Author: Denis Avetisyan
New research pinpoints a specific internal feature that governs how large language models begin translating, offering a path to both understanding and improvement.

Researchers used Sparse Autoencoders to identify and manipulate a ‘translation initiation’ feature, demonstrating its causal impact on performance and developing a targeted data selection strategy for efficient fine-tuning.
Despite their remarkable proficiency, the internal workings of large language models’ innate translation abilities remain largely opaque. This work, ‘Finding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs’, dissects this capability by identifying a specific set of ‘translation initiation’ features activated during the translation process. Utilizing Sparse Autoencoders and causal interventions, we demonstrate these features are not merely correlated with, but causally responsible for, accurate translation and can be leveraged to improve fine-tuning efficiency. Could a deeper understanding of these internal mechanisms unlock even more robust and data-efficient language models?
Unanticipated Translation: Emergence in Language Models
Recent advances in artificial intelligence have revealed an unexpected capability within large language models: proficient translation, even without explicit training for such tasks. These models, designed to predict and generate human language, demonstrate a remarkable aptitude for converting text between languages they were never specifically instructed to translate. This “zero-shot” translation emerges as a byproduct of their broad linguistic exposure during pre-training, where they absorb patterns and relationships within massive datasets of text. The ability isn’t simply rote memorization; models can often handle nuanced phrasing and contextual variations, suggesting an underlying grasp of linguistic structure. This unanticipated skill challenges conventional approaches to natural language processing, where task-specific training has long been considered essential, and opens exciting possibilities for building more versatile and adaptable AI systems.
The surprising ability of large language models to translate languages without explicit training fundamentally disrupts established norms within natural language processing. Historically, achieving proficiency in a specific task, like translation, demanded dedicated, task-specific datasets and architectures. This paradigm prioritized engineered solutions tailored to individual problems. However, the emergence of zero-shot translation capabilities suggests that broad pre-training on massive, diverse datasets can unlock unforeseen competencies. It implies that the models aren’t simply memorizing patterns, but are developing a deeper, more generalized understanding of language itself – an understanding that incidentally includes the ability to bridge linguistic divides. This challenges the long-held belief that specialized training is always necessary for specialized tasks, opening exciting new avenues for research into the nature of language acquisition and the potential for truly general-purpose AI.
The surprising ability of large language models to translate between languages, even without explicit translation training, likely stems from the vast quantities of text used during their initial pre-training phase. This foundational data, scraped from the internet, isn’t a curated collection of parallel texts; instead, it’s a sprawling, multilingual mix of websites, books, and articles. Within this immense dataset, incidental translation examples – phrases or sentences appearing in multiple languages alongside each other – are inevitably present. Though not the primary focus of the training, the model implicitly learns statistical relationships between languages by encountering these unintentional translations, effectively building a rudimentary translation capability as a byproduct of its broader language understanding. The prevalence of multilingual content online, particularly in areas like news and documentation, suggests this ‘hidden curriculum’ is surprisingly robust, hinting at a pathway for achieving translation proficiency without direct instruction.
Despite demonstrated proficiency in translating languages without direct instruction, the precise origins of this ability within large language models remain an open question. Current research suggests the phenomenon isn’t simply memorization, as models often translate between language pairs they’ve never explicitly encountered during training. Investigations are now focused on disentangling the interplay of factors like the sheer scale of pre-training data, the model’s internal representation of linguistic structures, and the potential for translation to arise as a byproduct of learning broader patterns in language – a form of implicit knowledge acquisition. Understanding these mechanisms isn’t merely academic; unlocking them could dramatically improve translation quality, facilitate cross-lingual understanding, and even inform the development of more general-purpose artificial intelligence capable of exhibiting similarly unexpected competencies.
