Author: Denis Avetisyan
A new report dives deep into the capabilities and limitations of today’s most advanced AI agent systems, revealing crucial insights into their development and deployment.
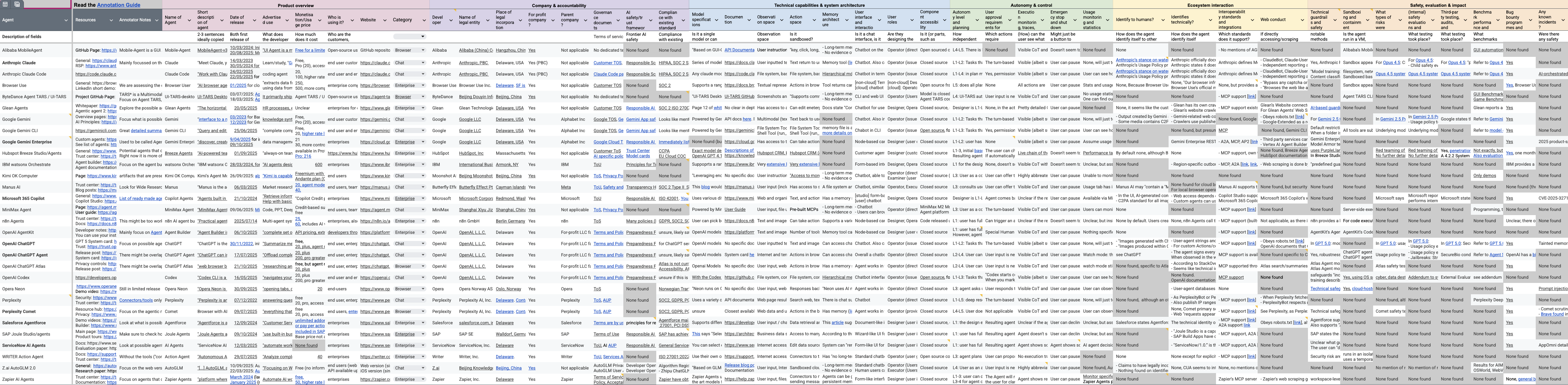
This paper presents the 2025 AI Agent Index, a detailed analysis of 30 prominent AI agent systems documenting technical features, safety protocols, and evaluation practices.
Despite the increasing prevalence of autonomous AI agents, comprehensive documentation of their capabilities and safety features remains surprisingly limited, hindering both research and responsible deployment. To address this gap, we present ‘The 2025 AI Agent Index: Documenting Technical and Safety Features of Deployed Agentic AI Systems’, a detailed analysis of 30 state-of-the-art AI agent systems. Our Index reveals substantial variation in developer transparency, particularly regarding safety evaluations and societal impact assessments. As these agents become increasingly integrated into daily life, will improved documentation and standardized evaluation metrics emerge to foster greater trust and accountability?
The Inevitable Shift: Beyond Reactive Artificiality
Conventional artificial intelligence often falters when confronted with tasks demanding more than simple reactions; these systems typically excel at narrowly defined problems but struggle with the nuances of multi-step reasoning and unforeseen circumstances. Unlike these reactive models, truly complex challenges – those requiring planning, adaptation, and proactive intervention – present a significant hurdle. Traditional AI frequently necessitates explicit, step-by-step instructions for every contingency, proving brittle in dynamic environments. This limitation stems from their dependence on pre-programmed responses and a lack of inherent capacity to learn from experience or independently formulate solutions, hindering their application in real-world scenarios that demand flexible and autonomous problem-solving.
Agentic AI represents a significant departure from conventional artificial intelligence, moving beyond reactive responses to proactive, autonomous operation. These systems aren’t simply programmed to answer questions; instead, they are designed to independently define and pursue goals. This capability involves breaking down complex tasks into manageable steps, utilizing tools and resources as needed, and adapting strategies based on observed outcomes – essentially, problem-solving with minimal human intervention. Unlike traditional AI focused on pattern recognition or specific function execution, agentic systems exhibit a degree of agency, allowing them to not only process information but also to initiate actions and navigate dynamic environments to achieve desired results. This shift promises to unlock applications requiring adaptability and resilience, moving AI beyond assistive roles and towards genuine collaborative partnerships.
The emergence of agentic AI systems compels a rigorous investigation into their functional boundaries and broader consequences. Simply observing their outputs is insufficient; a systematic evaluation is needed to delineate what these systems can and cannot reliably achieve. This demands a move beyond traditional benchmarks, focusing instead on assessing their reasoning processes, adaptability to unforeseen circumstances, and potential for unintended biases or harmful actions. Understanding these limitations isn’t about hindering innovation, but about fostering responsible development and deployment-ensuring that agentic AI serves as a beneficial tool, rather than a source of unforeseen problems. A comprehensive approach to evaluation is therefore crucial for maximizing the potential benefits of this technology while mitigating its inherent risks.
