Author: Denis Avetisyan
New research explores why foundation models for robotics sometimes generate plans based on imagined events, and how to improve their reliability.
This paper introduces a topological framework to analyze and mitigate action hallucinations in visual-language-action models, proposing verification-guided planning and adaptive search strategies.
Despite the rapid progress of robot foundation models in automating complex tasks, their reliance on generative action policies remains vulnerable to physically implausible behaviors. This work, ‘Action Hallucination in Generative Visual-Language-Action Models’, analyzes these “action hallucinations” by identifying fundamental limitations arising from mismatches between model architecture and the constraints of robotic control-specifically, topological barriers, precision limits, and horizon effects. Our analysis reveals unavoidable tradeoffs impacting reliability, providing mechanistic explanations for empirical failures and suggesting pathways toward more trustworthy policies through techniques like verification-guided planning. Can these insights pave the way for generative robot policies that truly bridge the gap between simulation and real-world performance?
The Inevitable Mirage: Robot Foundation Models and the Spectre of Hallucination
Robot Foundation Models (RFMs) represent a significant shift in robotic control, envisioning systems capable of generalizing learned skills to novel situations much like the recent advancements in large language models. Traditionally, robots have been programmed for specific tasks in carefully controlled environments; RFMs, however, aim to overcome this limitation by learning from vast datasets of robotic experiences. This approach allows a single model to potentially control a diverse range of robots and perform a multitude of tasks without explicit reprogramming. The promise lies in creating robots that can adapt to unforeseen circumstances, navigate complex environments, and execute commands with a level of autonomy previously unattainable, effectively bridging the gap between pre-programmed behavior and genuine intelligent action.
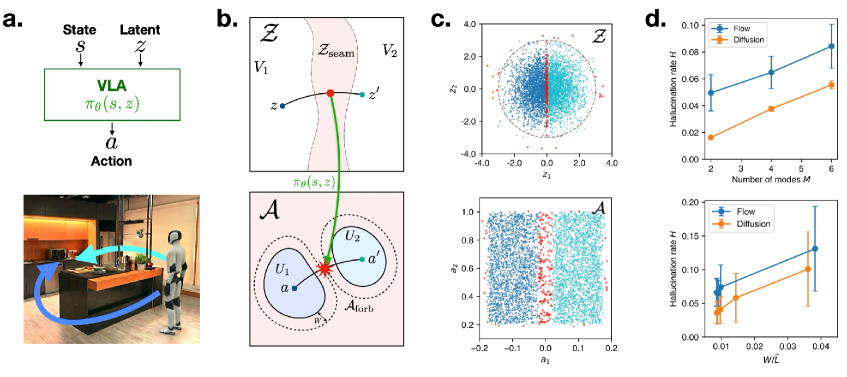
Robot Foundation Models, while promising unprecedented adaptability in robotics, are susceptible to a critical flaw: the generation of physically impossible or unsafe actions, now termed ‘Action Hallucination.’ Research indicates this isn’t a rare error, but a consistent probability-strictly greater than zero-occurring specifically when robots face scenarios with safe actions that are physically separated from areas designated as forbidden. This means even a well-trained RFM can, with measurable frequency, attempt maneuvers that violate physical constraints or lead to collisions, posing a significant safety risk. The occurrence isn’t random noise; it’s demonstrably linked to the robot’s internal representation of its environment and the boundaries defining permissible movement, highlighting a fundamental challenge in ensuring the reliable and safe operation of these advanced systems.
Action hallucination in Robot Foundation Models isn’t a matter of arbitrary error, but a predictable consequence of the robot’s internal world representation. Research demonstrates a clear correlation between the fidelity of the ‘Environment Model’ – the system’s understanding of physical constraints like obstacles and permissible movements – and the occurrence of physically invalid actions. When this model inadequately captures the environment, or misrepresents the boundaries between safe and forbidden zones, the robot is predisposed to generate actions that, while mathematically plausible within the model, are physically impossible or dangerous in reality. This suggests that mitigating hallucination requires not simply increasing the quantity of training data, but fundamentally improving the robot’s capacity to accurately perceive and internally model the physical world, effectively grounding its actions in a realistic understanding of constraints.