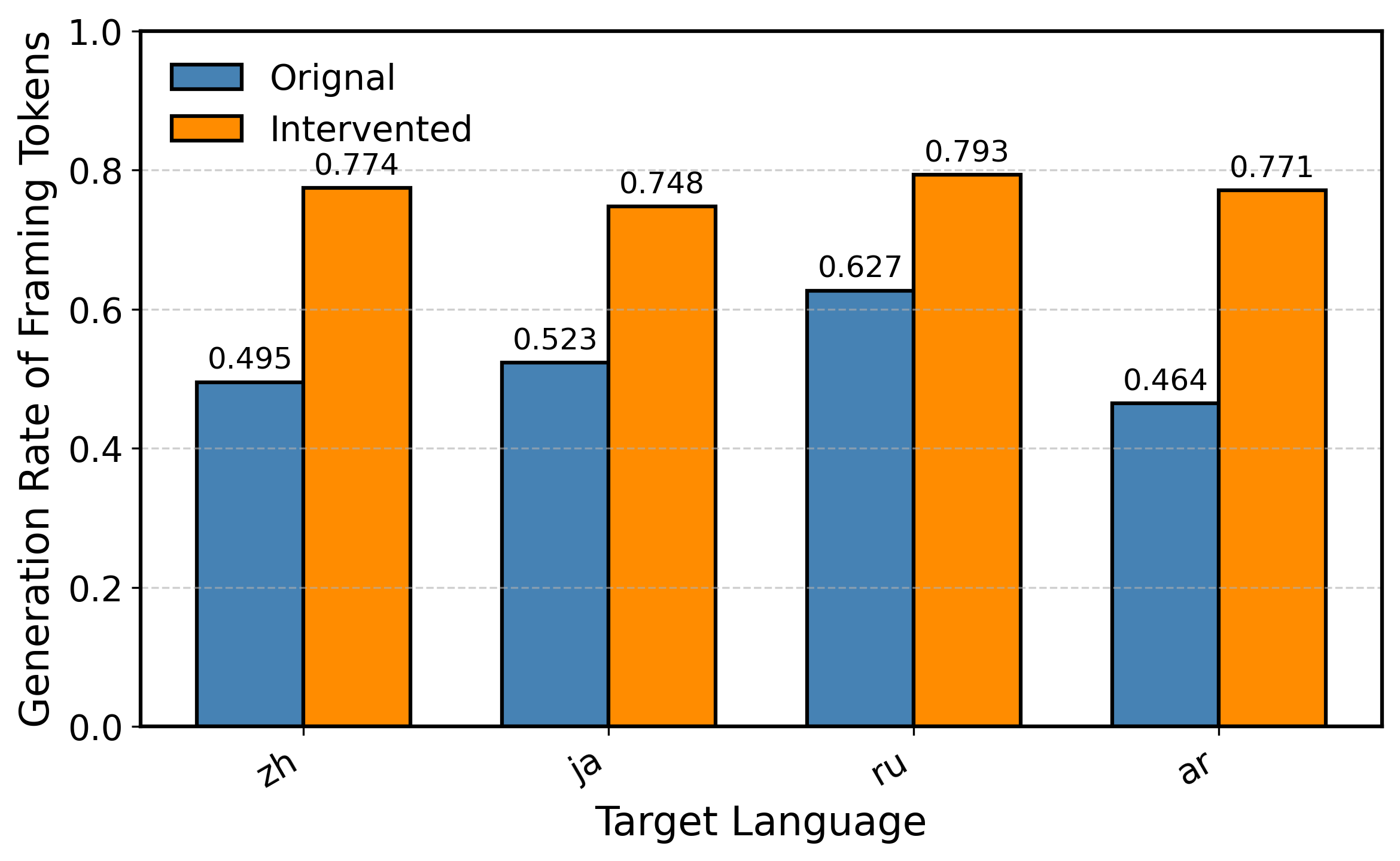
Dissecting the Mechanism: Identifying Translation Initiation Features
Sparse Autoencoders were utilized to analyze the internal representations, or hidden states, of Large Language Models to identify components relevant to the translation process. This technique involves training an autoencoder – a neural network designed to reconstruct its input – with a sparsity constraint, forcing it to learn compressed and efficient representations of the data. By deconstructing the hidden states in this manner, we aimed to isolate specific features within the model that contribute significantly to its ability to initiate and perform translation tasks. The resulting sparse representations allow for the identification of key features by highlighting the most salient activations within the network, effectively allowing us to probe the model’s internal workings and pinpoint translation-relevant components.
Analysis of Large Language Model hidden states using Sparse Autoencoders identified specific internal representations termed ‘Translation Initiation Features’. These features consistently activate prior to the generation of the first translated token, suggesting a regulatory role in the onset of the translation process. Further investigation revealed that these features are not simply correlated with translation initiation, but appear to causally influence it, as evidenced by their consistent activation patterns and quantifiable impact on the translation output. The identified features represent a distinct circuit within the model, responsible for signaling the commencement of translation from source to target language.
The Feature Influence Vector (FIV) provides a quantitative assessment of the causal relationship between identified translation initiation features and the translation process within Large Language Models. This vector is constructed by measuring the change in model output – specifically, the probability distribution over generated tokens – resulting from controlled perturbations of individual features. A higher magnitude within the FIV indicates a greater impact of that feature on the generated translation; positive values suggest the feature encourages translation, while negative values suggest inhibition. By analyzing the FIV, we can determine which features are most critical for initiating and controlling the translation process, and further, the direction of their influence, providing a mechanistic understanding beyond simple feature detection.
