Author: Denis Avetisyan
Researchers have developed a new artificial intelligence system that helps identify the underlying factors driving complex phenomena, moving beyond simple correlations.
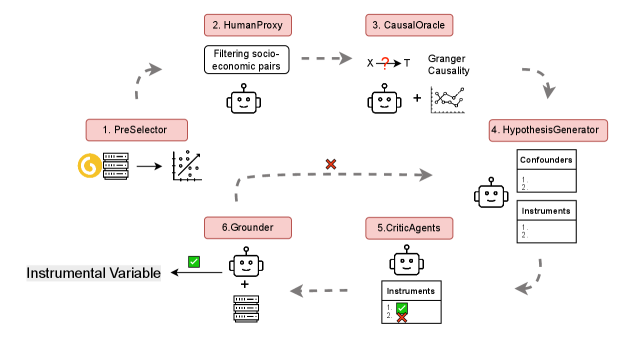
This paper introduces IV Co-Scientist, a multi-agent large language model framework designed to discover and validate instrumental variables for causal inference in socio-economic data.
Establishing causal relationships is often hampered by confounding variables, demanding robust methods for isolating true effects. This challenge motivates the development of ‘IV Co-Scientist: Multi-Agent LLM Framework for Causal Instrumental Variable Discovery’, a novel system leveraging large language models to aid in the identification and validation of instrumental variables. Our work demonstrates that a multi-agent LLM framework can effectively propose plausible instruments and assess their validity using real-world socio-economic data, even in the absence of definitive ground truth. Could this approach unlock more reliable causal inference across complex observational datasets and accelerate scientific discovery?
The Illusion of Control: Why Correlation Isn’t Causation
Determining true causal relationships-understanding what directly influences what-is paramount across diverse fields, from medicine and economics to climate science and sociology. However, conventional statistical methods frequently falter when faced with unobserved confounders – hidden variables that influence both the presumed cause and effect, creating misleading associations. These lurking factors can easily masquerade as causal links, leading to inaccurate conclusions and ineffective policies. For instance, a correlation between ice cream sales and crime rates might appear causal, but is actually driven by a third, unobserved variable: warmer weather. Consequently, researchers are increasingly focused on developing methods that can account for-or even identify-these hidden confounders, striving for a more reliable understanding of the underlying mechanisms driving observed phenomena and enabling more impactful interventions.
The prevalence of spurious correlations presents a formidable challenge to accurate inference, particularly within economics and public health. These misleading associations-where two variables appear related but are, in fact, both influenced by a third, unobserved factor-can lead researchers to draw incorrect conclusions about cause and effect. Consequently, interventions based on these flawed understandings may prove ineffective, or even detrimental. For example, a perceived link between ice cream sales and crime rates might erroneously suggest that one causes the other, when both are actually driven by warmer weather. Identifying and accounting for such hidden variables is therefore paramount to ensuring that policies and treatments are grounded in genuine causal relationships, rather than superficial patterns in the data.
Traditional causal analyses frequently depend on substantial prior knowledge and strong assumptions about the underlying data-generating process, a practice which, while sometimes necessary, inherently restricts their broader applicability. The need for detailed domain expertise to formulate these assumptions creates a bottleneck, limiting the scalability of these methods to new contexts or datasets where such knowledge is absent or incomplete. This reliance also jeopardizes generalizability; a causal relationship confidently identified under specific assumptions may not hold true when those assumptions are subtly violated in a different population or environment. Consequently, researchers are increasingly seeking methods that minimize these dependencies, striving for approaches capable of uncovering causal links with fewer preconditions and greater robustness across diverse scenarios.
The increasing availability of large datasets presents both an opportunity and a challenge for discerning true causal relationships. Traditional statistical methods, often reliant on controlled experiments or simplifying assumptions, frequently falter when confronted with the complexities of observational data and hidden variables. Consequently, researchers are actively developing new methodologies – encompassing techniques like instrumental variables, causal discovery algorithms, and machine learning approaches – designed to infer causality from passive observation. These innovative strategies aim to move beyond mere correlation, leveraging data patterns and algorithmic inference to identify underlying mechanisms and robustly establish cause-and-effect links, even within high-dimensional and intricate systems. This pursuit promises more reliable predictions and effective interventions across diverse fields, from personalized medicine to economic policy.
IV Co-Scientist: A Pragmatic Approach to Causal Inference
IV Co-Scientist is a computational framework designed to automate the identification and validation of instrumental variables (IVs) for causal inference. The system leverages multiple Large Language Model (LLM) agents working in concert to address the challenges inherent in IV analysis. It moves beyond traditional statistical methods by utilizing LLMs to analyze complex datasets and literature, proposing potential IVs and evaluating them against established criteria. This multi-agent approach aims to improve the efficiency and reliability of identifying valid instruments, which are crucial for estimating causal effects in observational studies where randomized controlled trials are not feasible. The framework outputs candidate IVs with associated validation scores, based on adherence to the relevance, exclusion, and independence assumptions necessary for valid causal estimation.
