Author: Denis Avetisyan
Researchers have developed a system that allows web-navigating agents to learn more efficiently by simulating online experiences, reducing the need for constant real-world interaction.
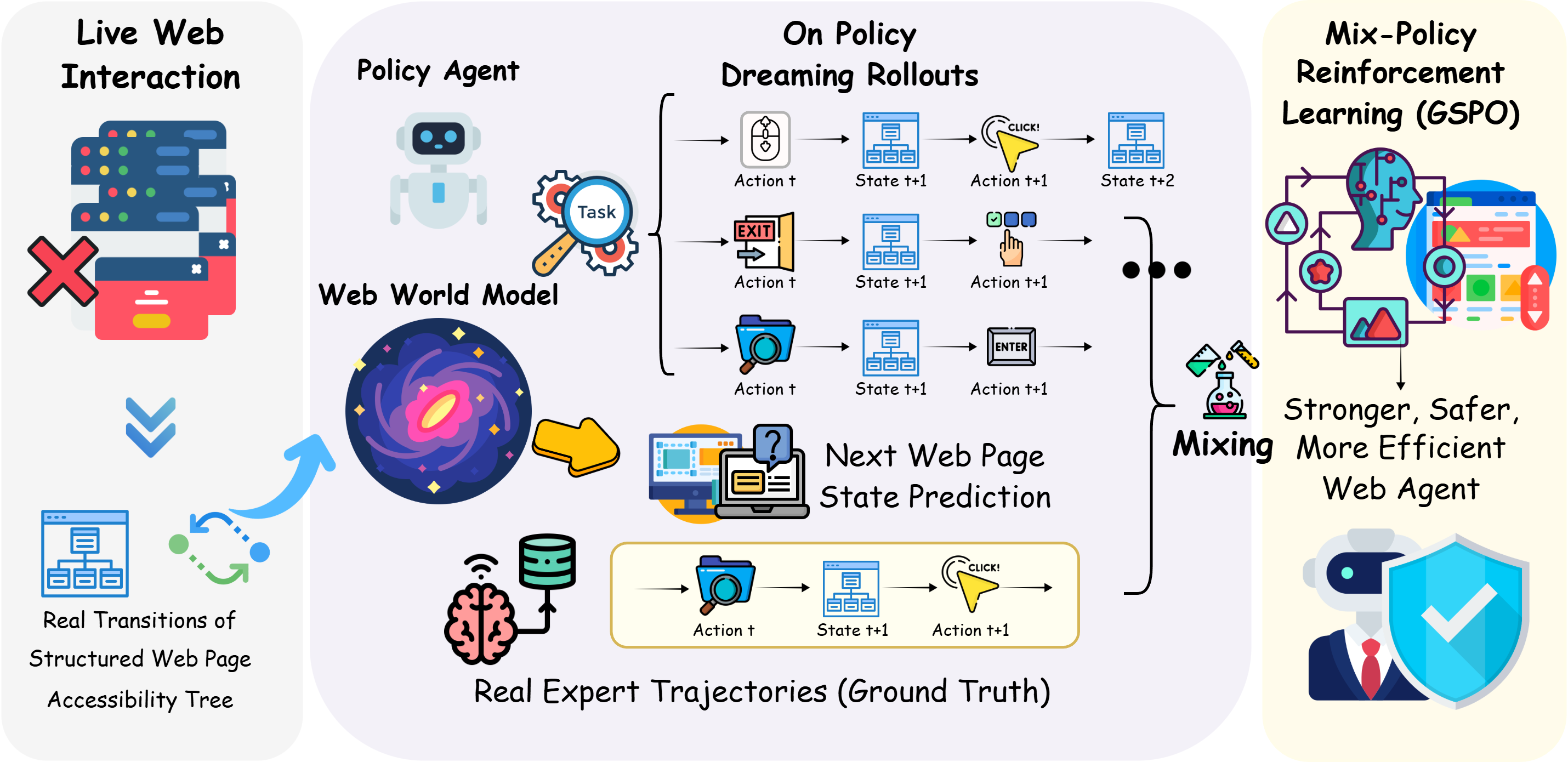
DynaWeb leverages model-based reinforcement learning and learned web world models to train agents using imagined trajectories and accessibility trees.
Training autonomous web agents with reinforcement learning is hindered by the inefficiencies and risks of direct interaction with the live internet. This paper introduces ‘DynaWeb: Model-Based Reinforcement Learning of Web Agents’, a novel framework leveraging a learned world model of the web to enable efficient, simulated experience generation. By training agents through ‘imagination’-generating rollouts within this model and combining them with real expert data-DynaWeb significantly improves performance on challenging web navigation benchmarks. Could this approach unlock a scalable path towards truly general-purpose, online agentic AI?