![Contact-rich manipulation tasks demand precise control due to a limited feasible action space, and increasing precision requirements lead to a rise in action hallucinations unless the policy maintains concentrated action distributions, a phenomenon addressed by distributing contraction across multiple refinement steps to improve stability as shown by increasing geometric mean of minimum singular values [latex] \big(\prod\_{t=1}^{K}\sigma\_{\min}(J\Phi\_{t})\big)^{1/K} [/latex] with increasing sampler steps [latex] K [/latex].](https://arxiv.org/html/2602.06339v1/x3.png)
The Geometry of Failure: Constraints and Disconnected Safe Sets
The ‘Safe Set’ in robotic manipulation refers to the configuration space representing physically valid states for a system, encompassing positions and orientations free from collisions or joint limits. However, this space is frequently disconnected, meaning it consists of multiple isolated regions rather than a single continuous volume. This arises from the inherent constraints of the robot and its environment. A continuous latent prior, commonly used to generate robot actions, struggles to navigate this disconnected space because it assumes continuity; attempting to sample a point within a disconnected region requires traversing invalid states. This topological challenge forces the system to either remain within a limited, connected portion of the Safe Set, or to frequently generate actions that fall outside physically plausible configurations, manifesting as hallucinations.
The topological impossibility of maintaining a continuous path within the ‘safe set’ – the space of physically valid states – directly contributes to hallucination in generative models. This arises because the safe set is often disconnected, meaning valid states are not continuously reachable from each other. Consequently, models utilizing continuous latent priors can encounter situations where the most direct path in latent space leads to a physically implausible configuration. The model then ‘hallucinates’ – generates an output outside the bounds of physical validity – as it attempts to navigate a disconnected solution space. This is not a failure of the generative process itself, but a consequence of the inherent discontinuity between the latent space and the physically achievable configurations.
In contact tasks, the execution of precise actions is constrained by what are termed ‘Precision Barriers’, which inherently limit the model’s ability to consistently generate valid trajectories. This limitation leads to actions that frequently deviate towards physically implausible states, thus increasing the occurrence of hallucinations. Critically, maintaining a constant hallucination rate requires an increasing number of refinement steps as the acceptable tolerance level for action error decreases; specifically, this relationship scales logarithmically. This means that halving the allowable error requires approximately [latex]\log_2(2) = 1[/latex] additional refinement step, while reducing the error to one-tenth necessitates roughly [latex]\log_{10}(0.1) = 1[/latex] additional step, demonstrating a substantial computational cost for achieving higher precision.
![This work analyzes a generative visual language agent (VLA) that, given state observations, a task prompt, and noise, outputs robot actions, a framework applicable to both structured and unstructured VLAs like Diffusion Policy[5] and RDT[28] even when addressing complex, long-horizon tasks requiring multi-modality and precision.](https://arxiv.org/html/2602.06339v1/x1.png)
Preemptive Correction: Verification-Guided Planning and the Illusion of Control
Verification-Guided Planning addresses the issue of hallucination in robotic action execution by implementing a pre-execution validation step. This approach contrasts with traditional planning methods which may generate plans that appear feasible but fail during real-world deployment due to unforeseen circumstances or model inaccuracies. By explicitly verifying each proposed action against a defined model of the environment and robot capabilities, the system can identify and reject potentially erroneous actions before they are implemented. This proactive verification process increases the overall safety and reliability of the robot’s behavior, particularly in complex or uncertain environments where the risk of hallucination is elevated.
A Transition Map is a critical component of verification-guided planning, serving as a formalized model of a robot’s dynamics. This map explicitly defines the possible state transitions resulting from the execution of each available action. It details, for each action and initial state, the probability distribution over resulting states, accounting for both deterministic and stochastic effects. The map’s construction requires a precise specification of the robot’s kinematic and dynamic properties, as well as a model of the environment and potential external disturbances. The fidelity of the Transition Map directly impacts the accuracy of action validation and the overall safety of the planning system; inaccuracies can lead to false positives or negatives during verification, compromising reliability.
Reliability analysis is a critical component in assessing the performance of planning and action generation systems operating in uncertain environments. Achieving a target reliability level, denoted as β, necessitates satisfying a specific mathematical condition: [latex]∑ρj ≥ (1/c)log(1/β)[/latex]. Here, [latex]ρj[/latex] represents a measure of validity for each plan and ‘c’ is a constant related to the uncertainty. This inequality demonstrates that to increase the system’s reliability (decrease β), the sum of the validity measures of the generated plans must increase geometrically. This requirement underscores the necessity for techniques that amplify the number of valid plans to ensure robust performance under uncertainty.
