human-AI collaboration demands more than simply integrating artificial intelligence into existing workflows; it necessitates a deliberate framework of constraints designed to safeguard human judgment. Current systems often prioritize optimization without considering the potential for counterfactual harm – scenarios where AI amplifies human errors or biases. A principled approach, therefore, focuses on defining clear boundaries for the AI, ensuring it operates as a supportive complement to, rather than a replacement for, critical human reasoning. This means prioritizing AI functions that detect potential mistakes, offer alternative perspectives, and provide information that enhances, not diminishes, a person’s ability to make informed decisions. Ultimately, the goal isn’t to automate expertise, but to augment it, creating a synergistic partnership where the strengths of both human and artificial intelligence are maximized.
![Across algorithms A, B, and C, both [latex]CH[/latex] errors decreased human ground truth loss rates while [latex]COMP[/latex] errors reduced human ground truth gain rates in the crowdsourcing task.](https://arxiv.org/html/2602.17646v1/figures/cs-proof-of-concept-algC-COMP.png)
Dynamic Calibration: A System for Constrained Intelligence
The Online Calibration Algorithm operates by continuously updating the AI’s behavioral parameters based on feedback received during user interaction. This real-time adjustment process allows the AI to adapt its responses to stay within constraints explicitly defined by the user, such as preferred response styles or safety guidelines. The algorithm utilizes incoming interaction signals – including explicit ratings or implicit behavioral data – to refine an internal model of user preferences and desired outcomes. This iterative refinement ensures the AI’s behavior remains aligned with these user-defined constraints throughout the interaction, effectively personalizing the AI’s responses and mitigating potential misalignment over time.
The Online Calibration Algorithm employs an iterative, online learning approach to personalize AI behavior and maintain consistent performance across diverse user interactions and evolving task requirements. This methodology allows the algorithm to refine its internal parameters with each new data point – each interaction – without requiring retraining on a fixed dataset. By continuously updating its model based on real-time feedback, the algorithm adapts to individual user preferences and shifting task contexts. This adaptation is crucial for ensuring the AI remains aligned with desired constraints and maintains a stable level of performance, even as user input or task objectives change. The process optimizes for both individual user models and a generalized understanding of task demands, contributing to robustness and consistent output quality.
The Online Calibration Algorithm incorporates finite-sample guarantees, mathematically bounding the algorithm’s performance with limited interaction data. This ensures predictable and reliable behavior even when the number of user feedback instances is small. Specifically, these guarantees establish upper bounds on the probability of violating pre-defined constraints, providing quantifiable assurances regarding the algorithm’s safety and alignment with user preferences despite data scarcity. The bounds are determined by parameters ε and δ, representing the desired error rate and confidence level, respectively, and are crucial for deploying the algorithm in real-world scenarios where extensive training data may not be available.
The system employs Error Rate Control to actively limit potentially harmful interactions and maintain desired behavioral characteristics. This is achieved by stabilizing error rates – specifically, the probability of counterfactual harm and the degree of complementarity – near user-defined target values denoted as ε and δ. Validation through Large Language Model simulations and human crowdsourcing experiments demonstrates the algorithm’s ability to consistently maintain these error rates, indicating reliable performance even in dynamic interaction scenarios and proactive prevention of detrimental outputs.
