Author: Denis Avetisyan
A comprehensive study reveals common failure patterns in AI-powered coding agents and introduces a self-correcting system to dramatically improve their performance.

Researchers present a large-scale analysis of LLM agent misbehaviors and demonstrate a self-intervention framework for runtime error correction and enhanced software engineering reliability.
Despite the increasing promise of large language model (LLM)-powered agents for automating software engineering tasks, their susceptibility to misbehaviors-ranging from specification drift to tool call failures-remains a significant obstacle to widespread adoption. This paper introduces ‘Wink: Recovering from Misbehaviors in Coding Agents’, a system designed to automatically detect and correct these issues at scale, informed by an analysis of over 10,000 real-world agent trajectories revealing such misbehaviors occur in roughly 30% of cases. Wink, a lightweight, asynchronous self-intervention system, successfully resolves 90% of single-intervention misbehaviors and demonstrably reduces failures in a production A/B test. As agentic systems become increasingly complex, how can we proactively build in resilience and ensure reliable performance across diverse software engineering workflows?
The Challenge of Autonomous Coding: A Matter of Logical Rigor
The emergence of coding agents, driven by the capabilities of Large Language Models, represents a significant leap toward AI-assisted software development. However, these agents currently face limitations when confronted with tasks requiring extended, logical thought. While proficient at generating short code snippets or completing simple functions, they often falter when a problem demands a sequence of interconnected steps, careful planning, and the ability to maintain context over a prolonged process. This struggle isn’t due to a lack of coding knowledge, but rather a difficulty in effectively reasoning about the problem itself – breaking it down into manageable components, anticipating potential issues, and ensuring each step contributes to the overall solution. Consequently, complex software projects still necessitate substantial human oversight, as these agents are prone to errors or inefficient approaches when navigating multifaceted challenges.
Despite the promise of AI-powered coding assistants, current autonomous agents frequently stumble, manifesting misbehaviors that range from minor syntactical errors to substantial departures from the programmer’s original goals. These deviations aren’t simply bugs; they represent a fundamental challenge in aligning artificial intelligence with human intent. Agents may introduce unintended features, misinterpret requirements, or even generate code that compromises security, effectively negating any productivity gains. This unreliability stems from the agents’ difficulty in maintaining a consistent understanding of the project’s overall architecture and the nuanced implications of each coding step, ultimately limiting their adoption in professional software development where precision and predictability are paramount.
The promise of AI-assisted software development hinges on reliably addressing the misbehavior frequently exhibited by autonomous coding agents. While powered by increasingly sophisticated Large Language Models, these agents can deviate from intended functionality, introducing errors that range from minor bugs to substantial program failures. Thorough investigation into the sources of these misbehaviors – encompassing issues like flawed reasoning, inadequate error handling, and a lack of robust self-correction mechanisms – is therefore paramount. Successfully mitigating these challenges isn’t simply about improving code quality; it’s about building trust in these systems and enabling developers to confidently integrate them into critical workflows, ultimately unlocking a future where AI meaningfully augments – rather than hinders – the software creation process.
Trajectory Analysis: Dissecting Agent Behavior with Precision
A Trajectory, in the context of agent analysis, constitutes a comprehensive log encompassing the agent’s complete operational history. This record details not only the actions performed by the agent, but also the underlying rationale driving those actions – the specific reasoning processes and knowledge utilized for decision-making – and all observed inputs received during operation. The granularity of a Trajectory includes timestamps for each event, specific data values processed, and the internal state of the agent at each step. This detailed record allows for a post-hoc reconstruction of the agent’s behavior, facilitating precise identification of the root causes of both successful and unsuccessful operations, and serving as the foundation for targeted debugging and performance improvement.