The Web’s Unending Horizon: A Systemic Challenge
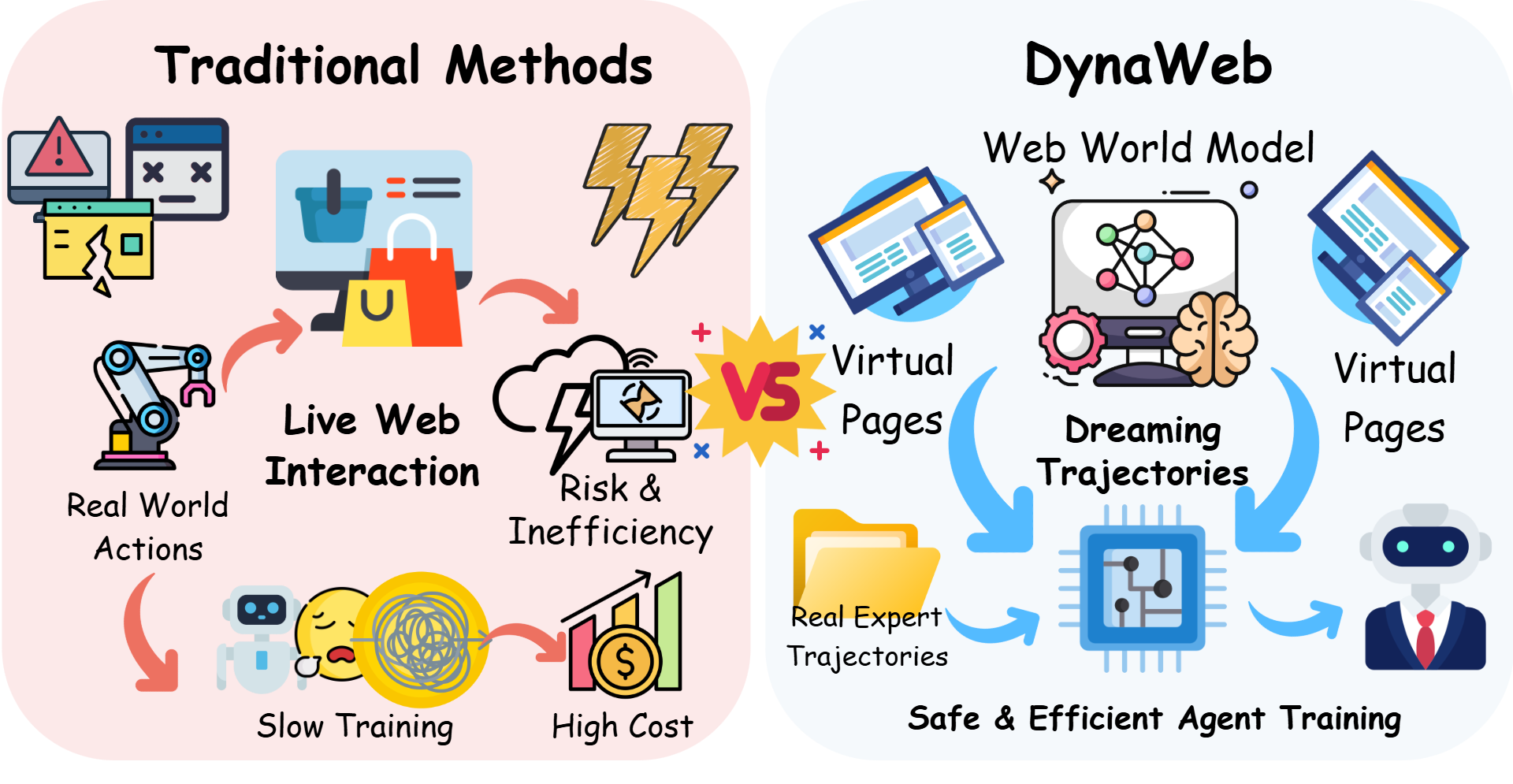
The sheer scale and constant flux of the World Wide Web present a significant hurdle for traditional reinforcement learning algorithms. These algorithms typically require extensive interaction with an environment to learn effective strategies, a process rendered impractical by the web’s near-infinite state space and its ceaseless evolution. Unlike contained environments such as games or robotics simulations, the web offers no fixed set of rules or predictable outcomes; websites change layouts, content updates dynamically, and new pages emerge constantly. Consequently, an agent attempting to learn through trial and error would need to explore an impossibly large number of possibilities, requiring an unsustainable amount of computational resources and real-world time to achieve even basic proficiency. This inherent difficulty underscores the need for novel approaches that can effectively navigate and learn within the web’s uniquely challenging landscape.
