Author: Denis Avetisyan
A new approach uses the power of large language models to systematically extract definitions from the vast body of academic literature.
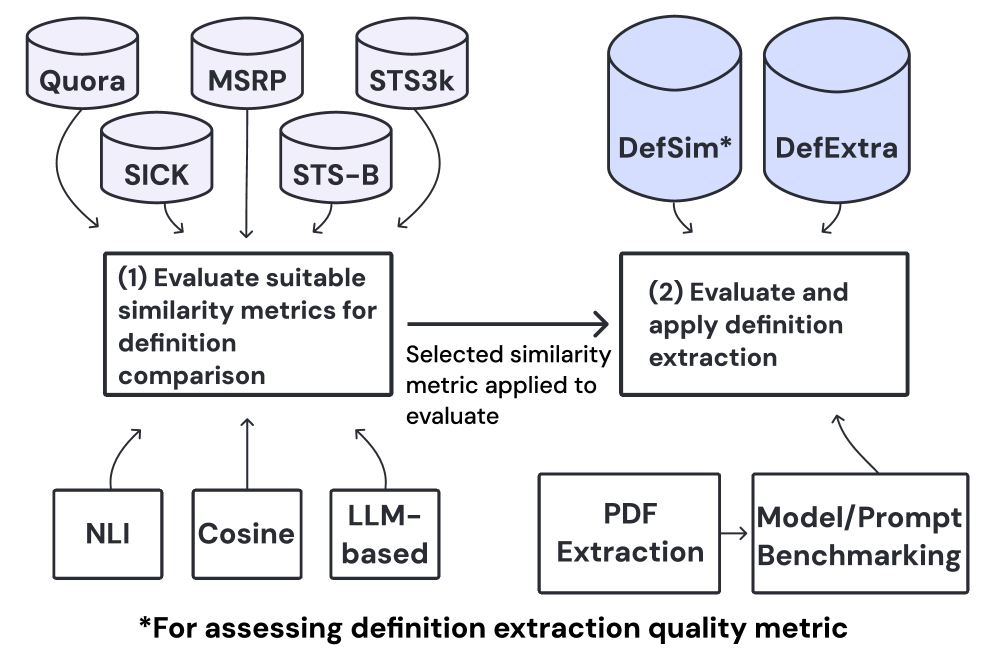
This paper introduces SciDef, a definition extraction pipeline and associated datasets that demonstrate improved performance through optimized prompting and a multi-step process.
The exponential growth of scientific literature presents a paradox: while knowledge accumulates rapidly, efficiently locating precise definitions within this vast corpus remains a significant challenge. To address this, we introduce SciDef: Automating Definition Extraction from Academic Literature with Large Language Models, a pipeline leveraging large language models alongside the novel DefExtra and DefSim datasets for benchmarking. Our evaluations across 16 models demonstrate that optimized, multi-step prompting strategies substantially improve extraction performance, with an NLI-based metric proving most reliable; achieving 86.4% definition extraction accuracy. However, given the tendency toward over-generation, future work must prioritize not simply finding definitions, but discerning those that are truly relevant to a given query.
The Illusion of Knowledge: Defining Definitions in a Sea of Data
The sheer volume of scientific publications presents a paradox for automated knowledge discovery: while a wealth of information exists, accessing it meaningfully remains a substantial challenge. Although researchers generate countless articles, reports, and datasets, converting this raw text into structured, usable knowledge hinges on the accurate identification of key definitions. Current automated systems often falter because they struggle with the complexity of scientific terminology, contextual nuances, and the dynamic nature of definitions that evolve alongside ongoing research. This bottleneck limits the potential of artificial intelligence to accelerate scientific progress by hindering its ability to build comprehensive and reliable knowledge graphs – interconnected networks of concepts and their relationships – from the ever-expanding scientific record. Ultimately, improved definition extraction techniques are crucial for unlocking the full potential of this vast repository of knowledge and enabling machines to truly ‘understand’ scientific literature.