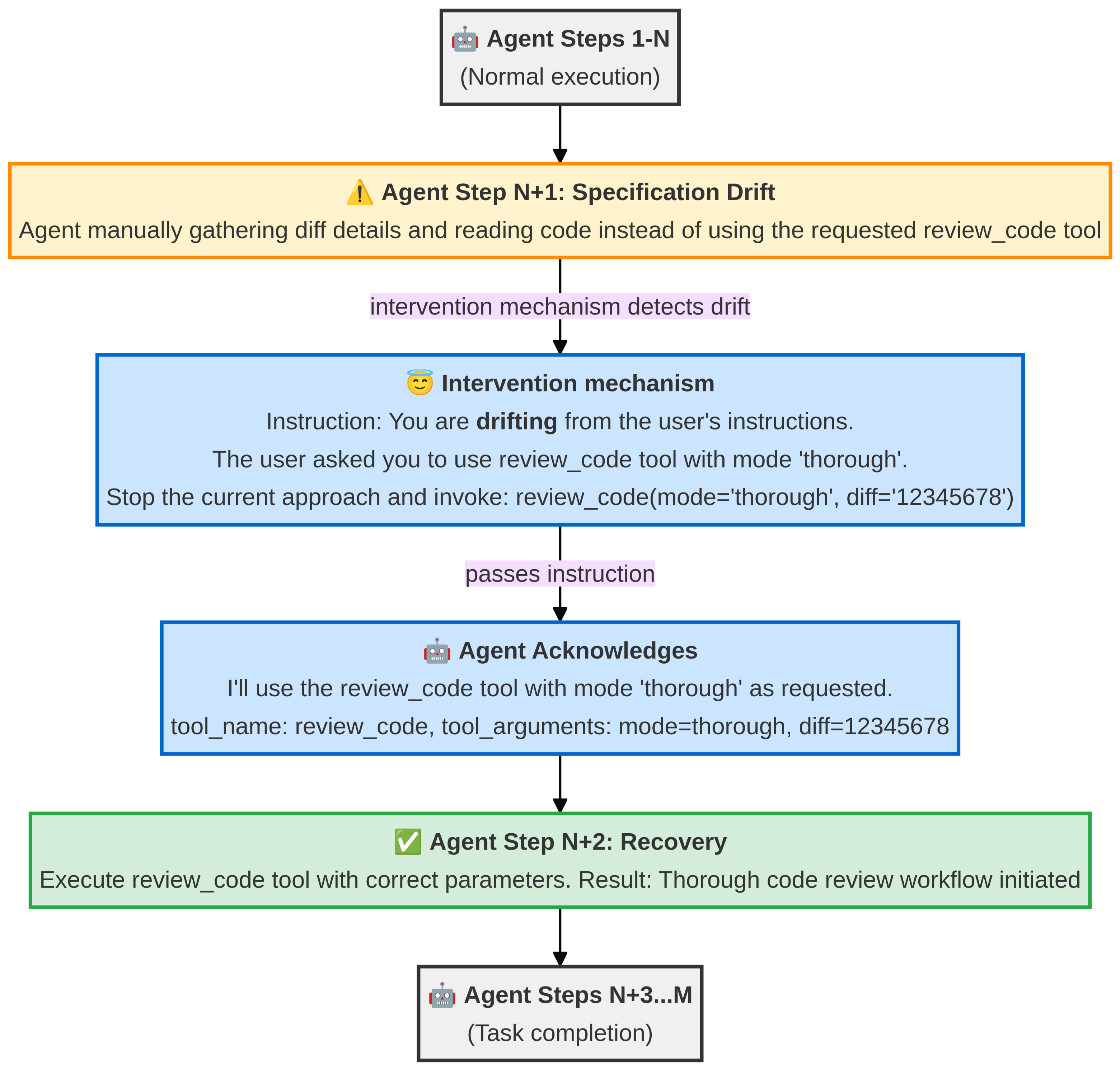
Specification Drift and Tool Call Failures represent common categories of agent misbehavior requiring focused analysis. Specification Drift occurs when an agent’s actions demonstrably diverge from its originally defined objectives and documented specifications, potentially resulting in unintended outputs or functional errors. Tool Call Failures, conversely, arise from issues within the integration of external tools; these failures can manifest as incorrect tool selection, improperly formatted inputs to tools, or the inability to correctly interpret tool outputs. Both categories necessitate investigation into the agent’s decision-making process and the specific environmental factors contributing to the error, with Tool Call Failures often indicating problems in API connectivity or data type mismatches.