The Hypothesis Generator agent within IV Co-Scientist functions by systematically proposing candidate instrumental variables (IVs) and potential confounding variables. This agent expands the search space for valid IVs beyond what is typically feasible through manual review, leveraging the LLM’s capacity to identify a broader range of possibilities. The scope of exploration is increased through the agent’s ability to consider a large number of variables and their potential relationships, based on the available data and pre-defined causal assumptions. This automated generation of hypotheses then feeds directly into the subsequent validation stage performed by the Critic Agent, enabling a more comprehensive assessment of causal relationships.
The Critic Agent within IV Co-Scientist performs a validity assessment of proposed instrumental variables (IVs) by evaluating them against three core principles. Relevance is confirmed by assessing the relationship between the IV and the exposure variable. The exclusion restriction is verified by determining whether the IV affects the outcome only through its effect on the exposure, and not through any other pathway. Finally, independence is established by confirming that the IV is unrelated to unobserved confounders affecting the exposure and outcome. This rigorous, principle-based evaluation process aims to filter out invalid IV candidates and ensure the reliability of causal estimates.
Traditional identification of instrumental variables (IVs) for causal inference is a labor-intensive process requiring substantial domain expertise and often involving subjective assessments of variable suitability. IV Co-Scientist automates key steps in this process, including candidate IV generation and rigorous evaluation against established criteria – relevance, exclusion restriction, and independence. This automation minimizes the need for manual literature review, hypothesis formulation, and statistical testing. By systematically applying these validation checks, the system reduces the potential for bias introduced by researcher interpretation and allows for exploration of a wider range of potential IVs than is typically feasible with manual methods, thereby increasing the robustness and reproducibility of causal estimates.
The Anatomy of a Valid Instrument: Three Necessary Conditions
A valid instrumental variable (IV) requires the simultaneous satisfaction of three core conditions: relevance, the exclusion restriction, and the independence condition. Relevance necessitates a statistically significant correlation between the IV and the endogenous treatment variable; without this, the IV cannot serve as a proxy for the treatment’s effect. The exclusion restriction dictates that the IV influences the outcome solely through its effect on the treatment variable, precluding any direct effect on the outcome itself. Finally, the independence condition requires that the IV is uncorrelated with the error term in the structural equation – specifically, it must be independent of any unobserved confounders that also influence the outcome. Failure to meet any of these three conditions invalidates the IV and introduces bias into the estimation of the causal effect.
The relevance condition for a valid instrumental variable (IV) necessitates a statistically significant correlation between the IV and the endogenous treatment variable. This correlation is fundamental as it establishes a pathway through which the IV can exert influence on the outcome variable via the treatment. Without a demonstrable relationship – typically confirmed through a first-stage regression where the treatment variable is regressed on the IV – the IV lacks the necessary power to explain variation in the treatment and therefore cannot be used to identify causal effects. A weak or non-existent correlation indicates the IV is a poor instrument, potentially leading to biased estimates and invalid inferences.
The Exclusion Restriction is a critical assumption in instrumental variable (IV) estimation, demanding that the instrument’s sole influence on the outcome variable operates indirectly, through its effect on the treatment variable. This means any impact of the instrument on the outcome must be entirely mediated by changes in the treatment; a direct pathway from the instrument to the outcome, independent of the treatment, violates this restriction. Establishing the validity of the Exclusion Restriction often relies on a strong theoretical justification, demonstrating that the instrument affects no other factors that could independently influence the outcome. Failure to satisfy this condition introduces bias, as the IV estimates will reflect both the causal effect of the treatment and the direct effect of the instrument, leading to inconsistent estimates.
The Independence Condition, crucial for valid instrumental variable (IV) estimation, asserts that the IV is uncorrelated with the error term in the structural equation. This implies the IV is independent of all confounders – both observed and, critically, unobserved – that influence the relationship between the treatment and the outcome. Failure to satisfy this condition introduces bias, as the IV would then be capturing effects not solely channeled through the treatment variable. Establishing exogeneity – the property of being independent of unobserved factors affecting the outcome – is therefore paramount; techniques like overidentification tests are employed to assess the plausibility of this assumption, though definitive proof remains challenging.
