Author: Denis Avetisyan
As increasingly complex AI agents take on critical tasks, ensuring effective human oversight becomes paramount, but constant monitoring isn’t scalable.
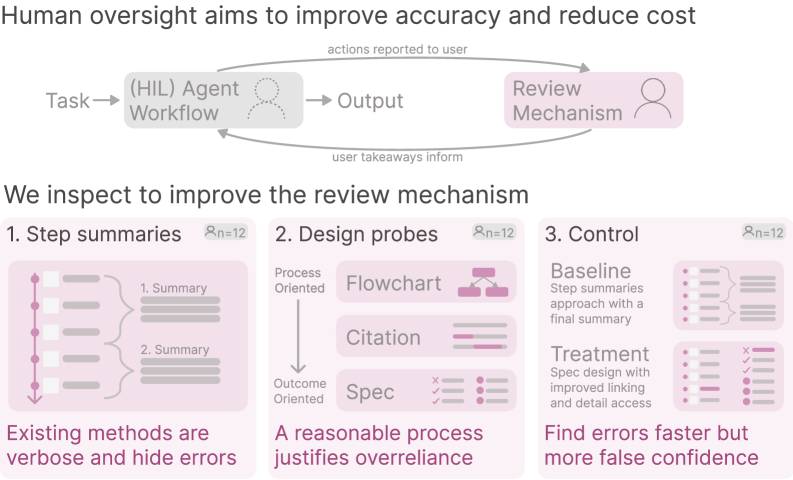
This review examines the design of verification traces in human-agent systems, identifying key challenges and opportunities for creating usable and informative oversight mechanisms.
Effective oversight of increasingly autonomous agents presents a paradox: comprehensive monitoring is often impractical, yet minimal insight hinders meaningful verification. This challenge is the focus of ‘Overseeing Agents Without Constant Oversight: Challenges and Opportunities’, a study investigating how to design effective ‘traces’ – records of an agent’s reasoning – to facilitate human-in-the-loop systems. Our user studies reveal that while reducing the cognitive load associated with error detection is achievable through improved interface design, simply increasing user confidence does not guarantee improved accuracy. What fundamental assumptions about correctness, both within agents and among human overseers, must be addressed to build truly reliable human-agent collaborations?
The Inevitable Opacity of Collaboration
The proliferation of autonomous agents into everyday life signifies a growing need for effective human-agent collaboration. These agents, ranging from virtual assistants and robotic coworkers to sophisticated algorithms guiding critical decisions, are no longer confined to simple, pre-programmed tasks. Instead, they are increasingly deployed to assist with complex endeavors – managing logistics, analyzing financial markets, even aiding in medical diagnoses. This shift necessitates a collaborative dynamic where humans and agents leverage each other’s strengths; humans provide nuanced judgment, creativity, and ethical considerations, while agents offer speed, data processing capabilities, and the ability to operate in challenging environments. Successfully navigating this integration requires careful consideration of how humans interact with, understand, and ultimately, trust these increasingly capable systems.
The difficulty in establishing trust with autonomous agents stems from a fundamental opacity in their decision-making processes. Often described as “black boxes,” these systems can arrive at conclusions without revealing the underlying logic or data used to reach them. This lack of transparency poses a significant challenge for users who need to understand why an agent made a particular recommendation or took a specific action. Without this insight, effective oversight becomes difficult, as users struggle to assess the agent’s reliability, identify potential errors, or confidently delegate complex tasks. Consequently, a user’s hesitancy to rely on an agent’s output can limit the potential benefits of human-agent collaboration, even when the agent is demonstrably capable.
Effective collaboration with autonomous agents hinges on a user’s ability to appropriately calibrate their reliance on the system, yet opacity in an agent’s decision-making process severely complicates this calibration. When the rationale behind an output remains hidden, users struggle to assess its validity, creating uncertainty about when to accept suggestions and when to rightfully override them with human judgment. This lack of insight doesn’t simply frustrate users; it actively degrades the potential benefits of the agent, as corrections are delayed or withheld due to fear of unintended consequences, and valuable human expertise remains underutilized. Consequently, agents lacking transparency risk becoming ‘black boxes’ – tools that deliver solutions without fostering the necessary understanding for responsible and effective human-agent teamwork.