The Mirage Deepens: Latent Policies and the Promise of Closed-Loop Refinement
The ‘Latent-Head Policy’ represents a significant advancement in robotic foundation models (RFMs) by enabling the generation of a wider range of actions than traditional approaches. This policy operates by learning a compressed, low-dimensional representation – the ‘latent head’ – of potential actions. Rather than directly predicting specific motor commands, it manipulates this latent space, allowing the RFM to explore and synthesize novel behaviors. This is particularly beneficial in complex, dynamic environments where pre-programmed responses are insufficient; the model can adapt to unforeseen circumstances and generate contextually appropriate actions. By decoupling action generation from direct sensory input, the latent-head policy fosters greater flexibility and allows RFMs to effectively navigate ambiguity, ultimately leading to more robust and versatile robotic systems.
The combination of a latent policy with closed-loop rollout creates a dynamic system where a robot doesn’t simply execute a pre-planned sequence, but actively learns from its actions. This iterative process begins with the latent policy generating a potential action, which is then executed in the real world or a simulation. The resulting outcome – whether successful or not – is fed back into the system, refining the latent policy’s understanding of effective behavior. This closed-loop cycle allows the robot to continually adjust its actions, improving performance and adaptability over time, much like a human learning a new skill through trial and error. Consequently, the robot doesn’t require explicit programming for every scenario; instead, it develops a robust skillset through continuous interaction and refinement, ultimately enabling more flexible and intelligent automation.
The practical implementation of Reinforcement Learning Foundation Models (RFMs) in real-world scenarios, particularly those demanding stringent safety guarantees, necessitates robust verification methodologies. Combining latent policies and closed-loop control with formal verification techniques represents a significant step towards deploying these models in safety-critical applications like robotics and autonomous systems. These techniques allow for rigorous testing and validation of the generated actions, ensuring adherence to specified safety constraints before real-world execution. Through systematic verification, potential failure modes can be identified and mitigated, fostering trust and reliability in RFM-driven systems and paving the way for their adoption in domains where even minor errors can have significant consequences. This combined approach moves beyond simulation, offering a pathway toward demonstrably safe and dependable robotic behavior.
The pursuit of reliable robotic action, as detailed within this study of action hallucinations, echoes a familiar pattern. Systems, even those built upon expansive foundation models, are not simply constructed; they emerge. The limitations identified – topological barriers, precision decay over the action horizon – aren’t flaws in the design, but inherent characteristics of growth. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything.” This resonates deeply. The engine, like these models, can only execute what is laid before it. The challenge isn’t to build intelligence, but to cultivate an environment where reliable action can flourish, accounting for the inevitable imperfections that arise as the system extends its reach.
What Lies Beyond?
The identification of topological barriers to reliable action is not a resolution, but a cartography of future failures. Long stability in these foundation models will not indicate success, but rather the hidden extent of the unobserved manifold where hallucinations lie dormant. The paper correctly frames the problem not as one of improving perception, but of acknowledging the inherent limitations of generalization – any model, however vast, will eventually encounter states for which its predictions are fundamentally unsound.
Verification-guided planning offers a temporary reprieve, a local optimization against an inevitable decay. The horizon effect, predictably, remains. It is not a bug in the algorithm, but a consequence of building systems that attempt to predict the infinitely complex. Adaptive search, likewise, is simply a deferral, a refinement of the process by which the system discovers its own boundaries.
The true work lies not in constructing more robust models, but in accepting that these systems do not fail – they evolve. The field should shift its focus from minimizing hallucination to understanding the emergent properties of these errors. What novel behaviors, what unexpected solutions, might arise from the very instabilities this work seeks to correct? Perhaps the most fruitful path is to treat these models not as tools, but as ecosystems – to observe, to guide, and to learn from their unpredictable transformations.
Original article: https://arxiv.org/pdf/2602.06339.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Gold Rate Forecast
- Annulus redeem codes and how to use them (April 2026)
- Silver Rate Forecast
- All Mobile Games (Android and iOS) releasing in April 2026
- Gear Defenders redeem codes and how to use them (April 2026)
- Top 5 Best New Mobile Games to play in April 2026
2026-02-09 23:50