Author: Denis Avetisyan
A new approach to information extraction leverages artificial intelligence to identify and categorize key concepts within complex research articles.
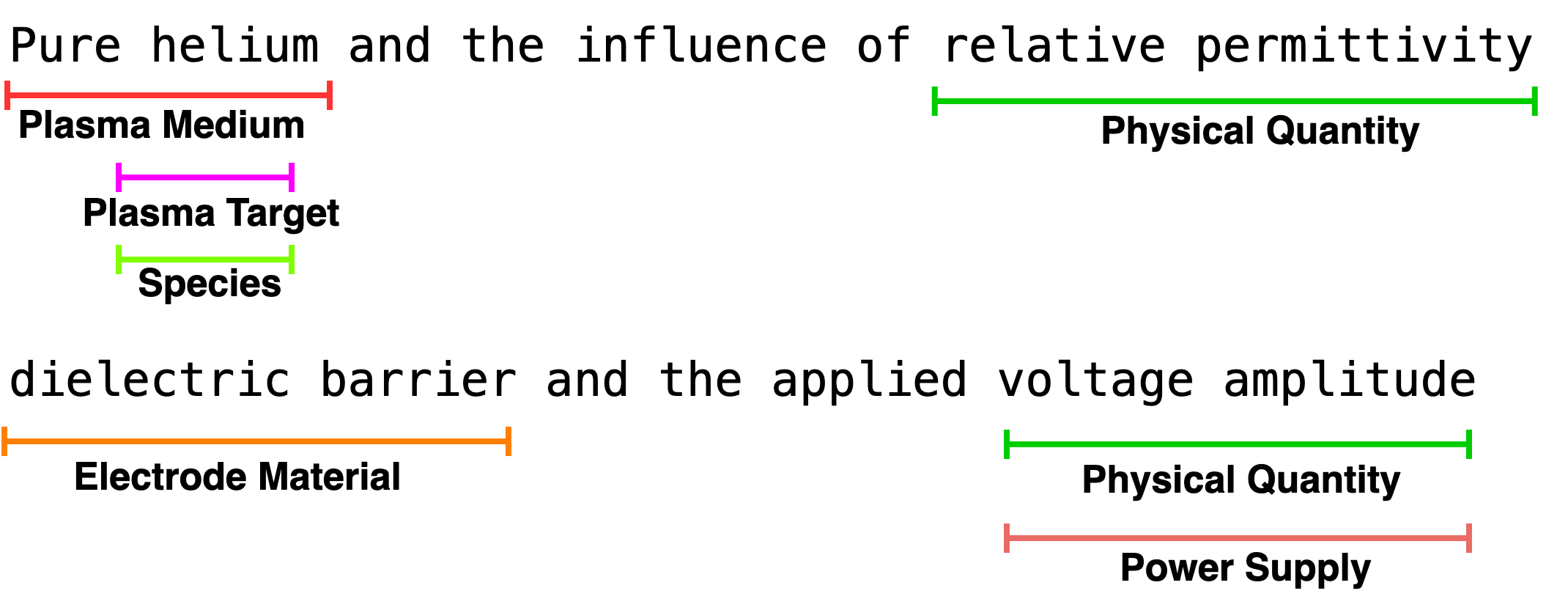
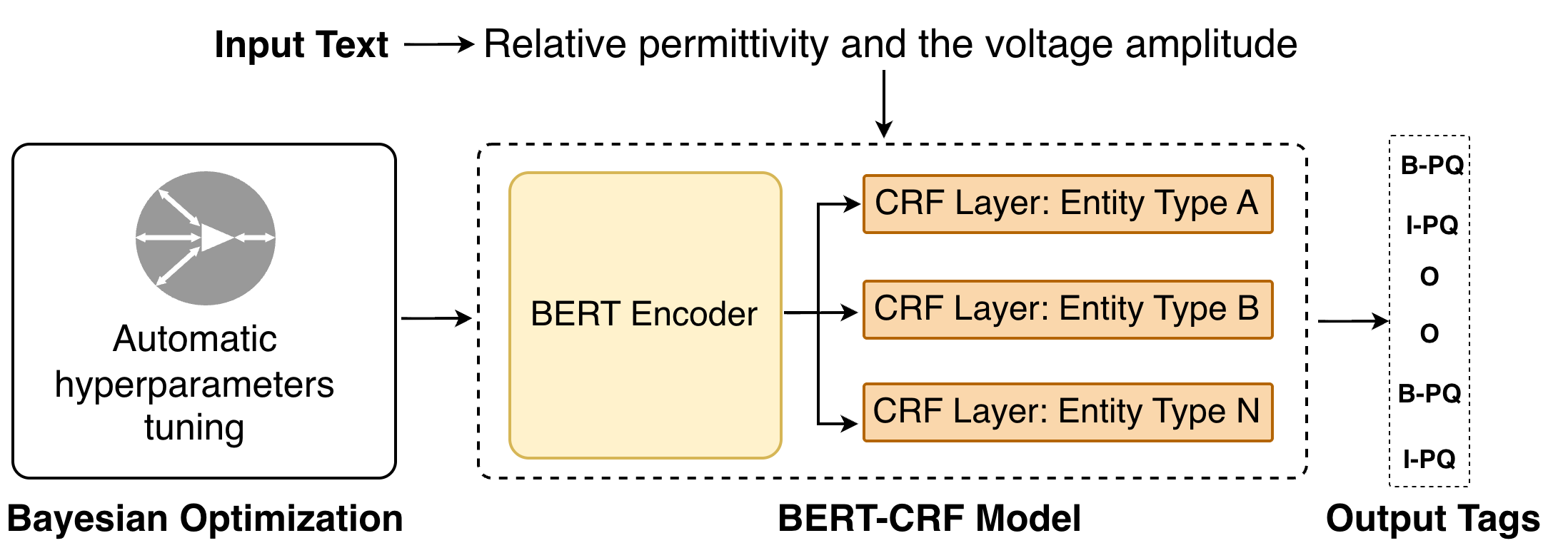
This work details a BERT-CRF model optimized via Bayesian methods for nested named entity recognition in the domain of plasma physics, utilizing a novel, manually annotated dataset.
Extracting meaningful insights from the rapidly growing body of scientific literature in fields like plasma physics remains a significant challenge due to the complexity and specialized vocabulary inherent in these texts. This work, ‘Nested Named Entity Recognition in Plasma Physics Research Articles’, addresses this issue by introducing a novel approach to automatically identify and categorize key entities within research papers. Utilizing a lightweight BERT-CRF model, optimized via Bayesian methods, we demonstrate competitive performance on a newly annotated, domain-specific dataset for nested entity recognition. Could this automated extraction of complex concepts ultimately accelerate discovery and facilitate a deeper understanding of plasma physics research?
The Fragile Order of Information: Unlocking Nested Entities
The ability to automatically extract key information from text fundamentally depends on the precision of Named Entity Recognition (NER) systems. However, current NER methods frequently encounter difficulties when processing nuanced contexts, leading to inaccuracies and incomplete data retrieval. While these systems excel at identifying obvious entities – like dates or straightforward locations – they often falter when faced with ambiguity, implicit relationships, or entities described through complex phrasing. This limitation stems from the reliance on pre-defined rules and statistical models that struggle to interpret the subtle cues and contextual dependencies crucial for accurate entity identification, particularly in domains such as legal documentation, medical records, or sophisticated financial analysis where precise understanding is paramount.
Conventional Named Entity Recognition systems frequently encounter limitations when deciphering the complete meaning of entities within complex textual structures. These systems, often relying on pre-defined rules or statistical models, struggle to fully grasp relationships between entities, or to accurately identify entities whose definitions are subtly modified by surrounding context. For instance, a phrase like “Apple’s new headquarters” presents a challenge; while “Apple” is easily identified as an organization, the system must correctly interpret “headquarters” as a specific type of location intrinsically linked to the company, and not merely as a standalone building. This difficulty stems from the fact that traditional approaches tend to treat entities in isolation, overlooking the crucial role of contextual relationships in establishing their full semantic meaning and hindering truly robust information extraction.