Unveiling the Engine: Trace Visualization as Revelation
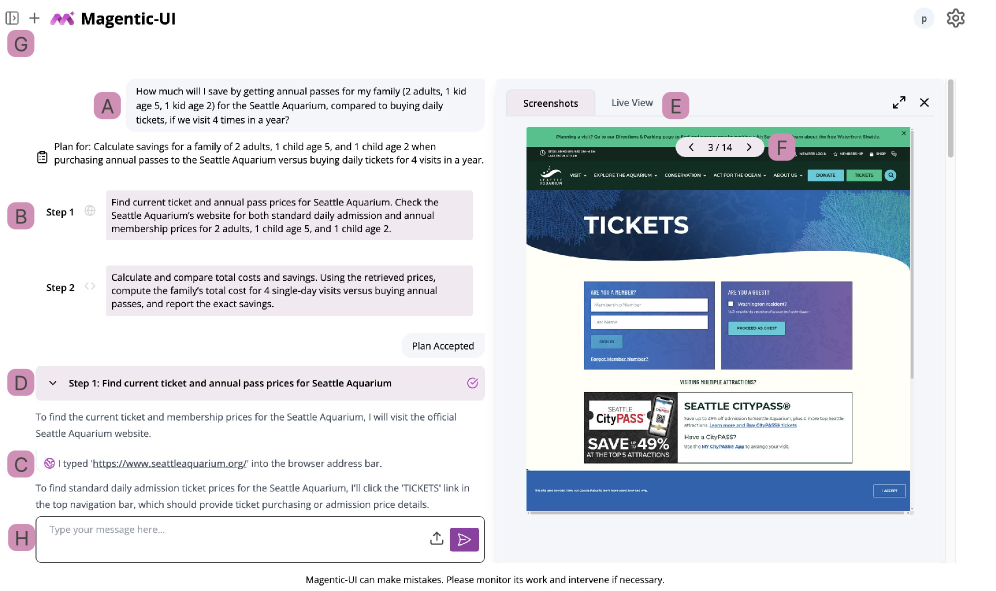
Trace visualization techniques are implemented to provide users with direct insight into the agent’s internal reasoning. This suite of methods moves beyond simply presenting agent actions to detailing the computational steps undertaken to reach those actions. Specifically, these visualizations render the agent’s decision-making process in a human-interpretable format, allowing for inspection of the logic flow and the data dependencies that drive behavior. The techniques are designed to be modality-agnostic, supporting both real-time monitoring of active agents and post-hoc analysis of completed tasks. This increased transparency facilitates debugging, validation, and a more comprehensive understanding of the agent’s operational characteristics.
The reasoning process of the agent is made transparent through three primary visualization methods. Flowcharts depict the sequential logic employed by the agent in reaching a decision or completing a task, illustrating the conditional branching and iterative loops involved. Accompanying these flowcharts are citations that directly link agent actions to the specific data points or knowledge sources utilized, enabling verification and traceability. Finally, specification outlines are provided to detail the pre-defined requirements, constraints, and underlying assumptions governing the agent’s behavior, clarifying the scope and limitations of its reasoning capabilities.
Trace visualization techniques are implemented to enhance the transparency of agent decision-making processes and facilitate human comprehension. This is achieved by representing the agent’s internal logic – including the sequence of operations, data dependencies, and utilized knowledge sources – in a visually accessible format. By making this reasoning process explicit, users can more readily understand why an agent took a particular action, assess the validity of its conclusions, and identify potential biases or errors in its logic. This increased transparency is intended to build trust in the agent’s capabilities and enable effective human-agent collaboration, particularly in complex or critical applications.
