Author: Denis Avetisyan
New research reveals that even with the rise of AI coding assistants, developer experience continues to dictate how these tools are integrated into daily workflows.
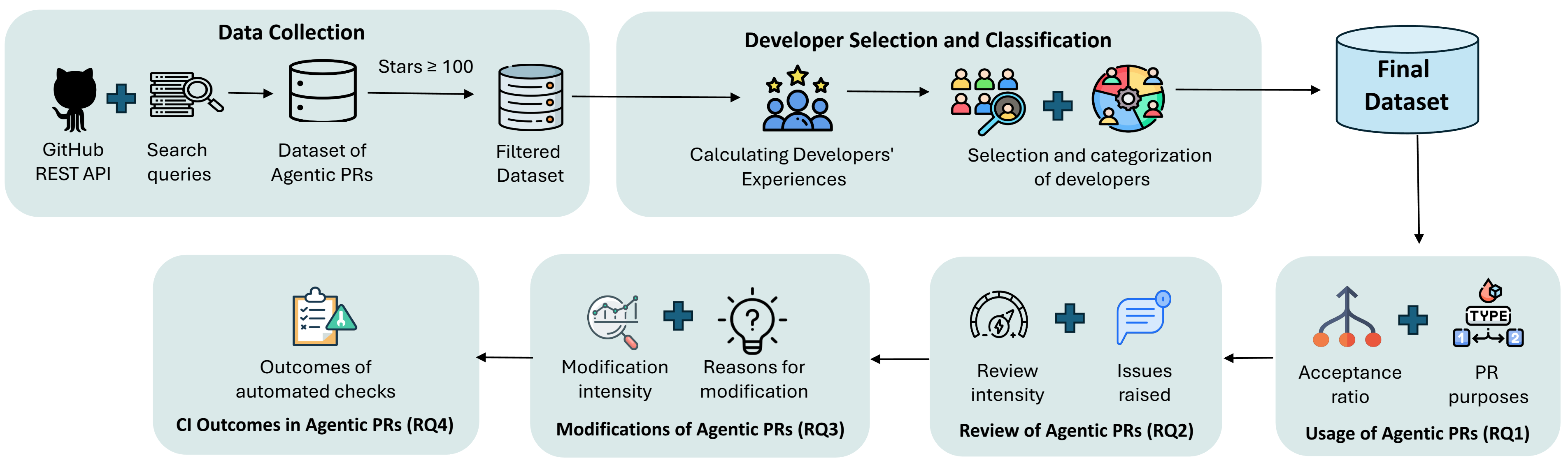
An empirical study demonstrates distinct patterns of coding agent utilization between core and peripheral developers, impacting tasks from code review to CI/CD pipeline integration.
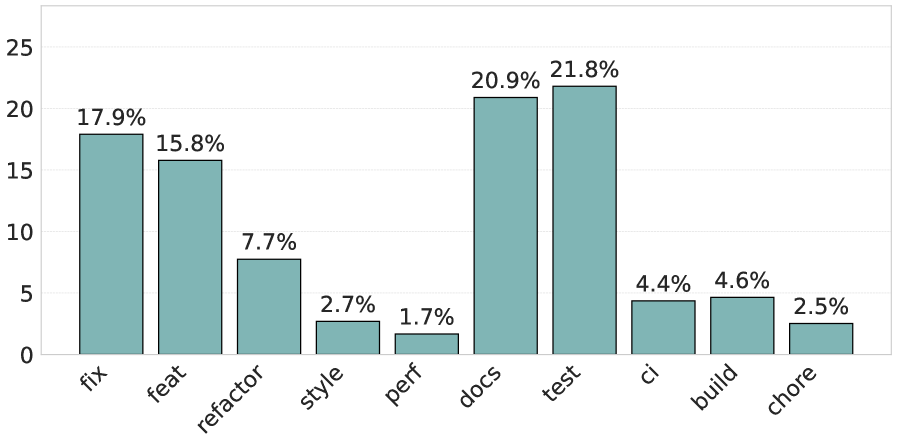
Despite the increasing autonomy of AI-powered coding agents, the extent to which developer experience shapes their adoption remains unclear. This research, titled ‘Are We All Using Agents the Same Way? An Empirical Study of Core and Peripheral Developers Use of Coding Agents’, presents an empirical analysis of [latex]9,427[/latex] agentic pull requests to reveal distinct patterns of use between core and peripheral developers. Our findings demonstrate that while peripheral developers broadly leverage agents for diverse tasks, core developers prioritize quality and maintainability, focusing on documentation and testing-a divergence that impacts code review and verification processes. How can these insights inform the design of more effective human-AI collaboration strategies tailored to varying levels of developer expertise?