Successfully extracting information from complex texts often hinges on accurately identifying named entities – people, organizations, locations, and more – but this task is significantly complicated when these entities overlap or nest within one another. Traditional methods, designed to recognize isolated instances, struggle with scenarios where, for instance, an organization’s subsidiary is mentioned within the name of the parent company, or a location is contained within another geographical region. This intricacy necessitates the development of more sophisticated techniques, such as those employing machine learning models capable of understanding contextual relationships and hierarchical structures within the text. These advanced approaches move beyond simple keyword matching to discern the boundaries of each entity, even when they are embedded within others, ultimately leading to more robust and reliable information extraction from complex documents.
Deconstructing Complexity: A Nested Approach to Recognition
Standard Named Entity Recognition (NER) systems typically identify discrete, non-overlapping entities within text. However, real-world data frequently contains entities with hierarchical or overlapping relationships; for example, “the University of California, Berkeley” contains both an organization (“University of California”) and a specific location (“Berkeley”). Nested NER directly addresses this limitation by focusing on identifying entities embedded within other entities, or those sharing boundaries. This requires models to not only recognize individual entity mentions but also to understand their contextual relationships and the possibility of containment, enabling a more granular and accurate representation of information present in the text.
Recursive Conditional Random Fields (CRFs), TreeCRFs, and Layered Approaches address the challenge of identifying hierarchical entity relationships by modeling dependencies between entity spans. Recursive-CRF sequentially builds entity trees, assigning scores based on the relationships between parent and child entities. TreeCRF explicitly represents the nested structure as a tree, allowing for efficient inference of overlapping entities. Layered Approaches decompose the problem into multiple layers, where each layer identifies entities at a specific granularity, with higher layers building upon the results of lower layers. These methods differ in their structural representation and inference algorithms, but all aim to capture the contextual dependencies necessary to accurately recognize nested entities that standard, flat NER systems often miss.
Span-based methods for Nested Named Entity Recognition (Nested NER) directly model entity spans as opposed to relying on token-level classifications. These approaches typically formulate the problem as identifying the start and end indices of entities, allowing for the representation of overlapping or nested structures. Techniques utilizing Triaffine Attention further refine this process by modeling the relationships between spans through three affine transformations, enabling the system to capture complex interactions and dependencies between potential entities. This direct modeling of spans, combined with attention mechanisms, contributes to improved accuracy in identifying nested entities compared to traditional methods that process text sequentially or rely on feature engineering.
Evidence of Progress: Validating Performance Across Domains
The GENIA dataset, focused on biomedical text, and the Chilean Waiting List dataset, containing patient records, serve as key benchmarks for evaluating Nested Named Entity Recognition (Nested NER) models. Performance evaluations on these datasets yielded F1 scores of 0.77 and 0.79, respectively, indicating strong capability in identifying and classifying nested entities within complex text structures. These datasets are particularly valuable due to their differing domains – biomedical literature versus healthcare administration – allowing for assessment of model generalization across diverse textual characteristics and entity types.
The combination of Conditional Random Fields (CRF) with BERT embeddings, designated BERT-CRF, consistently yields strong performance in named entity recognition tasks across multiple datasets. This architecture leverages the contextualized word embeddings generated by BERT to enhance the ability of the CRF layer to model sequential dependencies and disambiguate entity boundaries. The CRF component addresses limitations of BERT alone in tasks requiring strict span prediction, improving precision and recall. Empirical results demonstrate that BERT-CRF achieves competitive F1 scores on the GENIA (0.77), Chilean Waiting List (0.79), and Plasma Physics (0.68) datasets, indicating its generalizability across diverse domains and annotation schemes.
The development of the Plasma Physics Dataset, specifically annotated for named entity recognition, underscores a critical requirement for domain-specific datasets in specialized scientific fields. Existing general-purpose NER datasets often lack the nuanced terminology and contextual understanding necessary for accurate performance in complex areas like plasma physics. Evaluation of our model on this dataset yielded a strict span-based F1 score of 0.68, demonstrating its capability, while also highlighting the ongoing challenges of applying NER techniques to highly technical scientific literature and the value of targeted data creation for improved model performance.