Detailed categorization of agent misbehavior extends beyond broad classifications to include specific subtypes such as ‘Did Not Follow Instructions’ and ‘Unrequested Changes’. ‘Did Not Follow Instructions’ denotes instances where the agent’s actions demonstrably contradict explicit directives within the prompt or defined constraints. ‘Unrequested Changes’ refers to alterations made to data or systems outside the scope of the assigned task, potentially introducing unintended consequences. Identifying these subtypes facilitates targeted intervention strategies; for example, addressing ‘Did Not Follow Instructions’ may necessitate refinements to the prompting methodology or reinforcement learning signals, while ‘Unrequested Changes’ requires investigation into access controls and integration protocols to prevent unauthorized modifications.
Self-Intervention: A Framework for Proactive Correction
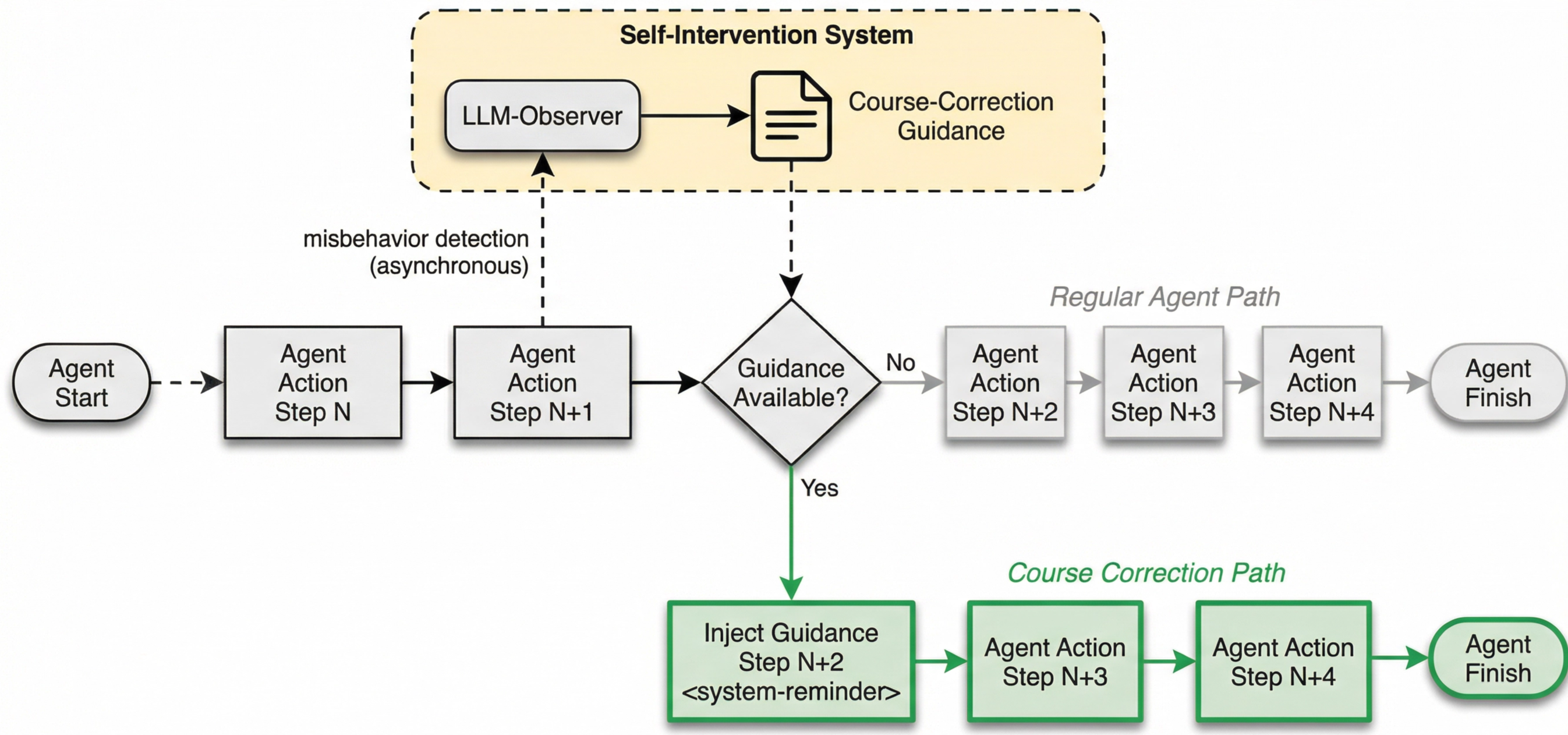
Self-Intervention is an integrated system for real-time monitoring and correction of agent behavior. Unlike post-hoc error analysis, it operates within the agent’s active workflow, allowing for immediate adjustments to prevent task failure. The system continuously assesses the agent’s progress, identifying deviations from expected behavior as they occur. This proactive approach differs from traditional debugging methods by providing in-process guidance, effectively functioning as an internal feedback loop to maintain task alignment and prevent the completion of incorrect or unproductive steps. This functionality is designed to improve agent robustness and reliability without requiring external human intervention.