The Inherent Fragility of Modern Software
The escalating complexity of modern software projects presents a substantial challenge to development teams. As codebases grow in size and intricacy – often exceeding millions of lines of code – the effort required for even minor modifications increases disproportionately. This isn’t merely a matter of increased typing; understanding the ripple effects of changes across interconnected systems demands significant cognitive load and meticulous review. Consequently, a considerable portion of developer time is now devoted to maintenance and evolution – addressing bugs, refactoring existing code, and adapting to new requirements – rather than creating genuinely new features. This shift in focus impacts innovation velocity and necessitates more efficient tools and methodologies to manage the inherent complexities of large-scale software development, ultimately influencing project timelines and resource allocation.
As software development accelerates, conventional code modification practices are increasingly strained. Manual code reviews, while valuable for quality assurance, become bottlenecks when applied to rapidly evolving and expansive codebases. Similarly, exhaustive manual testing struggles to keep pace with frequent updates, leaving developers with limited capacity to address emerging issues comprehensively. This disparity between the speed of change and the capacity for thorough verification inevitably leads to the accumulation of technical debt – shortcuts taken during development that, while expedient in the short term, create future complications and increase maintenance costs. The result is a codebase that becomes progressively harder to understand, modify, and extend, ultimately hindering innovation and slowing down the delivery of new features.
The escalating complexity of modern software projects often results in a significant impediment to timely releases and novel development. As codebases grow, the process of modification and validation becomes increasingly strained, creating a delivery bottleneck where even small changes require extensive scrutiny and testing. This slowdown isn’t merely a logistical issue; it actively stifles innovation by diverting valuable developer time away from creating new features and exploring groundbreaking ideas. Consequently, there’s a growing need for automated solutions – encompassing techniques like automated testing, continuous integration, and intelligent code analysis – to alleviate this pressure, accelerate the software lifecycle, and unlock the full potential of development teams.
Autonomous Agents: A Paradigm Shift in Code Development
Coding agents signify a shift in software development, employing artificial intelligence to automate the process of identifying and resolving issues within a codebase. These agents operate by autonomously generating and submitting code modifications – known as Pull Requests – without requiring constant human oversight. This differs from traditional methods where developers manually write and test code to address bugs or implement new features. The core functionality relies on AI models interpreting existing code, identifying potential problems, and proposing solutions directly within the development workflow. This autonomous operation aims to increase development speed and efficiency by reducing the time spent on repetitive or easily automated tasks.
Autonomous coding agents function by leveraging large language models (LLMs) specifically trained for code generation and manipulation. Currently utilized models include OpenAI Codex, known for its proficiency in translating natural language into code, Claude Code, which emphasizes contextual understanding and code completion, and Cursor, an agent designed for interactive coding and refactoring. These LLMs are capable of performing tasks such as bug fixing, feature implementation, and code refactoring with minimal human oversight, operating directly within the codebase to propose and implement changes. The agents analyze existing code, identify areas for improvement or new functionality, generate appropriate code modifications, and then submit these changes as Pull Requests for review or, in many cases, direct integration.
Data indicates a high rate of successful autonomous code contributions; 74.1% of Pull Requests submitted by agentic systems were accepted without requiring human modification. This acceptance rate highlights the agents’ capacity to generate code that adheres to existing project standards and functional requirements. Integration with platforms such as GitHub facilitates a complete workflow, automating the process from initial issue detection and code generation, through submission as a Pull Request, and culminating in direct code integration into the codebase without manual intervention.
Automated Workflows and Rigorous Code Validation
Coding agents are designed for direct integration into existing Continuous Integration (CI) pipelines. This integration automates traditionally manual stages of software development, including code building, automated testing, and deployment to various environments. By programmatically triggering these pipeline stages upon code changes, agents reduce cycle times and enable faster iteration. The automation extends to tasks such as running unit tests, integration tests, and static analysis tools, all within the CI framework, thereby providing continuous feedback on code quality and reducing the potential for errors to reach production.