Bayesian Optimization was implemented to fine-tune the hyperparameters of BERT-CRF models, yielding improvements in both accuracy and robustness. This optimization process resulted in a model achieving a strict span-based F1 score of 0.69 on the Plasma Physics Dataset, a performance level competitive with the highest-performing baseline models. Importantly, the resulting optimized model maintains a relatively lightweight design, avoiding the computational demands associated with larger, more complex architectures, while still delivering state-of-the-art performance.
The Expanding Horizon: Impact and Future Directions
The foundation of accurately extracting information from complex text, such as scientific literature within the Plasma Physics Dataset, relies heavily on consistent annotation practices. The BIO tagging scheme – beginning, inside, outside – offers a standardized approach to labeling entities within text. This system categorizes each word as the beginning of an entity, a continuation within that entity, or existing outside of any defined entity. By applying these tags systematically, researchers create datasets amenable to machine learning models designed for Named Entity Recognition (NER). This standardized framework not only facilitates the training of more robust NER systems, but also allows for greater comparability of results across different studies and datasets, ultimately accelerating knowledge discovery in fields reliant on complex textual data.
Current approaches to Named Entity Recognition (NER) often struggle with identifying entities nested within one another – for example, a specific experimental setup described within a broader research project. To address this, researchers have successfully integrated hypergraph models with Multi-Head Dense-Augmented Conditional Random Fields (CRF). Hypergraphs allow for the representation of complex relationships between entities, capturing the hierarchical structure inherent in nested annotations. By combining this with the contextual understanding provided by dense embeddings and the parallel processing capabilities of multi-head attention, the resulting model achieves a more nuanced and accurate classification of entities. This refined ability to discern nested entities is crucial for applications requiring detailed information extraction, particularly within complex scientific domains like plasma physics, where precise relationships between components and processes are paramount.
Advancements in Nested Named Entity Recognition (Nested NER) are poised to significantly accelerate knowledge discovery and improve the precision of information extraction from complex scientific texts. The ability to accurately identify and classify nested entities – where one entity is contained within another, such as a specific experimental setup within a broader research project – unlocks a more granular and comprehensive understanding of data. This refined approach directly benefits downstream Natural Language Processing (NLP) tasks, allowing for more effective automated reasoning, question answering, and data synthesis. Recent evaluations demonstrate the impact of these improvements, with a newly developed model achieving a recall score of 0.74 – currently the highest reported among comparable methods – indicating a substantial leap in the system’s ability to comprehensively capture relevant information within complex datasets.
The pursuit of robust information extraction, as demonstrated in this work on nested named entity recognition, inherently acknowledges the transient nature of all systems. The model’s architecture, optimized through Bayesian methods, seeks not to prevent decay, but to adapt and maintain performance even as the underlying data evolves. This echoes Vinton Cerf’s observation that “Any sufficiently advanced technology is indistinguishable from magic.” The ‘magic’ isn’t permanence, but rather the system’s ability to navigate the inevitable latency and entropy inherent in processing complex, real-world data – a temporary stability cached by time, continually recalibrated against the flow of information. The creation of domain-specific datasets, while valuable, is merely a snapshot in an ever-changing landscape.
What Lies Ahead?
The pursuit of information extraction, as demonstrated by this work with nested named entity recognition, inevitably encounters the limitations inherent in formalized systems. Models, even those refined through Bayesian optimization, are snapshots – moments of order wrested from the continuous decay of language and knowledge. The creation of domain-specific datasets, while crucial, is not a solution but a temporary reprieve; the boundaries of ‘plasma physics’ are themselves fluid, constantly shifting with new discoveries and interpretations.
Future efforts might well focus not on achieving incremental gains in accuracy, but on building systems that gracefully accept ambiguity. The emphasis could shift from precise labeling to probabilistic association, acknowledging that entities are rarely cleanly defined, and relationships are often multi-layered and context-dependent. Perhaps the most valuable research will be dedicated to understanding how these systems learn to age, and where their inevitable approximations introduce unforeseen biases.
It is a curious paradox: the more meticulously one attempts to capture knowledge, the more rapidly it seems to evolve beyond reach. Sometimes, observing the process of that evolution – charting the system’s drift – proves more insightful than attempting to accelerate its convergence.
Original article: https://arxiv.org/pdf/2602.11163.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Total Football free codes and how to redeem them (March 2026)
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-02-14 23:31