Existing techniques for defining scientific concepts often falter due to the inherent complexity of scholarly writing and the dynamic character of scientific understanding. Conventional methods, reliant on pattern matching or fixed lexicons, struggle with the subtle variations in terminology, contextual dependencies, and the prevalence of implicit definitions within research papers. This leads to inaccuracies in extracted definitions, where a term might be defined too broadly, too narrowly, or even incorrectly, hindering the creation of reliable knowledge graphs. Moreover, as scientific fields advance, definitions themselves evolve; static approaches fail to capture these shifts, resulting in incomplete or outdated knowledge representations that limit the effectiveness of automated knowledge discovery systems and perpetuate errors within the broader scientific record.
Large Language Models: A Band-Aid on a Broken System?
Large Language Models (LLMs) leverage deep learning architectures and massive datasets of text and code to achieve state-of-the-art performance in natural language understanding and generation. This capability extends to tasks requiring semantic analysis, such as identifying the core meaning of terms and differentiating definitions from surrounding context. LLMs utilize techniques like attention mechanisms and transformer networks to process language with a nuanced understanding of syntax, semantics, and relationships between words. Consequently, LLMs can be applied to automate the traditionally manual process of definition extraction from diverse textual sources, offering scalability and potential improvements in consistency and speed compared to human-based approaches. Their ability to generate coherent and contextually relevant text also enables them to present extracted definitions in a standardized and easily understandable format.
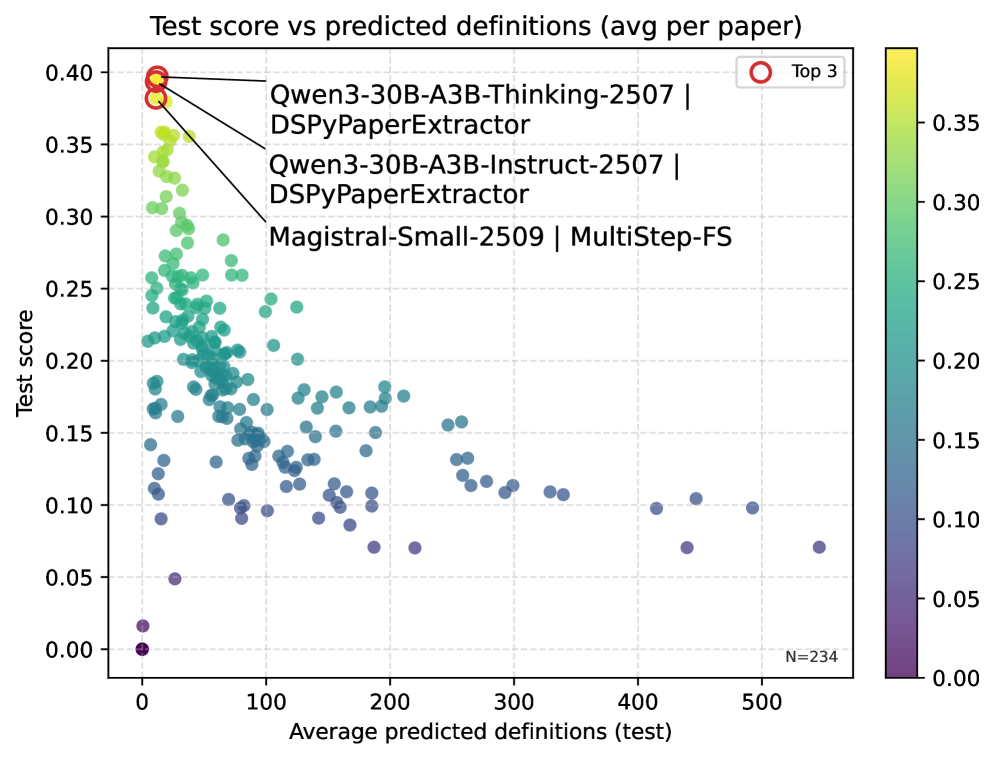
Successful definition extraction using Large Language Models (LLMs) is heavily dependent on prompt engineering. LLMs require specific instructions to identify and articulate definitions accurately; ambiguous or poorly constructed prompts yield inconsistent or irrelevant outputs. Strategies include clearly defining the expected output format – such as a concise sentence or a bulleted list – and providing contextual examples to guide the model’s understanding of the target term. Furthermore, techniques like few-shot learning, where the prompt includes several example term-definition pairs, significantly improve performance by demonstrating the desired relationship. Iterative prompt refinement, based on evaluation of model outputs, is crucial for optimizing accuracy and consistency in definition extraction tasks.