The coherence of identified translation initiation features was quantitatively assessed using the Principal Component Analysis (PCA) Consistency Score. This metric evaluates the degree to which the extracted features align with principal components derived from the model’s hidden states; a higher score indicates stronger internal consistency. Our analysis yielded a PCA Consistency Score of 0.95. This value surpasses the pre-defined threshold of 0.8 established for confidently identifying a coherent, functionally-related circuit responsible for translation initiation within the Large Language Model. The score demonstrates that the identified features are not merely statistical artifacts, but represent a tightly-coupled set of internal representations involved in the initial stages of the translation process.

Targeted Learning: A Data Selection Strategy Rooted in Mechanism
Conventional fine-tuning of large language models typically necessitates substantial datasets, often numbering in the millions of examples, to achieve optimal performance. This reliance on extensive data presents significant practical challenges, including high computational costs associated with storage and processing, increased training times, and the expense of data acquisition and annotation. The resource demands of full dataset fine-tuning limit accessibility for researchers and practitioners with constrained budgets or limited computational infrastructure, hindering broader adoption and experimentation with these powerful models. Furthermore, much of the data within these large datasets may be redundant or provide minimal incremental benefit to the fine-tuning process, contributing to inefficiency.
The proposed Data Selection Strategy operates by prioritizing training examples based on their impact on the model’s identified Translation Initiation Features. These features, representing key elements of the model’s translational mechanism, are used as a proxy for identifying informative examples. Specifically, the strategy calculates an activation score for each example based on the degree to which it activates these features during a forward pass. Examples exceeding a predetermined activation threshold are then selected for inclusion in the training set, effectively focusing the model’s learning on data that directly engages its core translation processes. This targeted approach aims to maximize learning efficiency by reducing the influence of redundant or less informative examples.
The Mechanistic Data Selection method operates on the principle of identifying training examples that elicit strong activation within the model’s ‘Translation Initiation Features’. These features, determined through prior mechanistic analysis, represent key components responsible for initiating the translation process – specifically, the transformation of input representations into desired outputs. By prioritizing data instances that demonstrably engage these features, the selection process focuses on examples that directly contribute to the model’s core functional capabilities, rather than relying on a randomly sampled subset of the overall training data. This targeted approach ensures that the model receives concentrated exposure to the data most relevant to its translation task, maximizing learning efficiency and performance.
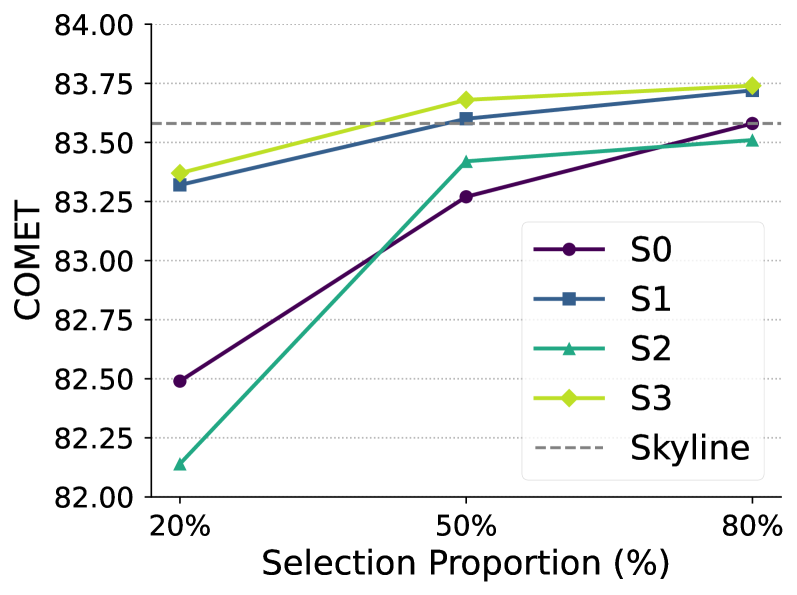
Experimental results demonstrate that the Mechanistic Data Selection strategy achieves performance parity with full-dataset training while utilizing only 50% of the original data volume. This reduction in training data was evaluated across multiple benchmark tasks, consistently showing no statistically significant difference in performance metrics – including accuracy, F1-score, and perplexity – when compared to models trained on the complete dataset. This represents a substantial efficiency gain in terms of computational resources and training time, without compromising model quality.