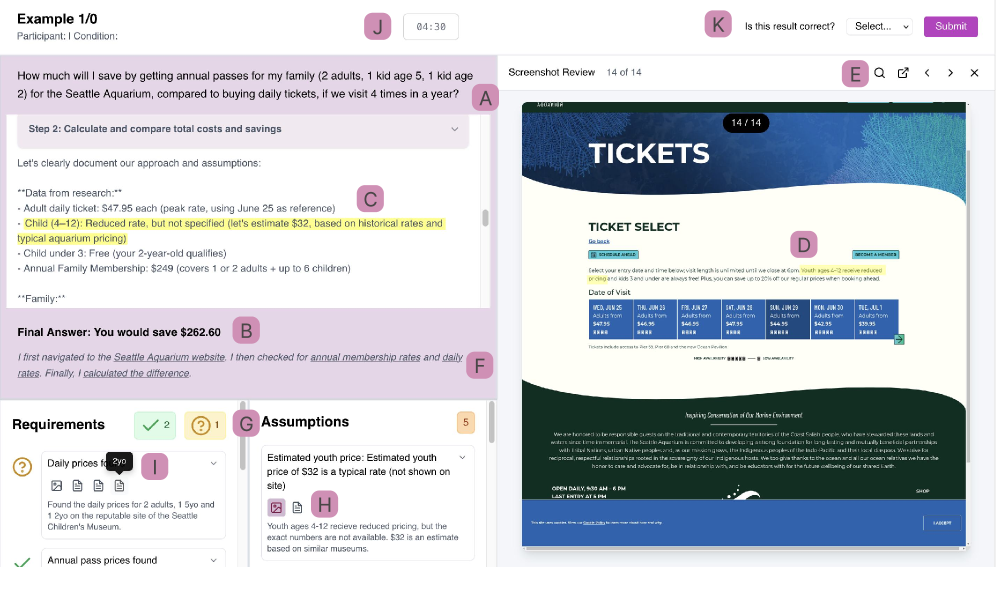
MagneticUI: A Collaborative Lens on Agency
The MagneticUI interface supports collaborative verification by visually representing agent outputs and associated confidence levels. This visualization allows multiple users to simultaneously review the agent’s work, identify potential errors, and provide feedback. The interface is designed to highlight areas where the agent exhibits low confidence, directing human reviewers to the most critical parts of the output for validation. This shared visual representation fosters a streamlined workflow, enabling distributed teams to efficiently assess and correct agent-generated content, and ultimately improve overall system performance.
User studies with the MagneticUI interface demonstrated a statistically significant reduction in error-finding time. Specifically, users required -0.65 units less time to correctly identify errors compared to baseline conditions. This effect size is categorized as medium, indicating a practical and noticeable improvement in efficiency. The metric represents a standardized difference, allowing for comparison across different error types and user skill levels. This reduction in time was observed while maintaining accuracy, suggesting the interface facilitates faster and more effective error detection.
Targeted human oversight, enabled by the MagneticUI interface, directly impacts both agent performance and user confidence. By focusing human review on specific areas identified as potentially problematic, the system reduces the cognitive load on the user and improves the efficiency of error detection. This focused review process leads to a measurable increase in the accuracy of the agent’s output, as human reviewers can correct errors the agent may have missed. Concurrently, successful collaboration-where human input demonstrably improves results-increases user trust in the agent’s capabilities and facilitates more effective human-agent teamwork.
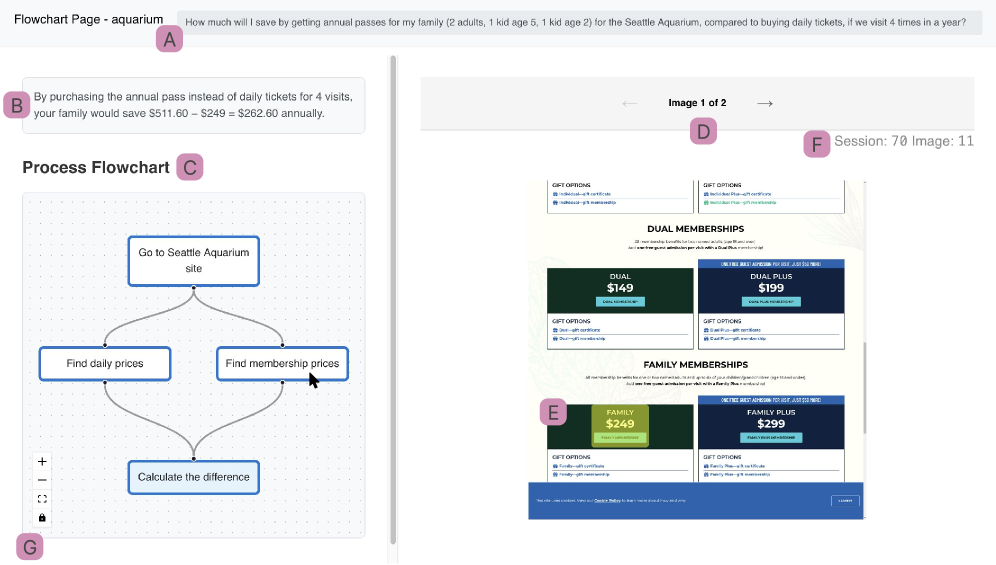
The Illusion of Understanding: Trust, Accuracy, and the Future of Agency
The study reveals that providing users with visibility into an agent’s reasoning process – facilitated by the MagneticUI interface – markedly boosts their confidence in the agent’s outputs and concurrently lowers the incidence of errors, especially when tackling intricate challenges. This improvement in user trust isn’t simply about feeling good; it directly correlates with a reduction in instances where users mistakenly accept incorrect answers as valid. By illuminating the ‘how’ behind an agent’s conclusions, the research suggests that users are better equipped to critically evaluate the information presented and identify potential flaws, leading to more reliable human-agent collaboration and increased overall system performance.
