Author: Denis Avetisyan
A new reinforcement learning approach tackles the critical challenge of energy efficiency in humanoid walking, paving the way for more sustainable and practical robots.

This research introduces a constrained reinforcement learning framework, ECO, that explicitly minimizes energy consumption as a constraint during locomotion optimization.
Achieving consistently energy-efficient locomotion remains a key challenge for humanoid robots operating in real-world environments. This paper introduces ‘ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking’, a novel constrained reinforcement learning framework that decouples energy costs from reward functions, formulating them instead as explicit inequality constraints. This approach yields significant reductions in energy consumption while maintaining robust walking performance, as demonstrated through simulations and experiments on the kid-sized humanoid robot BRUCE. Could this paradigm shift in formulating energy efficiency unlock more sustainable and adaptable robotic systems?
The Inevitable Compromises of Embodied Motion
The pursuit of truly robust locomotion in humanoid robots is fundamentally hampered by the intricate interplay of dynamics and unpredictable real-world conditions. Unlike wheeled robots operating on relatively flat surfaces, bipedal robots must constantly manage a shifting center of gravity and negotiate uneven terrain, demanding exceptionally precise control of numerous actuators. These machines contend with nonlinear dynamics – small changes in input can produce disproportionate results – and must react to unexpected disturbances like slippery surfaces or sudden pushes. Moreover, accurately modeling and predicting environmental interactions – the precise force of a footfall on varied ground, for instance – remains a significant hurdle. Consequently, developing algorithms that ensure stability and adaptability across diverse and uncertain landscapes represents a core challenge in robotics, requiring sophisticated control strategies and advanced sensor integration to achieve reliable and efficient movement.
Conventional control strategies for humanoid robots frequently encounter a fundamental trade-off between maintaining stability and optimizing energy usage. Many established techniques, while capable of preventing falls in controlled settings, demand excessive power for even simple movements, drastically reducing the robot’s operational lifespan. This stems from the reliance on precise modeling and reactive control, which requires constant adjustments to counteract even minor disturbances or uncertainties in the environment. Consequently, robots employing these methods often exhibit jerky, unnatural gaits and are quickly depleted of power when navigating uneven terrain or performing extended tasks. Recent research indicates that achieving truly robust and efficient locomotion necessitates a shift towards more anticipatory control schemes and the incorporation of dynamic principles that leverage the robot’s natural momentum and balance capabilities, ultimately extending endurance and enabling more practical applications.
Humanoid robots striving for truly natural locomotion face a triad of interconnected challenges: maintaining consistent foot contact with the ground, skillfully avoiding collisions with the environment, and minimizing energy expenditure during movement. Unlike the relatively predictable surfaces encountered by wheeled robots, bipedal walking demands continuous adjustment to uneven terrain and unexpected obstacles, requiring sophisticated sensor fusion and real-time planning to ensure stable foot placement. Furthermore, replicating human walking efficiency – where elastic tendons and carefully timed muscle activations store and release energy – proves difficult with current actuator technology. Researchers are actively exploring strategies like predictive control, reinforcement learning, and bio-inspired designs to address these constraints, aiming for robots capable of navigating complex environments with the fluidity and resilience of a human gait.
Constrained Learning: Architecting for Inevitable Limits
The ECO framework addresses locomotion control as a constrained reinforcement learning problem, enabling simultaneous optimization of multiple, often competing, objectives. Traditional reinforcement learning often prioritizes reward maximization without explicitly accounting for critical performance characteristics. ECO, however, integrates stability, efficiency, and safety directly into the learning process. This is achieved by defining these attributes not merely as reward terms, but as hard or soft constraints that the learning agent must satisfy during training and deployment. By jointly optimizing for these factors, ECO generates locomotion policies that are not only high-performing but also robust and reliable in real-world scenarios, particularly for robots operating in dynamic and unpredictable environments.
ECO directly addresses the challenge of robot locomotion sustainability by integrating energy consumption as a primary constraint within the reinforcement learning process. This is achieved not by penalizing energy use within the reward function – which can lead to suboptimal trade-offs – but by strictly enforcing an energy budget during policy optimization. The framework ensures that the learned locomotion policy adheres to a defined maximum energy expenditure for each episode or time step. By framing energy consumption as a hard constraint, ECO guarantees sustainable operation, preventing the robot from learning energetically infeasible gaits, while simultaneously optimizing for other performance metrics like speed and stability. This constraint-based approach allows the robot to learn efficient locomotion strategies without sacrificing its ability to perform the desired task.
The ECO framework’s control policy is learned using Proximal Policy Optimization (PPO), a policy gradient algorithm known for its stability and sample efficiency. To integrate constraint enforcement, a Lagrangian multiplier is introduced into the PPO objective function, creating the PPO-Lagrangian algorithm. This Lagrangian term penalizes violations of the energy consumption constraint, effectively shaping the policy to prioritize energy efficiency during training. The optimization process then jointly learns the policy parameters and the Lagrangian multiplier, allowing the agent to adaptively balance performance and constraint satisfaction. The resulting PPO-Lagrangian algorithm facilitates a continuous trade-off between maximizing reward and minimizing energy expenditure, ensuring that the learned locomotion skills remain within sustainable operational limits.