Effective web navigation by artificial intelligence hinges on an agent’s ability to generalize learned skills to previously unseen content, a feat significantly complicated by the inherent structure of the web itself. The online world presents a landscape of sparse rewards – meaningful feedback is infrequent, making it difficult for an agent to learn through trial and error. Compounding this issue is the necessity for a robust state representation; the agent must accurately interpret the complex and ever-changing visual and textual information on a webpage to understand its current situation and plan subsequent actions. Without an efficient method for distilling this information into a manageable and meaningful form, the agent struggles to discern relevant details, hindering its ability to adapt to new websites or tasks and ultimately limiting its capacity for truly autonomous web exploration.
Current approaches to web intelligence frequently constrain agents by demanding explicitly defined goals before any exploration can begin. This reliance on pre-programmed task specifications fundamentally restricts an agent’s ability to independently discover novel objectives or adapt to unforeseen circumstances within the ever-changing digital landscape. Unlike human exploration, which is driven by intrinsic curiosity and the formulation of goals during interaction, these systems require complete foresight, creating a brittle dependency that hinders true autonomy. Consequently, agents struggle with open-ended tasks and cannot leverage the web’s inherent richness for self-directed learning, limiting their potential beyond narrowly defined parameters and impeding the development of genuinely intelligent web navigation.
DynaWeb: A System Built on Simulated Experience
DynaWeb is a reinforcement learning framework designed to combine online interaction with a learned world model to facilitate imagination-driven training. The system utilizes a ‘web’ of learned dynamics – essentially a predictive model of the environment – to simulate potential outcomes of actions without requiring real-world execution. This integration allows the agent to generate imagined trajectories, effectively expanding the training data beyond direct experience. The agent then learns from both real and simulated experiences, improving sample efficiency and enabling proactive exploration of the state space. This approach differs from traditional reinforcement learning by augmenting online data collection with internally generated, predicted experiences derived from the learned world model.
The DynaWeb framework utilizes a learned world model to forecast future states given an agent’s actions, enabling planning within a simulated environment. This predictive capability allows the agent to evaluate potential action sequences and select those likely to yield positive outcomes without requiring physical execution in the real world. Consequently, the reliance on costly and potentially damaging real-world interactions is substantially decreased, as the agent can efficiently train and refine its policies through simulated experience. The world model is trained on observed transitions and provides a differentiable approximation of the environment dynamics, facilitating gradient-based planning and policy optimization.
Proactive exploration via imagined experiences within the DynaWeb framework utilizes the learned world model to generate synthetic transitions, effectively augmenting the agent’s training data. This process involves the agent internally simulating potential actions and observing the predicted outcomes, allowing it to evaluate strategies and refine its policy without requiring real-world interactions. Consequently, the agent’s experience is broadened beyond observed data, improving its capacity to generalize to unseen states and tasks. This simulated experience provides a more diverse training set, addressing limitations of solely relying on reactive, real-world data, and increasing robustness to novel situations.
Mapping the Web: State Representation and the World Model
DynaWeb employs the Accessibility Tree, a standardized representation of web page content and structure, as its primary observation source. This tree format details all visible elements – including text, images, buttons, and forms – along with their associated properties such as labels, roles, and states. By parsing the Accessibility Tree, the agent receives a structured, machine-readable description of the webpage, enabling it to accurately identify interactive components and their current status. This approach bypasses the need for unreliable visual rendering or parsing unstructured HTML, providing a robust and consistent input for the agent’s decision-making process and facilitating effective interaction with web applications.
Large Language Models (LLMs) function as the core computational component within the DynaWeb framework, fulfilling dual roles in both world modeling and action generation. Specifically, the LLM receives structured observations derived from the Accessibility Tree and utilizes this information to construct an internal representation of the current web page state – effectively, a dynamic ‘world model’. This model is then leveraged during action selection; the LLM predicts the likely outcomes of different actions and generates appropriate commands to manipulate the web environment. The LLM’s probabilistic nature allows it to handle uncertainty and explore potential action sequences, crucial for navigating complex web interactions. Crucially, the LLM is not merely a classifier or predictor; it is a generative model capable of producing coherent and contextually relevant actions based on its understanding of the web page’s state.