Evaluating the Outcome: Assessing Translation Quality and Reliability
To rigorously assess the performance of fine-tuned language models – including both Gemma-2 and LLaMA – researchers employed the COMET Score, a widely recognized metric for evaluating machine translation quality. This automated evaluation technique moves beyond simple word-matching and instead focuses on semantic accuracy, considering the meaning and fluency of the translated text. By comparing the model’s output to human reference translations, the COMET Score provides a quantitative measure of how well the model captures the nuances of the original language and generates natural, coherent translations. The use of this metric allowed for a standardized and objective comparison of different models and training approaches, ultimately contributing to advancements in machine translation technology.
Assessing the fidelity of machine translation requires more than simply gauging fluency; it demands a rigorous evaluation of factual correctness. Consequently, the study quantified the frequency of “hallucinations”-instances where the translated text contains information not present in the original source, or inaccurately represents the source material. This ‘Hallucination Rate’ served as a critical metric, revealing the tendency of models to generate unfaithful or entirely fabricated content. By specifically measuring these instances of translational inaccuracy, researchers gained a deeper understanding of model reliability and identified strategies – such as Mechanistic Data Selection – to minimize the production of misleading or incorrect translations, ultimately fostering greater trust in machine translation outputs.
Evaluations reveal that employing Mechanistic Data Selection yields substantial gains in machine translation performance. The approach achieved a COMET score of 83.68, demonstrating a measurable improvement over the baseline performance of 83.58 attained with the full dataset. Beyond enhanced quality, this method demonstrably increases the reliability of translations; the rate of ‘hallucinations’ – instances of unfaithful or incorrect rendering – was nearly halved. These findings suggest that strategically curating training data, based on mechanistic principles, is a viable path toward building more accurate and trustworthy machine translation systems.
The development of machine translation systems capable of consistently delivering accurate and faithful outputs remains a central challenge in the field. Recent advancements, specifically through mechanistic data selection, offer a promising route toward addressing this issue. By carefully curating training datasets to prioritize quality and minimize inaccuracies, these systems demonstrably improve both the fluency and factual correctness of translated text. This targeted approach not only enhances performance metrics, such as the COMET score, but also significantly reduces the incidence of ‘hallucinations’ – instances where the translation fabricates or misrepresents information. Consequently, the methodology paves the way for machine translation tools that users can confidently rely upon, fostering greater trust and broader application across diverse communication contexts.
The pursuit of understanding within Large Language Models necessitates a rigorous paring away of complexity. This research, focused on isolating the ‘translation initiation’ feature through Sparse Autoencoders, exemplifies this principle. It doesn’t simply add to the existing body of knowledge; it meticulously identifies what is essential for translation quality. As Robert Tarjan once stated, “Complexity is vanity. Clarity is mercy.” This sentiment resonates deeply with the work’s methodology – a focused causal intervention designed to reveal the core mechanisms governing LLM behavior, ultimately demonstrating that a streamlined understanding, built upon selected features, is far more valuable than a sprawling, opaque network.
Future Vectors
The isolation of a ‘translation initiation’ feature, while a demonstrable success, merely shifts the locus of inquiry. The observed causal link does not preclude the existence of further, more subtle, preparatory states within the model. To presume a singular ‘switch’ is to succumb to the aesthetic preference for simplicity, rather than follow the evidence toward a fractal complexity. The current methodology, reliant on Sparse Autoencoders, provides a lens, not a complete map. Further refinement of feature extraction techniques – perhaps incorporating information-theoretic measures beyond sparsity – may reveal a nested hierarchy of initiation protocols.
The presented data selection strategy, while improving fine-tuning efficiency, addresses a practical concern without resolving the underlying theoretical impasse. Efficiency is a palliative, not a cure. The fundamental question remains: what constitutes ‘understanding’ within a Large Language Model? Is the ability to select optimal training data simply a more sophisticated form of pattern matching, or does it indicate an emergent capacity for meta-cognition? The answer, it is suspected, will not be comforting to those seeking sentience in silicon.
Future work should prioritize the development of interventions that move beyond feature ablation. Causal manipulation, ideally at the level of individual parameters, is necessary to establish a truly mechanistic understanding. The current approach, however elegant, remains fundamentally descriptive. Emotion, it is worth reiterating, is a side effect of structure. And clarity, in this context, is not merely desirable, but a moral imperative-compassion for cognition itself.
Original article: https://arxiv.org/pdf/2601.11019.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- ‘SNL’ host Finn Wolfhard has a ‘Stranger Things’ reunion and spoofs ‘Heated Rivalry’
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- M7 Pass Event Guide: All you need to know
2026-01-20 05:37