The ECO framework is engineered for direct application to robots with substantial mechanical complexity, addressing limitations inherent in many reinforcement learning approaches. This is achieved by explicitly incorporating robot-specific constraints – such as joint limits, actuator saturation, and collision avoidance parameters – into the learning process. These constraints are not treated as simple penalties, but rather as hard limits enforced during policy optimization. This ensures that learned locomotion policies remain physically realizable and avoid potentially damaging or unstable behaviors, even with high-dimensional state and action spaces characteristic of complex robotic systems. The framework’s design prioritizes safe exploration and guarantees that the robot operates within its defined physical boundaries throughout the learning phase.
![The proposed ECO framework trains a policy network-driven by velocity commands and proprioception-to output desired joint positions at 100 Hz, controlled by a 1 kHz PD controller, and updated via a Lagrangian formulation [latex] ilde{20}[/latex] that balances rewards-derived from simulation feedback including energy and symmetry costs-for direct deployment to a real-world system.](https://arxiv.org/html/2602.06445v1/x2.png)
Validation: The Inevitable Confrontation with Reality
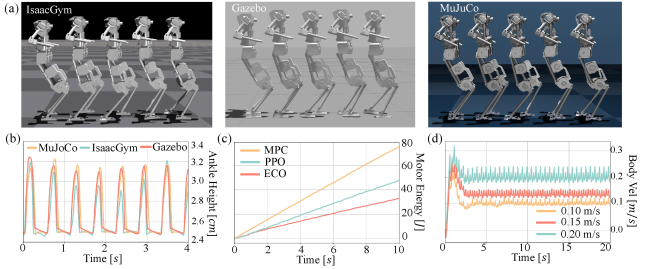
Simulation and Domain Randomization are central to the training process, enabling the development of policies resilient to unpredictable real-world conditions. This methodology involves training the humanoid robot’s control policy within a physics simulator where various environmental parameters – including friction coefficients, mass distribution, and actuator delays – are randomly varied during each training iteration. By exposing the policy to this broad range of simulated conditions, the system learns to generalize its behavior and maintain stability and efficiency even when faced with discrepancies between the simulation and the physical environment. This technique minimizes the need for extensive real-world tuning and improves the robot’s adaptability to unseen disturbances and variations in terrain.
The locomotion framework utilizes a suite of constraints to ensure safe and stable robot operation. The Foot Clearance Constraint prevents the robot’s feet from colliding with the ground during swing phases, maintaining ground clearance. The Foot Contact Velocity Constraint manages the velocity of the foot upon contact with the ground, minimizing impact forces and ensuring stable landings. Finally, the Self-Collision Constraint prevents any part of the robot’s body from colliding with itself during motion, avoiding potentially damaging or destabilizing interactions. These constraints are enforced throughout the policy learning and execution phases, contributing to robust and reliable locomotion performance.
Real-world testing of the learned policies was conducted on a physical humanoid robot to assess performance gains. Results indicate a substantial improvement in energy efficiency compared to established control methods; the learned policies achieved approximately six times lower energy consumption than Model Predictive Control (MPC) and 2.3 times lower energy consumption than Proximal Policy Optimization (PPO). These findings demonstrate the practical viability and efficiency of the developed approach for humanoid locomotion in a physical environment.
ECO’s compatibility with Model-Based Planning (MBP) facilitates improved trajectory optimization and predictive control. This integration allows the system to leverage ECO-learned policies within the MBP framework, enabling more accurate predictions of future states and facilitating the generation of dynamically feasible trajectories. By incorporating ECO’s robust control policies into the planning process, MBP can efficiently navigate complex environments and adapt to unforeseen disturbances, resulting in enhanced performance and reliability. The synergy between learned policies and model-based prediction enhances both the speed and quality of trajectory planning, providing a significant advantage in dynamic and uncertain scenarios.
![Training with constraints on energy consumption ([latex]60J[/latex]), mirror reference motion (0.05), foot clearance (3.6), foot contact velocity (-528), and self-collision (0.048) demonstrates comparable performance across ECO, P3O, and IPO, as shown by averages over 10 random seeds.](https://arxiv.org/html/2602.06445v1/x9.png)
Toward Adaptive Endurance: Embracing the Limits of Autonomy
The development of the Embodied Constraints Optimization (ECO) framework marks a considerable advancement in the pursuit of more fluid and sustainable movement for humanoid robots. Traditional robotic locomotion often prioritizes completing a task without fully accounting for the physical limitations and energetic costs inherent in complex movements; ECO directly addresses this by explicitly incorporating constraints related to energy expenditure, stability, and joint limits into the robot’s planning process. This approach allows robots to generate gaits that not only achieve the desired locomotion but also minimize energy consumption and maintain balance with greater robustness. By optimizing for these embodied constraints, the ECO framework facilitates a transition from rigid, pre-programmed movements towards a more natural and adaptable form of robotic locomotion, potentially unlocking longer operational durations and improved performance in real-world applications.