Putting it to the Test: Validation on the Gapminder Dataset
The Gapminder dataset was selected as the evaluation benchmark for IV Co-Scientist due to its comprehensive collection of socio-economic and health indicators across a wide range of countries and time periods. This dataset includes variables such as GDP per capita, life expectancy, education levels, and various health metrics, providing a robust platform for testing the framework’s ability to identify valid instrumental variables in complex, real-world scenarios. The breadth of data points and the interconnectedness of the variables allow for broad-scale testing of IV Co-Scientist’s performance across diverse causal relationships and potential confounding factors.
IV Co-Scientist successfully identified valid instrumental variables (IVs) for multiple causal inquiries within the Gapminder dataset. This functionality was demonstrated across diverse socio-economic relationships, indicating the framework’s capacity to discern appropriate IVs even when accounting for complex interdependencies and potential confounders. The identification process wasn’t limited to simple linear relationships; the framework was able to navigate scenarios involving non-linear interactions and multiple mediating variables to pinpoint valid instruments, suggesting a robust methodology for causal inference in complex datasets.
Two-Stage Least Squares (2SLS) regression was employed to assess the validity of instrumental variables (IVs) identified by IV Co-Scientist within the Gapminder dataset. This method addresses potential endogeneity issues by first regressing the endogenous explanatory variable on the instrument(s) and control variables in the first stage. The predicted values from this first stage are then used in a second-stage regression to estimate the causal effect on the outcome variable. Significant coefficients in both stages, coupled with appropriate diagnostic testing, confirm that the identified IVs are predictive of the endogenous variable and that the estimated causal effects are not attributable to omitted variable bias or reverse causality. The results of the 2SLS regressions provide empirical support for the validity of the IVs generated by the framework.
Evaluation of the IV Co-Scientist framework on the Gapminder dataset demonstrated comparable internal validity, as evidenced by a consistency score of less than 1 – a performance level comparable to that of randomly generated instruments. This indicates a low probability of spurious correlations influencing the identified causal relationships. Furthermore, instrument strength and relevance were confirmed via F-statistic analysis, with values consistently exceeding 10; this threshold supports the reliability of the instrumental variables in explaining variation in the endogenous variables and minimizing weak instrument bias in subsequent causal inference.
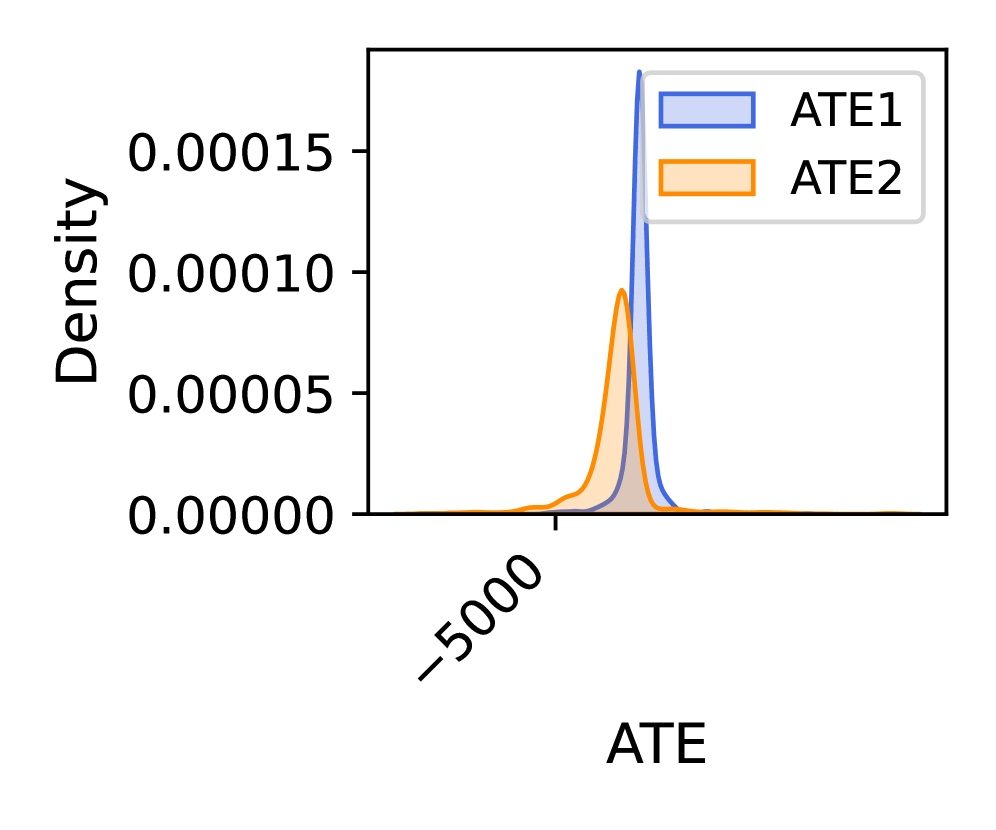
Beyond Average Effects: Towards Nuanced Causal Understanding
IV Co-Scientist represents a notable advancement in causal inference by moving beyond estimations of average treatment effects to pinpoint ‘Local Average Treatment Effects’ (LATE). Traditional methods often assume a treatment’s impact is uniform across an entire population, a simplification that can obscure crucial variations. This framework, however, enables researchers to identify how a treatment specifically affects a defined subpopulation – those whose treatment status is influenced by the instrumental variable. This capability is particularly valuable when dealing with heterogeneous effects, allowing for a more nuanced understanding of causal relationships and facilitating targeted interventions. For example, it can reveal whether a policy is effective for one demographic group but not another, offering actionable insights previously unavailable through conventional analyses.