The selection of a Large Language Model (LLM) for definition extraction involves considering both open-weight and proprietary options, each presenting distinct trade-offs. Open-weight LLMs, such as those available through Hugging Face, offer greater customization and transparency, allowing for model fine-tuning and inspection, but generally require more computational resources and expertise for optimal performance. Conversely, proprietary LLMs, like those from OpenAI or Google, typically provide ease of access through APIs and often demonstrate strong out-of-the-box performance, but come with associated costs per API call and limited control over the underlying model architecture. Performance benchmarks vary between models within each category, with proprietary models frequently exhibiting higher accuracy and speed, though recent advancements in open-weight models are narrowing this gap. Ultimately, the optimal choice depends on budgetary constraints, the need for customization, and the required level of performance.
Evaluating the Illusion: Metrics for Measuring Meaning
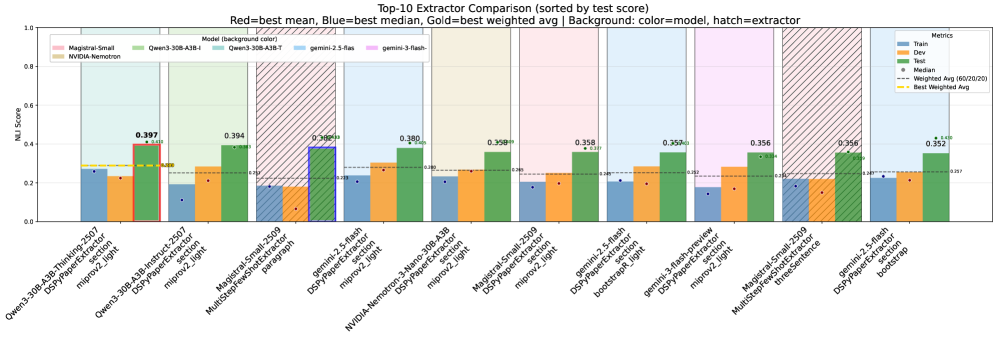
Evaluating the performance of definition extraction systems necessitates the use of robust metrics that move beyond simple lexical overlap and assess semantic relatedness. Traditional metrics like precision and recall are often insufficient because definitions can be expressed in multiple valid ways, differing in wording yet conveying the same meaning. Semantic similarity metrics, leveraging techniques like word embeddings and natural language inference (NLI), quantify the degree to which an extracted definition captures the essential meaning of a ground truth definition. These metrics calculate a similarity score based on the contextual representation of words and phrases, enabling a more nuanced and accurate assessment of definition quality, even when lexical matching is poor. The choice of metric significantly impacts evaluation results and system comparison, requiring careful consideration of the specific characteristics of the definitions and the desired evaluation criteria.
Embedding-based metrics, such as cosine similarity calculated on sentence embeddings generated by models like Sentence-BERT, quantify semantic relatedness by representing definitions as vectors in a high-dimensional space; however, these metrics can struggle with nuanced logical relationships. Natural Language Inference (NLI)-based metrics, conversely, frame the task as determining whether the extracted definition entails, contradicts, or is neutral with respect to the ground truth definition, providing a more structured assessment of logical correctness. Combining these approaches offers complementary strengths: embedding metrics efficiently capture overall semantic similarity, while NLI metrics provide a targeted evaluation of definitional validity and logical consistency, leading to a more comprehensive evaluation of definition extraction quality.
Standardized benchmarking datasets are critical for the objective evaluation of definition extraction systems. DefSim comprises 6060 definition pairs with labeled semantic similarity scores, enabling quantitative assessment of extraction quality. The larger DefExtra dataset contains 268,268 definitions sourced from 7,575 research papers, providing extensive data for both training and evaluation purposes. Recent analyses utilizing DefSim and DefExtra have demonstrated performance gains in Natural Language Inference (NLI)-based similarity scoring through techniques like multi-step prompting and optimization via the DSPy framework, highlighting the utility of these datasets for driving advancements in definition extraction methodologies.