Coding agents enhance code review and collaborative development practices by autonomously generating and submitting Pull Requests. This automation streamlines the contribution process, enabling faster iteration and feedback cycles. The agents’ submissions trigger standard code review workflows, allowing developers to examine proposed changes, provide comments, and suggest improvements before integration. This approach fosters increased participation and knowledge sharing within development teams, leading to more robust and thoroughly vetted codebases. The resulting process is more efficient than manual submissions, and enables a broader range of contributions to be considered.
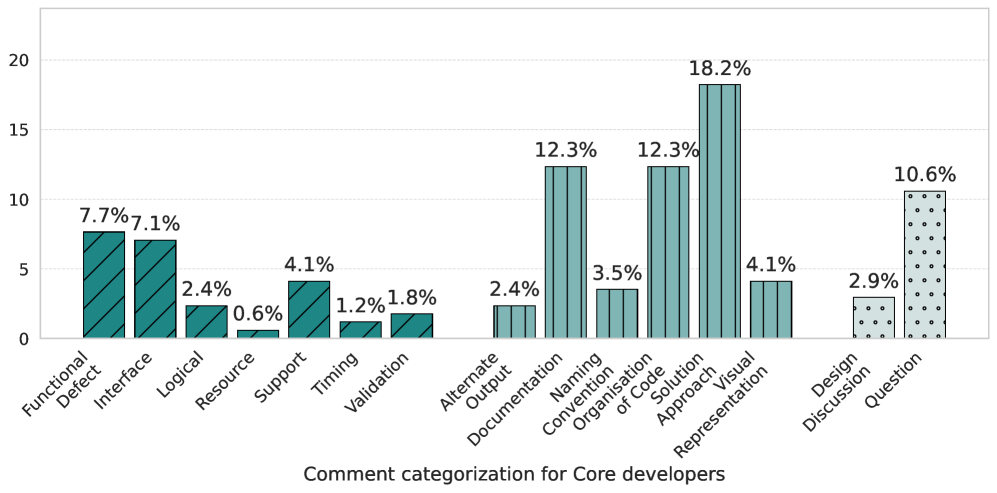
Analysis of Pull Request (PR) modification and validation practices reveals differences in engagement between core and peripheral developers when utilizing coding agents. Core developers modified 28.3% of accepted agentic PRs, a higher rate than the 23.5% observed for peripheral developers. A significant disparity also exists in pre-merge validation; 19.1% of peripheral developers merged agentic PRs without running checks, compared to only 11.2% of core developers. These data suggest that while automation accelerates development, core developers demonstrate greater scrutiny and adherence to quality control processes when integrating agent-generated code contributions.
Cultivating Long-Term Codebase Evolvability
A codebase’s inherent ‘Evolvability’ – its capacity to readily accommodate new features, respond to shifting demands, and integrate innovative technologies – is directly fostered through the consistent application of automated practices. Regular automated bug fixes address immediate issues, preventing the accumulation of technical debt and maintaining system stability. Furthermore, automated refactoring streamlines code structure, enhancing readability and simplifying future modifications. Critically, comprehensive automated testing provides a safety net, ensuring that changes don’t introduce regressions and validating the ongoing functionality of the system. This proactive approach not only reduces the cost and risk associated with updates but also establishes a resilient foundation for sustained innovation, allowing development teams to respond swiftly and effectively to evolving requirements.
Automated documentation processes are increasingly vital for sustaining software projects, directly impacting both long-term maintainability and the efficiency of integrating new developers. By leveraging tools that automatically generate or update documentation from code comments and changes, teams can mitigate the common issue of documentation becoming outdated or diverging from the actual codebase. This proactive approach reduces the cognitive load on developers attempting to understand existing systems, enabling quicker bug fixes and feature implementations. Consequently, onboarding new team members becomes significantly less resource-intensive, as readily available and accurate documentation accelerates their learning curve and allows them to contribute meaningfully sooner, ultimately lowering associated costs and fostering a more agile development environment.