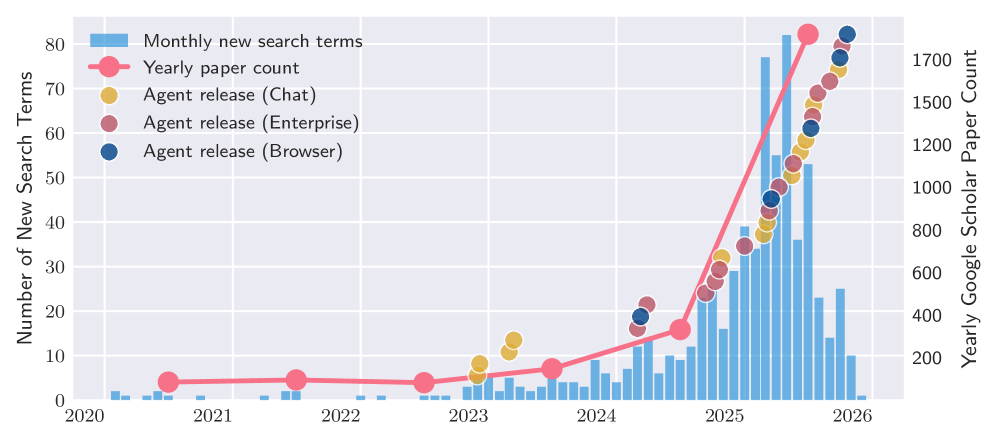
The rapid deployment of agentic AI systems across diverse applications necessitates a shift from reactive evaluation to proactive assessment of their reliability and efficacy. A recent study addressed this challenge through a comprehensive analysis of 30 distinct agentic AI systems, revealing a significant lack of standardized metrics for gauging performance and trustworthiness. This research highlights the critical need for consistent evaluation frameworks – encompassing factors like goal completion rates, resource utilization, and adherence to safety protocols – to move beyond anecdotal evidence and establish quantifiable benchmarks. Without such standardization, responsible development and deployment of these increasingly autonomous systems remain hampered, potentially limiting their benefits and exacerbating unforeseen risks. Establishing these metrics isn’t merely about technical refinement, but a fundamental step toward fostering public trust and ensuring the long-term viability of agentic AI.
Systematic Quantification: Defining Agent Capabilities
The AI Agent Index employs a standardized methodology for the collection and analysis of data pertaining to agentic AI systems. This involves the systematic recording of features, capabilities, and operational characteristics across a range of platforms. Data collection is structured around a predefined set of 45 annotation fields per agent, allowing for quantifiable comparisons. The Index aims to provide a consistent framework for evaluating and understanding the rapidly evolving landscape of AI agents, facilitating informed assessments of their functionality and limitations. This structured approach enables objective analysis and tracking of advancements within the field.
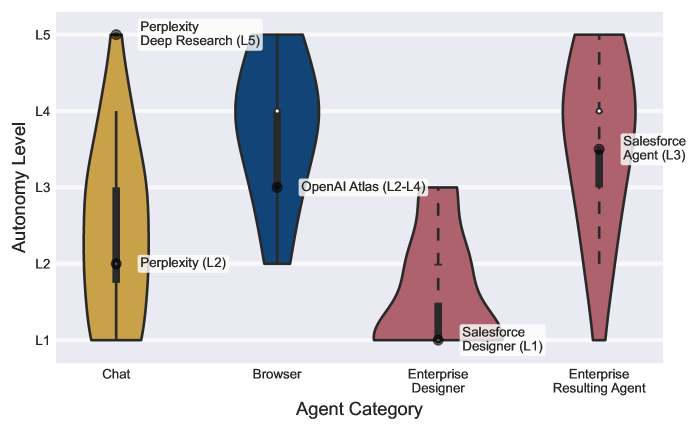
Search Volume Analysis is employed as a key metric for assessing public engagement with different agentic AI platforms. This method tracks the number of online searches related to each agent, providing data on user interest and adoption rates. Currently, the most popular agent indexed through this analysis receives a peak of 349,518 monthly search hits, indicating a substantial level of public awareness and interaction with that particular system. This data point serves as a quantifiable measure alongside more qualitative assessments of agent capabilities and transparency.
The ‘AI Agent Index’ incorporates a ‘Transparency Assessment’ to quantitatively evaluate the availability of information pertaining to the development of agentic AI systems. This assessment focuses on the clarity and accessibility of details regarding data sources, model architecture, training methodologies, safety protocols, and limitations. Evaluations are conducted across a standardized set of criteria, allowing for direct comparison of transparency levels between different agents. The goal is to provide stakeholders with a data-driven understanding of how openly and comprehensively each agent’s development process is documented, facilitating informed decision-making and responsible AI deployment.
