Author: Denis Avetisyan
A new framework automates the complex process of preparing scientific data for use in artificial intelligence, accelerating the pace of discovery.
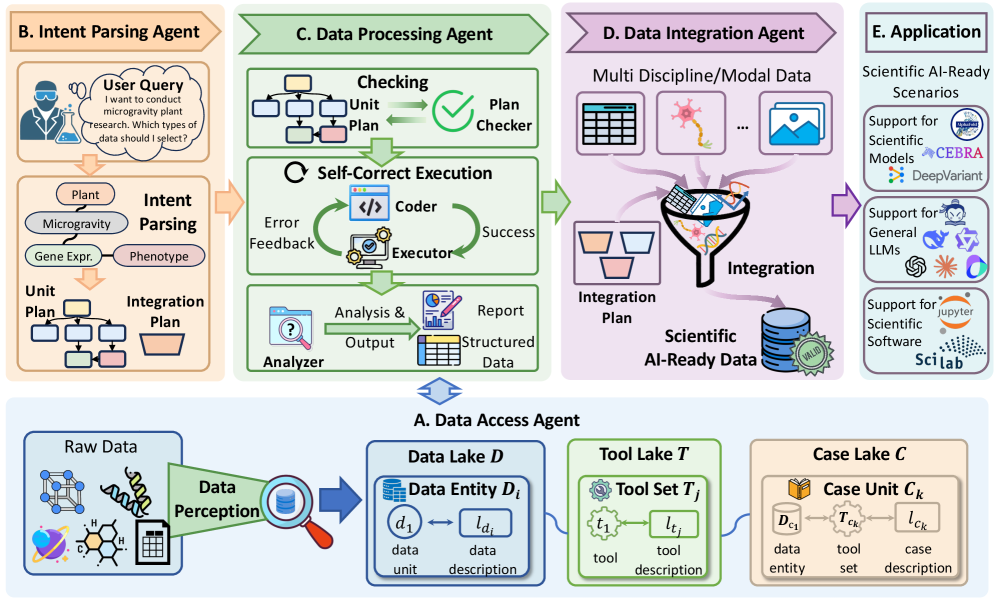
SciDataCopilot delivers an agentic workflow for transforming heterogeneous data into standardized, AI-ready resources, improving reproducibility and enabling more efficient scientific exploration.
Despite advances in artificial intelligence for science, a critical bottleneck remains the effective utilization of raw experimental data-often heterogeneous, domain-specific, and lacking direct alignment with linguistic representations. This work addresses this challenge with ‘SciDataCopilot: An Agentic Data Preparation Framework for AGI-driven Scientific Discovery’, introducing an autonomous agentic framework designed to ingest, parse, and integrate scientific data into standardized, task-aligned resources. SciDataCopilot demonstrably improves efficiency and scalability-achieving up to a [latex]30\times[/latex] speedup in data preparation across diverse scientific domains-by positioning data readiness as a core operational primitive. Could this approach pave the way for truly experiment-driven scientific general intelligence and accelerate the pace of discovery?
The Data Deluge: Why Science Drowns in Preparation
While artificial intelligence continues to demonstrate remarkable capabilities across numerous fields, a persistent challenge impedes its full potential within the scientific domain: the laborious process of preparing data for analysis. Scientific datasets, often generated from a multitude of instruments and experiments, arrive in diverse formats and require extensive cleaning, validation, and transformation before they can be effectively utilized by AI models. This preparatory phase, traditionally reliant on manual scripting and bespoke workflows, represents a significant bottleneck, consuming valuable researcher time and hindering the rapid iteration necessary for scientific discovery. The complexity isn’t simply the volume of data, but its inherent heterogeneity and the need to ensure data quality and provenance – critical aspects often overlooked in automated pipelines, yet essential for reliable scientific conclusions.
Scientific investigation increasingly relies on data originating from a vast array of HeterogeneousDataSources – instruments, simulations, and publicly available databases – creating a significant challenge for researchers. Existing data pipelines, often built upon manual scripting and ad-hoc solutions, struggle to cope with this influx of diverse formats and sheer volume. These pipelines are notably brittle, frequently breaking with even minor changes in data structure, and require substantial, time-consuming effort for maintenance and adaptation. The result is a bottleneck that impedes the efficient preparation of data for analysis, slowing scientific discovery and hindering the potential of modern machine learning techniques to unlock new insights from complex datasets.