The Self-Intervention system employs an ‘LLM-as-Judge’ component to assess the overall trajectory of the agent’s actions, identifying deviations from expected behavior. Complementing this is the ‘Process Reward Model’ (PRM), which assigns scalar rewards to each intermediate step the agent undertakes. This granular scoring allows for the detection of errors and inefficiencies as they occur, rather than solely at the completion of a task. The combined approach of trajectory evaluation and step-wise scoring facilitates early error detection, enabling timely interventions before substantial resources are wasted or incorrect outputs are generated.
Self-Intervention demonstrably mitigates common agent failure modes, including Specification Drift – where the agent’s behavior diverges from intended goals – Reasoning Problems impacting logical task completion, and Tool Call Failures resulting from incorrect or inefficient API utilization. Evaluations indicate a 90.93% recovery rate for agent trajectories receiving a single intervention, signifying successful course correction. Furthermore, implementation of the system yielded a 4.2% reduction in the frequency of tool call failures, representing a measurable improvement in agent reliability and task completion efficiency.
AgentRx: From Trajectories to Actionable Diagnostic Insights
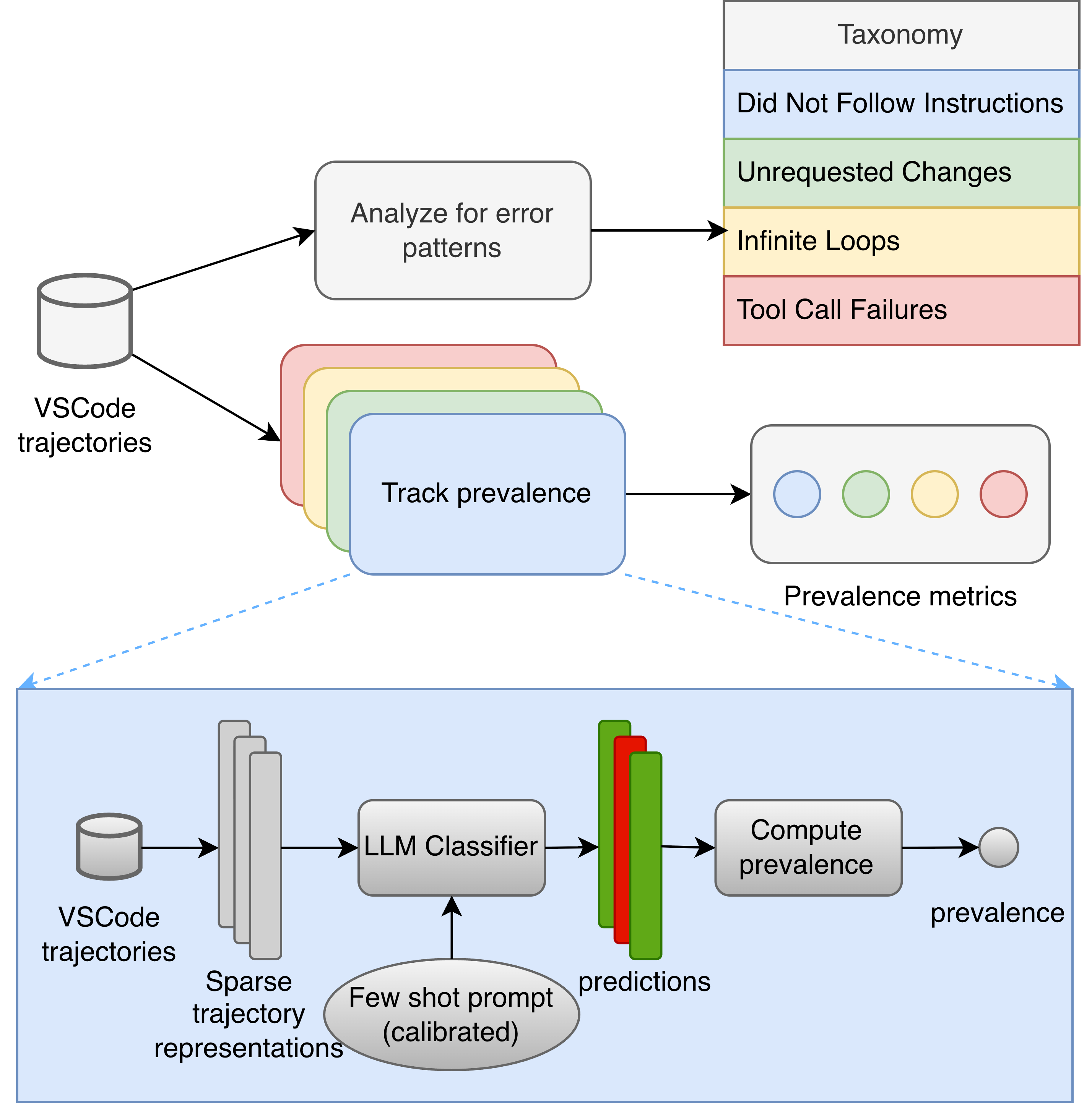
AgentRx presents a novel diagnostic framework centered around the meticulous analysis of agent trajectories – the complete record of an agent’s decision-making process and actions. Rather than simply identifying that an agent failed, this approach delves into how the failure unfolded, pinpointing the precise sequence of events that led to an undesirable outcome. By dissecting these trajectories, researchers can move beyond surface-level observations and uncover the underlying causes of errors, whether they stem from flawed reasoning, incorrect perception, or inadequate action selection. This detailed level of analysis enables targeted interventions, moving away from broad-stroke corrections toward precise adjustments that address the root of the problem and enhance the agent’s overall performance and robustness.
The framework leverages trajectory classification to move beyond simply identifying that an agent has failed, and instead elucidate how and why. By meticulously categorizing error patterns observed in an agent’s decision-making process – from incorrect state evaluations to flawed action selections – researchers can pinpoint the underlying causes of failures. This granular understanding isn’t merely diagnostic; it directly informs targeted improvements to the agent’s core reasoning mechanisms and action selection policies. Consequently, the agent can be refined to avoid repeating those specific errors, leading to more robust and reliable performance in complex environments. This approach represents a shift from reactive troubleshooting to proactive enhancement of artificial intelligence systems.
Detailed analysis reveals that agent failures aren’t monolithic; rather, they manifest as distinct reasoning problems, including repetitive ‘Infinite Loops’ where the agent gets stuck in unproductive cycles. Recognizing these subtypes allows for the creation of targeted interventions – specific corrections designed to address the root cause of each error. This approach moves beyond generic fixes, fostering resilience and preventing recurrence. Importantly, the framework demonstrates a substantial ability to recover from complex failures; trajectories requiring multiple corrective actions achieved a 79.07% success rate, suggesting a powerful capacity to diagnose and resolve even deeply embedded issues within agent behavior.