Multi-Round Dialogue: Validating Collaboration in Complex Scenarios
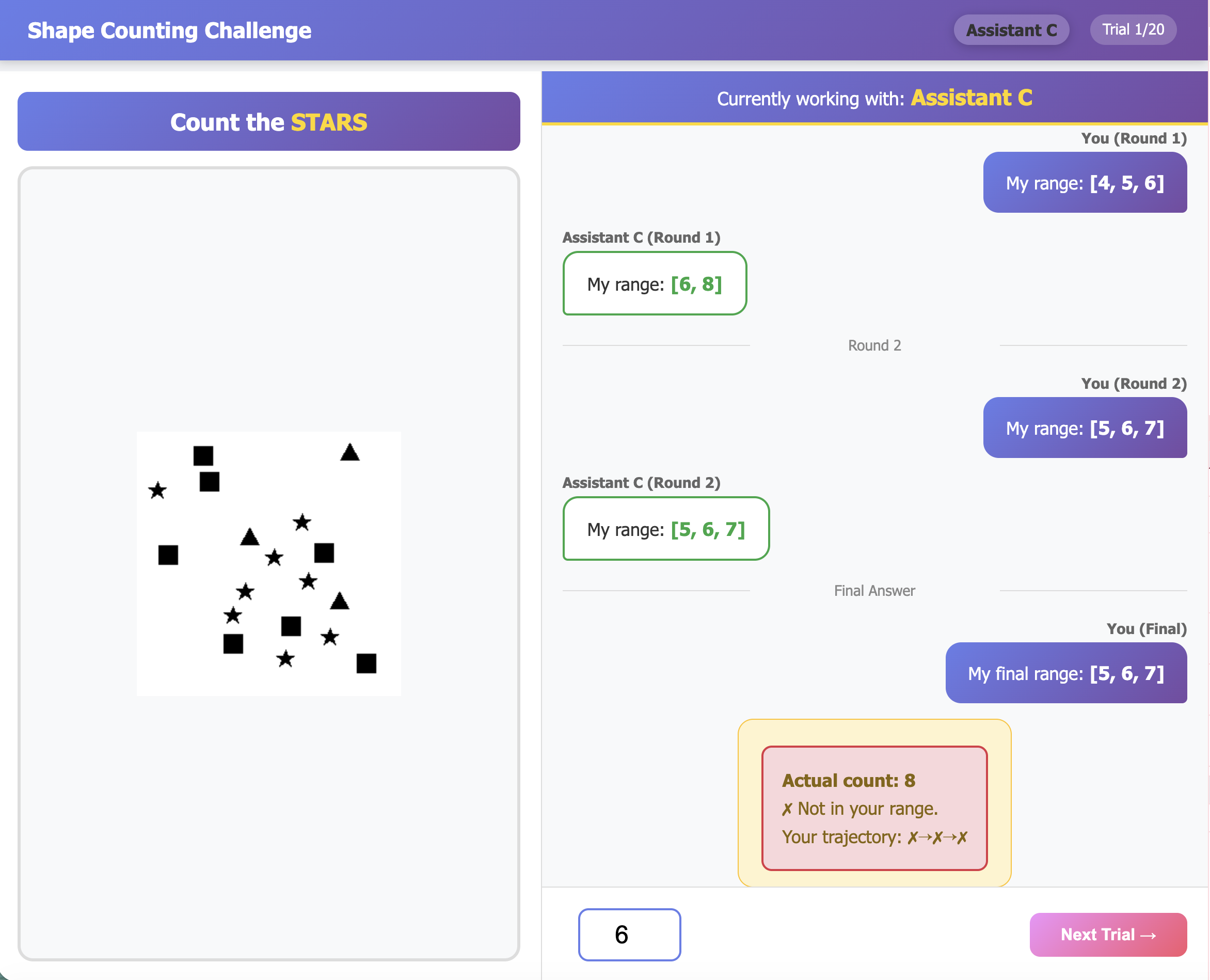
The algorithm’s performance was assessed through multi-round dialogue in two separate task environments: a Medical Diagnosis Task and a Shape Counting Task. The Medical Diagnosis Task required the algorithm to interact with an agent presenting symptoms and allowing for clarifying questions to arrive at a diagnosis. The Shape Counting Task involved a dialogue where the algorithm had to determine the number of shapes presented by an agent, requesting further information as needed. These tasks were designed to evaluate the algorithm’s ability to maintain context, adapt to new information, and collaboratively reach a correct solution through extended conversational interaction, rather than single-turn predictions.