The pervasive fragmentation of scientific data – stemming from diverse instruments, experimental setups, and analysis techniques – creates a significant barrier to both reproducible research and the effective application of artificial intelligence. Researchers often spend a disproportionate amount of time wrangling data into usable formats, a process prone to errors and difficult to consistently replicate. SciDataCopilot directly addresses this bottleneck by automating key data preparation steps, achieving a demonstrated 20x speedup compared to traditional manual workflows. This accelerated processing not only frees scientists to focus on interpretation and discovery, but also facilitates more robust and reliable results, paving the way for broader adoption of AI-driven insights across the scientific landscape.

Beyond ‘AI-Ready’: The Paradigm of Scientific Data Preparedness
The concept of `ScientificAIReadyData` represents a refinement beyond general ‘AI-Ready’ datasets by emphasizing explicit structuring and validation tailored to specific scientific tasks. Traditional ‘AI-Ready’ data often focuses on format and cleaning, whereas `ScientificAIReadyData` prioritizes the inclusion of metadata, provenance tracking, and quality assessments relevant to the intended scientific application. This means datasets are not simply prepared for machine learning ingestion, but are also accompanied by information detailing data collection methods, error analysis, and known limitations, facilitating rigorous scientific interpretation and reproducibility. The focus is on ensuring data is not only usable by AI algorithms, but also interpretable and trustworthy within a scientific context.
SciDataCopilot is an agentic framework designed to fully automate the data preparation lifecycle for scientific applications. This framework moves beyond simple data transformation by incorporating autonomous decision-making capabilities at each stage of the process, including data discovery, cleaning, transformation, and validation. It functions as a coordinated system of agents, each responsible for a specific task, and operates without requiring constant human intervention. The framework is intended to address the significant bottleneck of manual data wrangling, enabling researchers to focus on analysis rather than preparation, and ultimately accelerating scientific discovery.
The IntentParsingAgent is a core component of the SciDataCopilot framework, responsible for interpreting user-defined objectives for data preparation. This agent utilizes natural language processing to deconstruct user requests, identifying the specific scientific task and associated data transformations required. Crucially, the agent doesn’t simply execute commands; it actively maintains TaskAlignment throughout the entire data preparation lifecycle. This involves continuous verification that each automated step – from data cleaning and normalization to feature engineering – directly contributes to fulfilling the originally stated scientific intent, preventing deviations and ensuring the resulting dataset is optimized for the intended analysis.
Automated data wrangling within the Scientific AI-Ready Paradigm is designed to significantly accelerate data preparation for analysis. Benchmarking demonstrates a 20-fold increase in processing speed when compared to manual workflows performed by experienced personnel. Specifically, the Marble Point dataset, a benchmark for data processing efficiency, is processed in 3.5 minutes using the automated framework, a substantial reduction from the 75 minutes required for a proficient human operator to complete the same task. This performance gain directly addresses a key bottleneck in scientific data analysis, enabling faster iteration and improved research outcomes.
The Agentic Workflow: From Raw Signals to Actionable Knowledge
SciDataCopilot utilizes a collaborative AgenticWorkflow to manage data acquisition from varied sources. This workflow incorporates specialized agents, including the DataAccessAgent, designed to interface with HeterogeneousDataSources. These sources encompass diverse data formats and structures, requiring the DataAccessAgent to perform necessary transformations and extractions. The agentic approach enables automated data retrieval and preprocessing, mitigating the need for manual intervention and ensuring compatibility across different data types before subsequent processing stages.
The DataProcessingAgent utilizes predefined and dynamically generated data processing plans to transform raw data into a standardized format. This standardization process incorporates techniques such as unit conversion, data type normalization, and handling of missing values, ensuring consistency across HeterogeneousDataSources. By applying these consistent transformations, the agent prepares data for subsequent integration and analysis, mitigating errors that arise from inconsistent data representation. This is critical for reliable downstream processing and the generation of accurate ScientificAIReadyData.