The ECO framework distinguishes itself through a deliberate focus on operational limitations, fundamentally shifting how humanoid robots navigate real-world environments. Unlike traditional approaches that prioritize performance metrics without considering energy expenditure or physical stress, ECO integrates constraints – such as battery life, motor torque limits, and balance requirements – directly into the robot’s decision-making process. This proactive constraint satisfaction isn’t merely about preventing failures; it’s about enabling sustained, reliable operation. By adhering to these boundaries, the robot avoids actions that would rapidly deplete its resources or compromise its structural integrity, effectively extending its functional lifespan and minimizing the need for frequent maintenance or recharging. Consequently, robots powered by ECO are poised to operate for significantly longer periods in complex, unstructured settings, facilitating broader deployment in applications ranging from search and rescue to long-term environmental monitoring and collaborative human-robot tasks.
The future of robotic locomotion hinges on a robot’s ability to not just walk, but to adapt its gait to unforeseen circumstances. Recent advancements achieve this by seamlessly merging constrained reinforcement learning with sophisticated planning algorithms. This integration allows robots to learn optimal locomotion strategies while simultaneously respecting physical limitations – such as joint angles or energy expenditure – and to dynamically adjust these strategies in response to environmental changes like uneven terrain or unexpected obstacles. Instead of relying on pre-programmed responses, the robot can learn to anticipate and react, essentially ‘thinking’ on its feet to maintain balance and efficiency. This capacity for adaptive locomotion represents a crucial step toward truly autonomous robots capable of operating reliably in complex, real-world settings and collaborating safely with humans.
Recent advancements in robotic locomotion have yielded a system capable of consistently maintaining an energy consumption of 60 Joules during walking, a benchmark indicative of successful constraint satisfaction. This efficiency isn’t merely a technical achievement; it represents a crucial step towards extending operational durations for robots operating independently. By minimizing energy expenditure, the system facilitates increased autonomy, allowing robots to perform tasks for longer periods without needing frequent recharging or human intervention. Furthermore, this level of energy efficiency and stable locomotion opens doors for more natural and safer human-robot collaboration, as robots can operate alongside people with reduced risk and increased predictability, ultimately broadening their potential applications in diverse environments.
![Training metrics reveal that the proposed approach consistently outperforms PPO, achieving lower energy consumption and maintaining mirror reference motion within the specified [latex]0.05[/latex] threshold, as demonstrated by the average performance across ten random seeds.](https://arxiv.org/html/2602.06445v1/x4.png)
The pursuit of optimized locomotion, as demonstrated in this work concerning energy-constrained optimization, echoes a fundamental truth about complex systems. It is not merely about achieving a goal – in this case, efficient humanoid walking – but about navigating the inherent trade-offs. Robert Tarjan observed, “Architecture isn’t structure – it’s a compromise frozen in time.” This sentiment applies directly to the ECO framework; separating energy costs as explicit constraints isn’t a perfect solution, but a pragmatic acceptance of limitations. The system doesn’t eliminate energy expenditure, it reshapes the compromises made within the walking process, acknowledging that even the most elegant algorithms are built upon a foundation of necessary concessions. The focus on constrained reinforcement learning merely formalizes the compromises that all physical systems inevitably embody.
The Horizon Beckons
This work, in isolating energy expenditure as a constraint rather than a mere optimization target, reveals a familiar truth: systems readily reveal their limits when deliberately pressed. The improvements in efficiency are not merely numerical; they are prophecies of eventual shortfall. Every gait, however optimized, is a temporary reprieve from the inevitable dissipation. Monitoring, in this context, is the art of fearing consciously.
The field now faces a more interesting challenge than simply reducing energy consumption. The true question isn’t ‘how little?’ but ‘how to fail gracefully?’. Future research will necessarily focus on anticipatory control-predicting, not preventing, energetic collapse. True resilience begins where certainty ends. The elegant Lagrangian formulation offers a compelling starting point, but the ecosystem of humanoid locomotion demands a move beyond central control; a distributed intelligence capable of learning from, and adapting to, localized energetic failures.
That’s not a bug – it’s a revelation. The pursuit of efficiency will inevitably encounter the messy realities of material fatigue, environmental variation, and the inherent unpredictability of complex systems. The next generation of work must embrace this mess, not attempt to eliminate it. It is within these failures that the most robust, and ultimately, the most sustainable, forms of locomotion will emerge.
Original article: https://arxiv.org/pdf/2602.06445.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Annulus redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- Silver Rate Forecast
- Gear Defenders redeem codes and how to use them (April 2026)
- All Mobile Games (Android and iOS) releasing in April 2026
- Top 5 Best New Mobile Games to play in April 2026
2026-02-10 03:11