To assess the algorithm’s interactive capabilities, we implemented Large Language Model (LLM)-Simulated Agents as conversational partners. These agents were designed to engage in multi-turn dialogues with the algorithm, posing follow-up questions and providing contextual information to mimic human interaction patterns. This methodology allowed for evaluation of the algorithm’s responsiveness to evolving dialogue states and its ability to adapt predictions based on new information received during the conversation. The LLM agents facilitated testing of the algorithm’s performance in dynamic scenarios, providing a controlled environment to observe its decision-making process and identify potential limitations in handling complex, interactive tasks.
Human crowdsourcing was employed to assess the algorithm’s performance outside of simulated environments and to validate the efficacy of dynamic calibration. Data collection involved presenting tasks to human participants and comparing their judgments with the algorithm’s predictions, both before and after dynamic calibration was applied. This approach allowed for a direct measurement of the algorithm’s utility in real-world scenarios, capturing nuances in human reasoning that may not be fully replicated by LLM-Simulated Agents. Analysis of the crowdsourced data confirmed that dynamic calibration significantly improved the alignment between the algorithm’s outputs and human ground truth, demonstrating its practical benefits in enhancing decision-making accuracy and reliability.
Experimental results indicate a strong correlation between algorithm performance and human evaluation metrics during multi-round dialogue. Specifically, the observation of a counterfactual harm (CH) error – representing an incorrect or potentially harmful prediction – led to a substantial increase in the Human Ground Truth (GT) Loss Rate, rising from 5.8% to 28.6%. Conversely, instances where the algorithm successfully demonstrated complementarity – providing information that aided human understanding or decision-making – resulted in a significant improvement in the Human GT Gain Rate, increasing from 3.1% to 35.8%. These findings highlight the critical impact of both error types on user trust and the effectiveness of collaborative decision-making processes.
The algorithm employs prediction sets to quantify uncertainty in its predictions, providing a distribution of likely outcomes rather than a single point estimate. Each prediction set contains a range of plausible answers, and associated with each set is a nonconformity score. This score reflects the degree to which a particular prediction deviates from the observed data; higher scores indicate lower confidence. During multi-round dialogues, the algorithm uses these nonconformity scores to identify instances where its uncertainty is high, proactively soliciting input from the LLM-simulated or human agent to refine its predictions and improve collaborative decision-making. This approach facilitates a more robust and reliable outcome by leveraging external knowledge when the algorithm’s internal confidence is low.
![The algorithm effectively converges to track average error [latex]\frac{1}{t}\sum_{i=1}^{t} \mathbf{1}\{\text{Error}_i\}[/latex] for both CH and COMP metrics across various target regimes, demonstrating robust performance in the LLM-simulated medical task.](https://arxiv.org/html/2602.17646v1/figures/appendix-figures/app-llm-convergence-COMP-ch0.05-comp0.25.png)
Towards Robust and Ethical Human-AI Teaming: A Philosophy of Constrained Growth
A novel framework for human-AI collaboration centers on the proactive definition and enforcement of behavioral constraints for artificial intelligence. This approach moves beyond simply optimizing for performance, instead prioritizing ethical considerations and responsible interaction. By explicitly outlining permissible and impermissible actions, the system establishes clear boundaries for the AI, mitigating potential harms and fostering trust. This isn’t achieved through static rules, but a dynamic system allowing adaptation based on context and task requirements. The framework ensures AI contributions remain aligned with human values and intentions, creating a collaborative environment where AI functions as a supportive teammate rather than an autonomous agent operating without ethical guardrails. Ultimately, this constraint-based approach promises to unlock the full potential of human-AI teams while safeguarding against unintended consequences and promoting beneficial outcomes.