Supervised fine-tuning of the Large Language Model (LLM) within DynaWeb employs a dataset of web interaction examples to improve its predictive and reactive capabilities. This process involves presenting the LLM with sequences of states – representing the Accessibility Tree at different points in time – paired with corresponding actions taken by the agent. By minimizing the difference between the LLM’s predicted next state and the actual observed state, the model learns to anticipate the consequences of its actions. Furthermore, supervised training optimizes the LLM’s ability to generate appropriate actions given a current state and user instruction, enhancing the agent’s responsiveness and enabling it to navigate and interact with web pages effectively.
The System’s Potential: Optimization and Validation
To effectively navigate complex online environments, DynaWeb utilizes Group Sequence Policy Optimization, a technique that blends authentic experiences with strategically generated, imagined ones during the agent’s training. This approach allows the system to learn from a wider range of scenarios than relying solely on observed data, effectively boosting both the speed and reliability of the learning process. By incorporating imagined rollouts – simulations of potential actions and their consequences – the agent proactively explores possibilities and refines its decision-making capabilities. The integration of these synthesized experiences acts as a powerful regularizer, preventing the agent from overfitting to limited real-world data and fostering a more robust and adaptable policy for web-based tasks.
The successful navigation of complex digital environments, such as the web, benefits significantly from the incorporation of expert demonstrations into the agent’s learning process. By exposing the system to pre-defined, successful trajectories, researchers provide a crucial form of guidance, effectively shaping the agent’s initial behavior and accelerating the acquisition of effective strategies. This technique, known as regularization, prevents the agent from exploring unproductive or even detrimental actions early in training, fostering stability and improving the overall efficiency of learning. The result is a system that not only learns how to achieve objectives, but also learns to do so in a manner consistent with established best practices and desired outcomes, ultimately enhancing performance and reliability.
Rigorous testing of DynaWeb on standard web navigation benchmarks, including WebArena, reveals a substantial performance advantage. The agent achieves a noteworthy 31.0% success rate in completing complex web tasks, representing a 16.1% relative gain when contrasted with Offline-RL methods. Furthermore, consistent improvements are observed on the WebVoyager platform, directly attributable to the effective utilization of imagined rollouts – synthetic experiences that augment real-world data and accelerate the learning process. These results collectively demonstrate DynaWeb’s capacity to navigate the complexities of online environments with greater efficiency and robustness than existing approaches, highlighting its potential for automating web-based tasks and information gathering.
The pursuit of wholly autonomous web agents, as demonstrated by DynaWeb, feels less like construction and more akin to cultivating a digital ecosystem. The framework’s reliance on a learned world model to simulate experience isn’t about building intelligence, but providing the conditions for it to emerge. This echoes a sentiment shared by G. H. Hardy: “The most powerful force in the universe is imagination.” DynaWeb doesn’t seek to dictate agent behavior through exhaustive programming, but to foster an environment where agents can explore possibilities and learn from imagined consequences-a testament to the power of internal simulation over brittle, pre-defined rules. The promise isn’t perfect control, but resilient adaptation.
What Lies Ahead?
DynaWeb, like all attempts to capture a system’s essence in code, merely delays the inevitable bloom of complexity. The learned world model, however cleverly constructed from accessibility trees and large language models, remains a simplification – a map mistaken for the territory. Future iterations will inevitably grapple with the ghosts in the machine: the edge cases, the unforeseen user interactions, the sheer, irreducible messiness of the live web. Every refinement of the imagined experience will reveal new dimensions of unrealized failure.
The true challenge isn’t building a more accurate model, but accepting the inherent fragility of all such constructions. The system does not become stable; it grows unstable in predictable ways. The focus will shift from minimizing error to maximizing graceful degradation – from seeking perfect prediction to cultivating resilient recovery. Perhaps the ultimate success of this line of inquiry lies not in automating web interaction, but in providing tools for humans to navigate its increasing entropy with a modicum of grace.
One suspects the most fruitful path forward lies not in grand, unified architectures, but in embracing modularity and localized adaptation. A web agent, after all, is not a single entity, but a colony of specialized processes, each tending to its own small patch of the digital landscape. The dream of a perfect agent is a mirage; the reality will be a patchwork of imperfect ones, constantly evolving, constantly failing, and, occasionally, succeeding in surprising ways.
Original article: https://arxiv.org/pdf/2601.22149.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Limbus Company 2026 Roadmap Revealed
- EMEA Masters Winter 2026 introduces official Qualifier for Esports World Cup
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
2026-02-02 01:34