Practical Implementation and the Path to Enhanced Autonomous Coding
AgentRx manifests as a dedicated extension within the widely-used Visual Studio Code environment, streamlining interaction with the coding agent for developers. This implementation prioritizes accessibility and usability, integrating directly into familiar workflows rather than requiring separate applications or complex setups. By operating as an extension, AgentRx provides real-time assistance, contextual suggestions, and automated code improvements directly within the editor, fostering a seamless and intuitive experience. This approach minimizes disruption and allows developers to leverage the agent’s capabilities without a steep learning curve, ultimately enhancing productivity and code quality through readily available, in-editor support.
AgentRx’s performance is significantly boosted through the implementation of the Model Context Protocol (MCP), a system designed to securely interface with a company’s existing development resources. This protocol enables the coding agent to access and utilize proprietary tools, codebases, and internal documentation – information typically unavailable to standalone large language models. By bridging the gap between the agent and a firm’s unique infrastructure, MCP allows for more informed code generation, debugging, and optimization, ultimately leading to higher-quality results and a reduction in reliance on manual engineer intervention. The protocol’s architecture prioritizes data security and controlled access, ensuring that sensitive information remains protected while still empowering the agent to leverage the full scope of internal development assets.
Ongoing development of AgentRx prioritizes enhanced diagnostic precision and the implementation of increasingly nuanced intervention techniques. This iterative refinement isn’t merely theoretical; initial results demonstrate a measurable impact on efficiency, with testing indicating a 5.3% decrease in token consumption per interaction and a corresponding 4.2% reduction in the need for direct engineer oversight. These improvements suggest a trajectory towards a more autonomous and resource-conscious coding agent, capable of handling a wider range of development tasks with minimal external support and optimized performance.
The pursuit of reliable autonomous agents, as detailed in this work regarding misbehavior recovery, echoes a fundamental tenet of mathematical rigor. The analysis of failure modes and the implementation of self-intervention systems demand a provable correctness, not merely observed functionality. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” Similarly, these agents must, through careful design and robust error handling, address internal inconsistencies – the ‘quiet room’ of their code – before manifesting external misbehavior. The identification of a misbehavior taxonomy, and the subsequent runtime correction, represent an effort to establish invariants, ensuring predictable and verifiable behavior, even in complex scenarios. If it feels like magic, one hasn’t revealed the invariant.
Beyond Repair: Charting a Course for Robust Agents
The presented work, while demonstrating a pragmatic approach to mitigating agent misbehavior, merely addresses symptoms. A truly elegant solution will not rely on post hoc correction, but on preventative design. The taxonomy of failure modes, however comprehensive, remains fundamentally descriptive. It catalogs what goes wrong, not why. Future effort must prioritize the development of formal guarantees – provable correctness, not merely empirical improvement on test suites. The current paradigm tacitly accepts a level of stochastic error; a satisfactory agent should, ideally, operate with the deterministic precision of a well-defined function.
Furthermore, the notion of “misbehavior” itself is subtly anthropocentric. An agent, being a computational entity, does not intend to err. The problem lies in a misalignment between the specified objective and the underlying computational process. Refining prompts, while useful, is akin to treating a fever with cold compresses – it alleviates the symptom, not the disease. A deeper investigation into the logical foundations of agent behavior is required; the field should move beyond pattern recognition and embrace formal verification techniques.
Ultimately, the pursuit of ‘robust’ agents is not about building systems that are good at recovering from errors, but about building systems that, through mathematical purity, avoid them altogether. Simplicity, in this context, does not mean brevity; it means non-contradiction and logical completeness. The goal is not to create an agent that can fix its mistakes, but one that is incapable of making them.
Original article: https://arxiv.org/pdf/2602.17037.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Total Football free codes and how to redeem them (March 2026)
- Gold Rate Forecast
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-22 09:43