The AI Agent Index employs a standardized evaluation framework, systematically comparing agent capabilities across 45 distinct annotation fields. These fields cover a range of characteristics, allowing for a granular comparison of different agentic AI systems. This detailed assessment enables quantitative analysis of the current landscape, moving beyond anecdotal evidence to provide a data-driven understanding of feature sets and levels of transparency present in available agents. The resulting data facilitates identification of strengths, weaknesses, and key differentiators between platforms, contributing to a more informed evaluation of agentic AI technologies.
Mitigation Through Rigor: Ensuring Agent Safety and Trust
Safety evaluation, a core tenet of responsible AI development, encompasses the systematic identification and assessment of potential harms arising from AI systems. This process extends beyond functional testing to include the analysis of biases embedded within training data, the potential for unintended consequences in deployment scenarios, and the robustness of the system against adversarial inputs. Evaluations typically involve defining specific risk categories – such as fairness, privacy, security, and societal impact – and then employing a range of techniques, including algorithmic audits, scenario-based testing, and human review, to measure and mitigate associated risks. Comprehensive safety evaluations are essential for building trust and ensuring the ethical and reliable operation of AI agents.
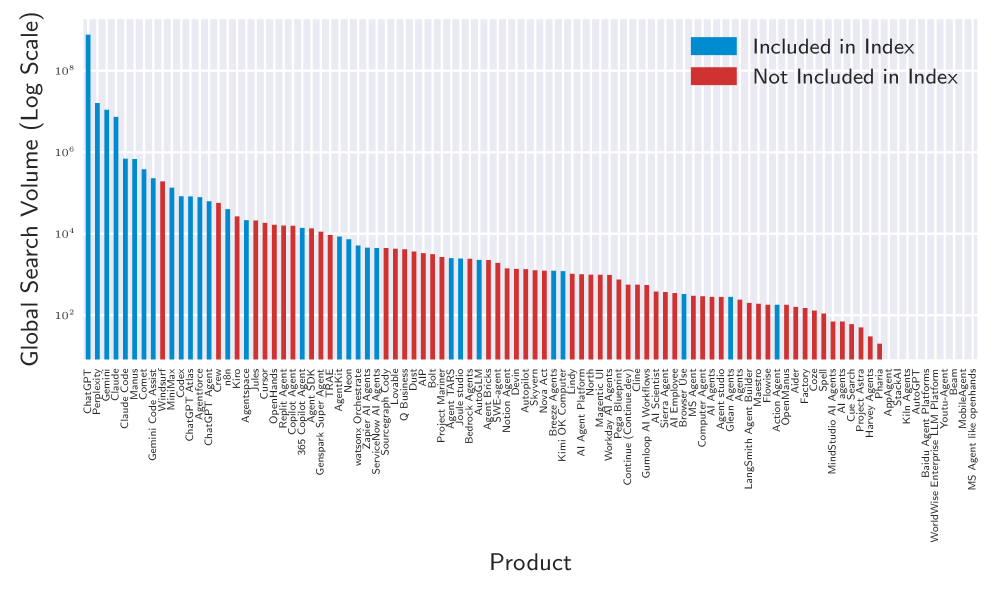
The degree of autonomy exhibited by an AI agent directly impacts the scope and complexity of required safety evaluations. Agents with high autonomy – those capable of independent decision-making and action with minimal human oversight – present a larger potential harm surface and necessitate more rigorous testing across a wider range of scenarios. Conversely, agents operating with low autonomy, functioning primarily as assistive tools under direct human control, require a comparatively less extensive evaluation focused on predictable interactions and limited decision-making capabilities. Therefore, accurately defining and documenting an agent’s autonomy level is a foundational step in establishing a proportionate and effective safety evaluation framework; insufficient understanding of autonomy can lead to either underestimation of potential risks or inefficient allocation of evaluation resources.
Red teaming, as a security assessment method, involves simulating attacks by a team of security experts acting as adversaries to identify vulnerabilities in an AI system before malicious actors can exploit them. This process goes beyond automated testing by employing creative, human-led attacks designed to bypass existing safeguards and expose weaknesses in the agent’s reasoning, decision-making, and overall robustness. Red teaming exercises commonly assess for prompt injection, data poisoning, and other adversarial inputs, providing valuable data for improving the agent’s security posture and refining its ability to handle unexpected or malicious requests. The results of these simulated attacks inform developers about potential failure modes and guide the implementation of more effective defensive measures.