The DataIntegrationAgent serves as the final component in the workflow, responsible for compiling processed data from various sources into a standardized ScientificAIReadyData format. This unified format ensures data consistency and compatibility for downstream analysis by AI models, facilitating tasks such as machine learning and statistical modeling. The agent handles data type conversions, schema alignment, and the resolution of conflicting information, delivering a cohesive dataset suitable for scientific investigation. The resulting ScientificAIReadyData incorporates metadata describing data provenance, processing steps, and quality metrics, enhancing reproducibility and trust in the derived insights.
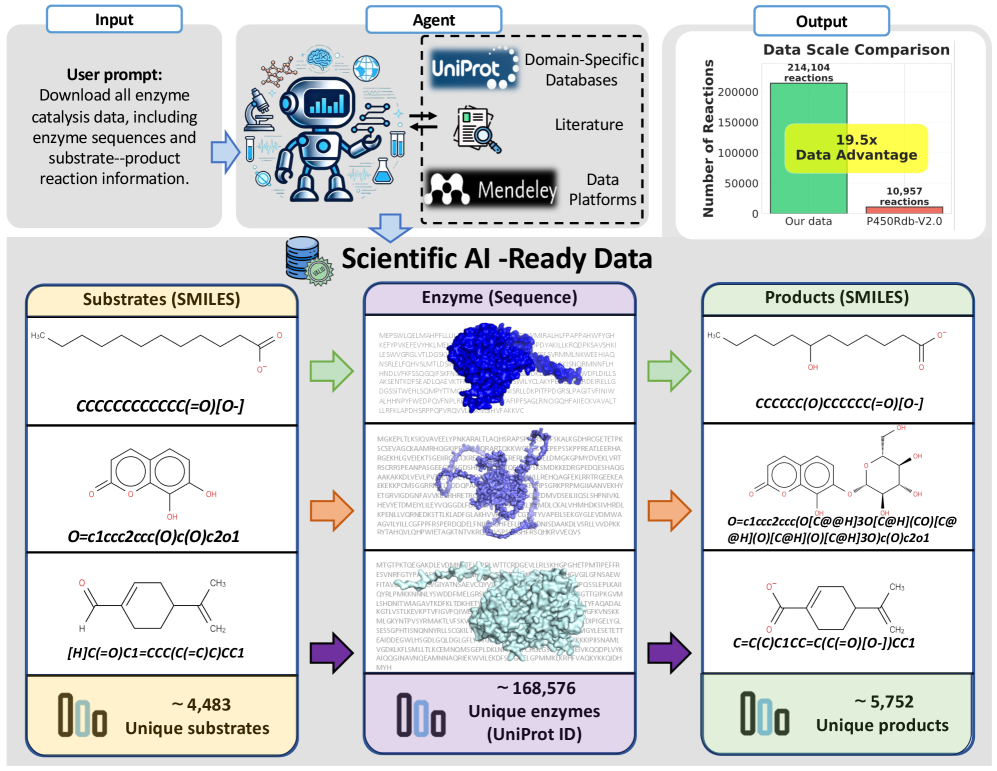
Performance evaluations utilizing the AgenticWorkflow framework demonstrate significant efficiency gains across multiple scientific domains. End-to-end task completion for neuroscience datasets averaged between 9.2 and 15.6 minutes, representing a substantial reduction compared to the 30-51.9 minutes required for a human expert to perform the same tasks. Data curation efforts have resulted in the creation of a dedicated Enzyme Catalysis Database containing 214,104 records, which is 19.5 times larger than the previously available P450Rdb-v2.0 database.
![The Data Access Agent processes user queries and dataset directories to generate a scientific knowledge base [latex]\mathcal{K}=\\{D,T,C\\}[/latex] consisting of normalized data, descriptors, and types for subsequent intent parsing and integration.](https://arxiv.org/html/2602.09132v1/x4.png)
Beyond Verification: Reclaiming Reproducibility in a Data-Driven Era
The foundation of reliable scientific progress rests upon reproducibility – the ability for independent researchers to obtain the same results from the same data and methods. A significant impediment to this process has historically been the inconsistent formatting and preparation of scientific datasets. This framework addresses this challenge by delivering data as ‘ScientificAIReadyData’, a consistently formatted resource designed to eliminate ambiguity and facilitate verification. By standardizing data preparation, the potential for human error is minimized, and researchers can confidently build upon existing work, knowing the underlying data is readily comparable and reusable. This focus on standardized, accessible data isn’t merely about convenience; it’s about strengthening the validity of scientific findings and accelerating the overall pace of discovery.