![Performance metrics consistently exceed a [latex]0.95[/latex] threshold across all evaluated datasets.](https://arxiv.org/html/2602.05413v1/x4.png)
Beyond the Algorithm: Implications and Future Faults
The application of automated definition extraction extends beyond simple factual recall, proving particularly insightful when applied to complex, subjective domains like media bias. This technique doesn’t merely identify what constitutes ‘bias’, but dissects how the term is defined – or contested – across different sources. Researchers find that inconsistencies in terminology are readily revealed; what one outlet labels as ‘spin’, another might characterize as ‘framing’ or ‘perspective’. By computationally mapping these definitional variations, a more nuanced understanding of the landscape emerges, allowing for the detection of subtle rhetorical strategies and the identification of potential areas of miscommunication or manipulation. This granular analysis transcends simple keyword spotting, offering a pathway towards a more objective assessment of information and the biases inherent within it.
Recent advancements leverage frameworks like DSPy to refine the process of prompting large language models for definition extraction, moving beyond simple, static prompts. DSPy facilitates the construction of sophisticated prompting pipelines – chains of prompts designed to iteratively refine and validate extracted definitions. This optimization isn’t merely about achieving higher accuracy; it dramatically improves the efficiency of the extraction process by reducing the need for manual review and correction. By programmatically testing and adjusting prompt sequences, DSPy enables researchers to identify and eliminate biases or ambiguities in the LLM’s responses, ultimately yielding more consistent and reliable definitions, particularly crucial when dealing with complex or subjective topics.
The automated extraction of definitions from text unlocks the potential for constructing expansive and continuously updated knowledge graphs. These graphs, representing concepts and their relationships, move beyond static dictionaries by dynamically incorporating new information as it emerges in scientific literature and other data sources. This capability significantly accelerates scientific discovery, as researchers can efficiently navigate complex fields, identify knowledge gaps, and formulate novel hypotheses. Furthermore, such dynamic knowledge graphs underpin the development of more intelligent information systems capable of sophisticated reasoning, nuanced understanding, and ultimately, a more effective translation of data into actionable insights across diverse domains.
The pursuit of automated definition extraction, as detailed in this SciDef pipeline, feels…predictably optimistic. It’s a clever arrangement of large language models and similarity metrics, certainly. But one anticipates the inevitable edge cases, the subtly nuanced definitions that will confound even the most meticulously crafted prompts. Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” The magic, however, invariably fades when confronted with production data. This pipeline, with its DefExtra and DefSim datasets, represents a valiant attempt to codify knowledge, but it’s merely delaying the inevitable accrual of tech debt. The FAIR principles are admirable, but a definition is only as good as its context-and context, as always, is messy.
What’s Next?
The pursuit of automated definition extraction will inevitably reveal that the bug tracker is, once again, filling with edge cases. SciDef, and systems like it, address a neatly defined problem-but production will find the ambiguity. The semantic precision demanded of scientific definitions isn’t merely a matter of similarity metrics; it’s a negotiation with context, authorial intent, and the evolving landscape of knowledge itself. Benchmarking with DefExtra and DefSim offers a convenient illusion of progress; a contained environment rarely survives contact with real-world literature.
The current focus on large language models, while producing incremental gains, skirts the deeper issue. It assumes definitions exist as discrete units, readily extractable. A more robust approach might involve modeling not just what is defined, but how definitions are constructed – the rhetorical strategies, the implicit assumptions, the historical lineage of a concept. It is not enough to identify a definition; the system must understand why that definition, at that moment, is considered valid.
The FAIR principles are laudable, but data provenance becomes exponentially more complex when dealing with interpretations rather than raw data. The pipeline doesn’t simply extract; it constructs a definition, and that construction is inherently subjective. The system doesn’t deploy – it lets go, and hopes the definitions stick.
Original article: https://arxiv.org/pdf/2602.05413.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Kagurabachi Chapter 118 Release Date, Time & Where to Read Manga
- Last Furry: Survival redeem codes and how to use them (April 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- All Mobile Games (Android and iOS) releasing in April 2026
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Limbus Company 2026 Roadmap Revealed
2026-02-08 02:26