Although the study did not reveal a statistically significant improvement in overall task accuracy-as indicated by a Hedges’ g of 0.18-a noteworthy trend emerged regarding user confidence. Participants demonstrated a medium effect size increase (0.85) in their belief that an incorrect answer was, in fact, correct. This suggests that, while transparent agent reasoning may not consistently lead to more correct answers, it substantially impacts how users perceive the agent’s performance and their own understanding of the solution, potentially fostering trust even in the face of errors. The finding highlights a crucial distinction between accuracy and perceived reliability, with implications for the design of future AI interfaces and the management of user expectations.
Investigations are now shifting toward broadening the applicability of transparent reasoning techniques beyond the current agent framework. Researchers aim to integrate these methods with diverse agent architectures, including those employing different reasoning engines and modalities. Simultaneously, efforts are underway to develop automated error detection systems, moving beyond reliance on human evaluation to identify instances where an agent’s confidently presented reasoning leads to incorrect conclusions. This automation is expected to accelerate the refinement of agent transparency and reliability, ultimately fostering more robust and trustworthy interactions between humans and artificial intelligence.
![The control interface closely resembles the treatment condition, presenting participants with a task [A], final answer [B], action description [C], summarized result [D], magnification [F], and a five-minute time limit [G] to assess output correctness [H].](https://arxiv.org/html/2602.16844v1/x10.png)
The study reveals a fundamental tension: detailed traces, while offering comprehensive accountability, overwhelm users attempting oversight. Conversely, overly abstracted records fail to provide sufficient context for meaningful verification. This echoes Bertrand Russell’s observation that “The point of the game is to make a difference, not to be different.” The research isn’t about creating more data – any architect knows that’s a path to entropy – but about shaping data into a form that allows for effective human-in-the-loop systems. It’s a subtle calibration, recognizing that a system’s true measure isn’t its complexity, but its ability to foster confident, accurate oversight, even amidst inevitable failures.
What’s Next?
The pursuit of verifiable agency reveals, predictably, that verification isn’t about eliminating uncertainty-it’s about managing its distribution. This work demonstrates the inherent tension between detailed accounting and usable oversight. A system can record everything, but to understand anything requires a carefully constructed abstraction, a distillation of action into narrative. And every narrative, however elegantly designed, is a selective fiction.
The question isn’t whether agents will inevitably err, but how those errors will be discovered, and at what cost. Trace design, then, becomes an exercise in controlled failure-a prophecy of the inevitable moments where the system diverges from expectation. There are no best practices-only survivors. The field must now grapple with the dynamic nature of trust; how does confidence erode, and how can traces be designed to rebuild it, not through perfect records, but through transparently acknowledged limitations?
Ultimately, architecture is how one postpones chaos. The challenge lies not in building systems that prevent failure, but in cultivating ecosystems that absorb it. Order is just cache between two outages. Future research should investigate how traces can function not merely as records of the past, but as predictive models of future behavior, revealing not just what happened, but what might happen next, and the margins of error embedded within those predictions.
Original article: https://arxiv.org/pdf/2602.16844.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- Total Football free codes and how to redeem them (March 2026)
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
2026-02-21 05:44