The advent of this automated framework promises to substantially accelerate causal discovery across a wide spectrum of research fields. Traditionally, establishing causal relationships has been a painstaking manual process – formulating hypotheses, identifying potential confounders, and applying complex statistical techniques. This new system significantly reduces this burden by automating key steps in the process, from variable selection to causal model estimation. Researchers in fields like epidemiology, economics, and social science, who frequently grapple with observational data and the challenge of separating correlation from causation, stand to benefit immensely. The potential for streamlined analysis not only saves valuable time and resources but also allows investigators to explore more complex causal relationships and conduct more rigorous analyses, ultimately fostering more informed decision-making and robust scientific conclusions.
Continued development centers on refining the large language model’s capacity for complex reasoning, moving beyond pattern recognition to genuine causal understanding. This includes integrating specialized, domain-specific knowledge – effectively teaching the AI the nuances of fields like economics or medicine – to improve the accuracy and relevance of its inferences. Simultaneously, researchers are working to bolster the framework’s robustness, ensuring reliable performance even with noisy or incomplete data, and addressing potential biases inherent in the training datasets. These enhancements promise a more adaptable and trustworthy system capable of tackling increasingly sophisticated causal questions across a wide spectrum of scientific inquiry.
The convergence of artificial intelligence and causal inference represents a pivotal advancement with far-reaching implications for data-driven strategies. Traditionally, establishing definitive cause-and-effect relationships has been a complex undertaking, often reliant on meticulously designed experiments or strong assumptions. This framework aims to overcome these limitations by leveraging the power of large language models to automate and refine the process of causal discovery. Consequently, policymakers and decision-makers gain access to more reliable insights, enabling the design of interventions and policies grounded in a deeper understanding of underlying mechanisms, rather than mere correlations. This shift promises more effective solutions across a spectrum of fields, from public health and economics to environmental science and urban planning, ultimately fostering evidence-based strategies for a more predictable and impactful future.
The pursuit of automated causal discovery, as demonstrated by ‘IV Co-Scientist’, feels less like innovation and more like accelerating the inevitable. This framework, proposing instrumental variables with Large Language Models, merely shifts the burden of error. It elegantly automates a process previously reliant on human intuition, yet it doesn’t eliminate the possibility of spurious correlations being accepted as causal links. As Vinton Cerf once stated, “Any sufficiently advanced technology is indistinguishable from magic.” The magic, here, is a sophisticated algorithm-but like all illusions, it’s built on assumptions and prone to failure when confronted with the messy reality of production data. The system might propose plausible instruments, but verifying their validity remains a distinctly unmagical, and likely frustrating, task.
What’s Next?
The automation of instrumental variable discovery, as proposed by this work, feels less like a breakthrough and more like a beautifully structured deferral of difficult judgment. The framework, ‘IV Co-Scientist,’ will inevitably encounter data distributions that defy its learned heuristics, or, more predictably, causal structures far more complex than those readily available for training. Every abstraction dies in production, and this one will likely succumb to the long tail of real-world confounding.
Future iterations will undoubtedly focus on refining the LLM’s ability to assess instrument validity – a task currently reliant on the same statistical assumptions that plague traditional methods. However, a more pressing concern lies in the interpretability of the proposed instruments. A plausible instrument, divorced from domain expertise, offers little more than a statistical mirage. The field needs mechanisms to bridge the gap between LLM-generated suggestions and human understanding, lest this become another example of opaque automation.
Ultimately, this work highlights a familiar pattern: a powerful tool for scaling causal inference, but not necessarily for improving it. The true challenge isn’t automating the process, but acknowledging that every causal claim, no matter how elegantly derived, remains provisional. Everything deployable will eventually crash, and the careful documentation of those failures will prove far more valuable than any initial success.
Original article: https://arxiv.org/pdf/2602.07943.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Magicmon: World redeem codes and how to use them (March 2026)
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- Total Football free codes and how to redeem them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Simulating Humans to Build Better Robots
2026-02-11 00:04