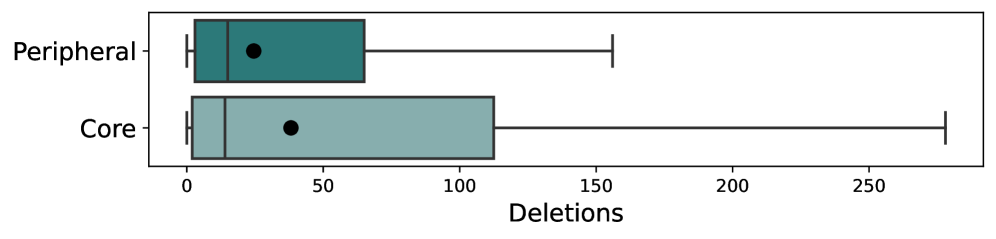
Statistical analysis revealed a measurable impact of enhanced codebase evolvability on developer workflows. A Mann-Whitney-Wilcoxon test, comparing developer groups, yielded a Cliff’s Delta of 0.28, signifying a small, yet statistically relevant, difference in the volume of review comments-indicating more streamlined and comprehensible code changes. Crucially, high inter-coder reliability, assessed via Cohen’s Kappa scores ranging from 80.3% to 82.5%, confirms substantial agreement in code evaluations, bolstering the validity of these findings. This improved adaptability isn’t merely academic; it directly fosters faster innovation cycles, actively mitigates the accumulation of technical debt, and ultimately contributes to a discernible competitive advantage for organizations prioritizing long-term software health.
The study illuminates a predictable divergence in developer approaches, mirroring established patterns of expertise. Even with the advent of coding agents, core developers maintain a rigorous focus on code quality and long-term maintainability-a dedication to provable correctness. This resonates with Claude Shannon’s assertion: “The most important thing in communication is to convey the meaning without losing it.” Similarly, in software engineering, the agent’s assistance must not compromise the fundamental clarity and reliability of the code. The research shows peripheral developers embracing agents more broadly, highlighting a practical need for assistance across varied tasks-a pragmatic adaptation to tool availability. This difference isn’t a flaw, but rather demonstrates a healthy specialization within the development lifecycle, prioritizing determinism and verifiable results.
What Remains to be Proven?
The observation that developer experience continues to mediate interaction with coding agents is less a novel finding and more a confirmation of a fundamental principle. The tools change, the abstractions shift, but the human element-specifically, the ingrained habits of thought-remains stubbornly persistent. The distinction between ‘core’ and ‘peripheral’ developers, while empirically observed, demands a more rigorous theoretical grounding. Is this merely a matter of skill, or does it reflect a deeper cognitive divergence in how developers approach problem-solving? A truly elegant solution would move beyond descriptive categorization and provide a predictive model of agent usage based on demonstrable cognitive traits.
Current evaluations of coding agents largely rely on proxy metrics – pull request size, CI/CD pass rates – which, while convenient, lack mathematical precision. The claim that an agent ‘improves’ productivity requires a formal definition of productivity, ideally expressed as a provable reduction in algorithmic complexity or a guaranteed improvement in code maintainability. Absent such rigor, assertions of efficacy remain, at best, strong conjectures.
Future work should focus not merely on whether agents are used, but on how they alter the very process of software development. Does reliance on these tools lead to a homogenization of coding styles, or does it exacerbate existing differences? And, crucially, can we mathematically prove that agent-assisted development results in demonstrably superior software, or are we simply building more complex systems on foundations of unverified assumptions?
Original article: https://arxiv.org/pdf/2601.20106.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Call the Midwife season 16 is confirmed – but what happens next, after that end-of-an-era finale?
- Robots That React: Teaching Machines to Hear and Act
- Taimanin Squad coupon codes and how to use them (March 2026)
- PUBG Mobile collaborates with Apollo Automobil to bring its Hypercars this March 2026
- Heeseung is leaving Enhypen to go solo. K-pop group will continue with six members
- Jessie Buckley unveils new blonde bombshell look for latest shoot with W Magazine as she reveals Hamnet role has made her ‘braver’
- Overwatch Domina counters
- Peppa Pig will cheer on Daddy Pig at the London Marathon as he raises money for the National Deaf Children’s Society after son George’s hearing loss
- Genshin Impact Version 6.4 Stygian Onslaught Guide: Boss Mechanism, Best Teams, and Tips
- Clash Royale Chaos Mode: Guide on How to Play and the complete list of Modifiers
2026-01-30 01:51