Despite a growing industry emphasis on responsible AI development and the adoption of documentation practices like Model Card creation by platforms such as HubSpot Breeze Agents, publicly available, detailed safety evaluations remain limited. Our analysis indicates a low percentage of deployed agents currently possess comprehensive, publicly accessible documentation outlining potential biases, known failure modes, and mitigation strategies. This lack of transparency hinders independent verification of safety claims and impedes broader understanding of agent limitations, potentially impacting trust and responsible deployment at scale. The current disparity between prioritizing safety measures and publishing detailed evaluations suggests a gap in translating internal safety assessments into publicly verifiable documentation.
, highlights a transparency gap in AI agent development.](https://arxiv.org/html/2602.17753v1/assets/breeze_safety_screenshot.png)
Real-World Convergence: Impact and Future Directions
The application of agentic AI is rapidly diversifying, moving beyond theoretical models into practical tools already impacting daily workflows. Platforms like ChatGPT Agent exemplify this shift, offering sophisticated conversational assistance for tasks ranging from summarizing documents to generating creative content. Simultaneously, tools such as Perplexity Comet demonstrate the power of automation through browser-based agents capable of independently researching and compiling information. These examples represent a growing trend: AI agents are no longer simply responding to commands, but proactively pursuing goals and completing complex tasks with minimal human intervention, signaling a fundamental change in how humans interact with technology.
Agentic AI platforms, such as conversational assistants and browser automation tools, are rapidly moving beyond simple task completion to actively augment human abilities. These systems don’t merely respond to commands; they proactively plan, execute, and refine actions to achieve specified goals, effectively streamlining complex workflows. This shift allows individuals to offload repetitive or time-consuming processes – from research and data analysis to scheduling and communication – freeing up cognitive resources for more creative and strategic endeavors. The observed potential extends beyond increased efficiency; it suggests a future where AI agents function as collaborative partners, enhancing productivity and enabling humans to tackle increasingly complex challenges with greater ease and precision.
The burgeoning field of agentic AI, while demonstrating remarkable capabilities, necessitates sustained research and development to navigate emerging challenges and fully realize its transformative potential. Current limitations surrounding long-term planning, robust error handling, and ensuring alignment with human values demand innovative solutions. Future work must prioritize enhancing agentic systems’ capacity for complex reasoning, adaptability to unforeseen circumstances, and seamless integration into real-world workflows. Further exploration into areas like multi-agent collaboration, efficient resource management, and the development of more nuanced reward functions will be critical for unlocking the full spectrum of benefits offered by this technology, paving the way for increasingly sophisticated and reliable AI assistants across diverse applications.
The burgeoning field of agentic AI demands rigorous, consistent evaluation to build both public trust and encourage responsible development. A recent study addressed this need by introducing the ‘AI Agent Index,’ a standardized framework used to assess the capabilities of 30 diverse agents. This index moves beyond simple benchmark scores, instead focusing on real-world utility across a spectrum of tasks – from web browsing and information synthesis to complex problem-solving – and provides a comparative analysis of each agent’s strengths and weaknesses. Such a standardized approach is not merely academic; it is vital for guiding future research, informing consumer choices, and ultimately ensuring that the rapidly evolving landscape of AI agents benefits society as a whole by promoting transparency and accountability.
The 2025 AI Agent Index meticulously documents the current state of agentic AI, striving for a rigorous understanding beyond mere empirical observation. This pursuit echoes G.H. Hardy’s sentiment: “The essence of mathematics is its freedom from empirical control.” The Index, much like a mathematical proof, attempts to establish invariant properties – in this case, concerning transparency and safety – as the complexity of these AI systems, and ‘N’ – the number of agents deployed – approaches infinity. The report doesn’t simply catalog features; it seeks underlying principles that remain consistent, providing a foundation for evaluating and governing these increasingly sophisticated systems, independent of specific implementation details or fleeting performance metrics.
The Road Ahead
The 2025 AI Agent Index reveals a curious state of affairs. Thirty systems are dissected, features cataloged, yet the fundamental question of reproducibility remains largely unaddressed. A claimed safety feature, absent a rigorous, deterministic proof of its behavior across all conceivable inputs, is little more than optimistic assertion. The field continues to prioritize empirical demonstration-‘it works on our tests’-over mathematical certainty. This is, frankly, unsatisfying.
Future iterations of this Index must move beyond descriptive analysis. The focus should shift to verifiable properties. Can an agent’s decision-making process be formally modeled? Can its safety constraints be proven, not merely tested? The current emphasis on scale – larger models, more data – feels increasingly like a distraction from these core issues. Increased complexity without commensurate rigor only amplifies the potential for unpredictable, and therefore dangerous, behavior.
Ultimately, the value of such an Index lies not in documenting what is, but in illuminating what must be. A truly useful agent evaluation framework will not celebrate novelty; it will demand proof. Until then, the “agentic AI landscape” remains a fascinating, but fundamentally insecure, construction.
Original article: https://arxiv.org/pdf/2602.17753.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-23 07:49