The development of truly assistive artificial intelligence hinges on a proactive approach to risk mitigation and capability enhancement, moving beyond simply avoiding errors to anticipating potential harms that could arise from AI actions-counterfactual harms. Researchers are increasingly focused on designing systems that not only perform tasks effectively but also actively work to prevent negative consequences that might not even manifest in typical scenarios. Crucially, this involves maximizing complementarity between human and artificial intelligence; rather than replacing human skills, the goal is to build AI that amplifies them, leveraging distinct strengths to achieve outcomes neither could accomplish alone. This synergistic approach-reducing potential for harm while bolstering human capabilities-is fundamental to creating AI teammates that genuinely augment, rather than diminish, human potential across a spectrum of complex tasks and decision-making processes.
The efficacy of human-AI collaboration hinges on reliable performance, and the principles of dynamic calibration and finite-sample guarantees offer a pathway to achieving this across diverse applications. Dynamic calibration ensures that an AI’s confidence in its predictions accurately reflects its actual correctness, even as the task or data distribution shifts – a crucial attribute for real-world adaptability. Complementing this, finite-sample guarantees establish quantifiable performance bounds based on limited data, addressing a common challenge in machine learning and enabling trustworthy operation even before extensive training. These aren’t merely theoretical concepts; they represent a robust framework applicable to fields ranging from medical diagnosis and autonomous driving to financial modeling and scientific discovery, offering a means to build AI teammates whose capabilities are both predictable and demonstrably reliable, fostering increased trust and effective teamwork.
The development of genuinely collaborative artificial intelligence hinges on creating systems that transcend simple task execution and actively support human cognitive processes. This research demonstrates a pathway towards achieving this goal by focusing on AI teammates capable of bolstering human reasoning and decision-making, particularly within complex and often unpredictable environments. Rather than functioning as mere tools, these AI systems are designed to provide nuanced assistance, offering insights and analyses that complement human expertise. This approach not only enhances the reliability of outcomes but also fosters a greater sense of trust and dependability in the AI’s contributions, ultimately leading to more effective and robust human-AI teams capable of tackling challenges previously insurmountable for either party alone.

The pursuit of seamless human-AI collaboration, as detailed in this framework, often feels like sculpting smoke. Each iteration promises a more harmonious partnership, yet the inherent complexities of defining ‘complementarity’ and mitigating ‘counterfactual harm’ introduce new points of potential failure. This echoes a fundamental truth: systems aren’t built, they evolve. As Marvin Minsky observed, “You can’t make something simpler without making it incomplete.” The attempt to rigorously control the interaction, to guarantee assistance without undermining human capability, isn’t about achieving perfect design, but about establishing a resilient ecosystem capable of adapting to inevitable imperfections and unforeseen consequences. The online learning guarantees aren’t a destination, but a means of navigating the inherent chaos.
What Lies Ahead?
The pursuit of ‘complementarity’ in human-AI systems reveals a familiar paradox. This work establishes a framework for defining when assistance is genuinely valuable, a necessary step. Yet, the very act of codifying ‘helpfulness’ invites a subtle dependency. Each rule, each constraint on counterfactual harm, is a prediction of future brittleness. The system does not solve the problem of collaboration; it merely postpones the inevitable emergence of unforeseen edge cases where defined assistance becomes hindrance. The more precisely one dictates the boundaries of useful intervention, the more fragile the whole becomes.
The guarantees of online learning, while laudable, address only one dimension of a far more complex problem. A system may demonstrably improve its assistance, yet simultaneously erode the user’s underlying skills or critical judgment. The focus naturally drifts toward measurable performance gains, obscuring the less quantifiable cost of diminished human agency. This is not a failing of the technique, but an inherent characteristic of all complex systems: optimization in one area inevitably introduces vulnerabilities elsewhere.
Future work will undoubtedly refine the metrics for ‘complementarity’ and explore more sophisticated methods for uncertainty quantification. But a deeper question remains: can a system truly assist without subtly reshaping the very capabilities it intends to support? The architecture does not offer salvation; it offers a carefully constructed path toward an inevitable, if predictable, form of systemic entanglement.
Original article: https://arxiv.org/pdf/2602.17646.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
2026-02-21 01:43