The consistent challenge of human error in data preparation has long threatened the reliability of scientific findings. Manual processes, even with diligent researchers, introduce opportunities for inconsistencies, transcription mistakes, and biases that can subtly skew results. Automating this critical stage dramatically minimizes such risks by applying standardized procedures consistently across entire datasets. This automation isn’t simply about speed; it’s about establishing a transparent, verifiable lineage for every piece of data, allowing independent researchers to replicate analyses with confidence and validate published conclusions. By removing subjective human input from the initial data handling, the potential for unintentional errors is significantly reduced, bolstering the overall integrity and trustworthiness of scientific research.
The standardization of scientific data preparation promises to dramatically reshape how research is conducted, moving beyond isolated efforts towards a more collaborative ecosystem. By minimizing the barriers to data access and verification, researchers can readily build upon each other’s work, fostering a cycle of rapid innovation. This interconnectedness isn’t simply about sharing information; it allows for the pooling of resources, expertise, and computational power, enabling investigations of a scale and complexity previously unattainable. Consequently, the time required to translate raw data into actionable insights is substantially reduced, accelerating the overall pace of scientific discovery and potentially unlocking solutions to pressing global challenges with unprecedented speed.
The future of scientific investigation hinges on a shift in focus, allowing researchers to prioritize hypothesis and inquiry over the traditionally laborious task of data preparation. A new paradigm, facilitated by tools like `SciDataCopilot`, promises to automate these complexities, delivering an estimated 20x speedup in data readiness. This acceleration isn’t merely about efficiency; it unlocks the potential for significantly larger, standardized datasets – resources previously unattainable due to time and resource constraints. By removing the bottleneck of data wrangling, the scientific community can unlock deeper insights, accelerate discovery, and foster a more collaborative and productive research landscape, ultimately enabling a data-driven approach to solving complex challenges.
The pursuit of AI-ready scientific data, as detailed in this framework, isn’t simply a technical challenge – it’s an exercise in acknowledging inherent systemic unpredictability. SciDataCopilot attempts to navigate this complexity by automating data preparation, yet even the most sophisticated agentic workflows operate within the bounds of incomplete information. As G. H. Hardy observed, “The essence of mathematics lies in its freedom from empirical reality.” This resonates with the presented work; while grounded in the practicalities of data integration and standardization, the framework implicitly recognizes that complete data certainty is an illusion. Monitoring, in this context, becomes the art of fearing consciously – anticipating the inevitable ‘revelations’ that arise from imperfect data and complex interactions. true resilience, therefore, begins where certainty ends.
What’s Next?
The pursuit of ‘AI-ready’ data, as embodied by SciDataCopilot, invites scrutiny. To standardize is to anticipate future inadequacy; each curated dataset is a prophecy of the questions it cannot answer. The framework’s success will not be measured by the volume of data processed, but by the elegance of its failures – the points at which its assumptions break, revealing the gaps in existing knowledge. A system that never breaks is, effectively, dead; it has ceased to learn.
Future work must address not simply the automation of data preparation, but the automation of error. The true challenge lies in building systems that anticipate their own obsolescence, gracefully degrading rather than catastrophically failing when confronted with genuinely novel data. This requires a shift in focus from ‘ground truth’ to ‘plausible falsehoods’ – embracing uncertainty as a fundamental property of scientific inquiry.
Perfection, in this context, leaves no room for people. The ultimate goal should not be to replace human curation, but to augment it – to create tools that amplify human intuition and creativity, rather than attempting to replicate them. The most fruitful avenue for research may not be the pursuit of ever-more-sophisticated algorithms, but a deeper understanding of the uniquely human qualities that drive scientific discovery.
Original article: https://arxiv.org/pdf/2602.09132.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Magicmon: World redeem codes and how to use them (March 2026)
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Simulating Humans to Build Better Robots
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
2026-02-11 12:56