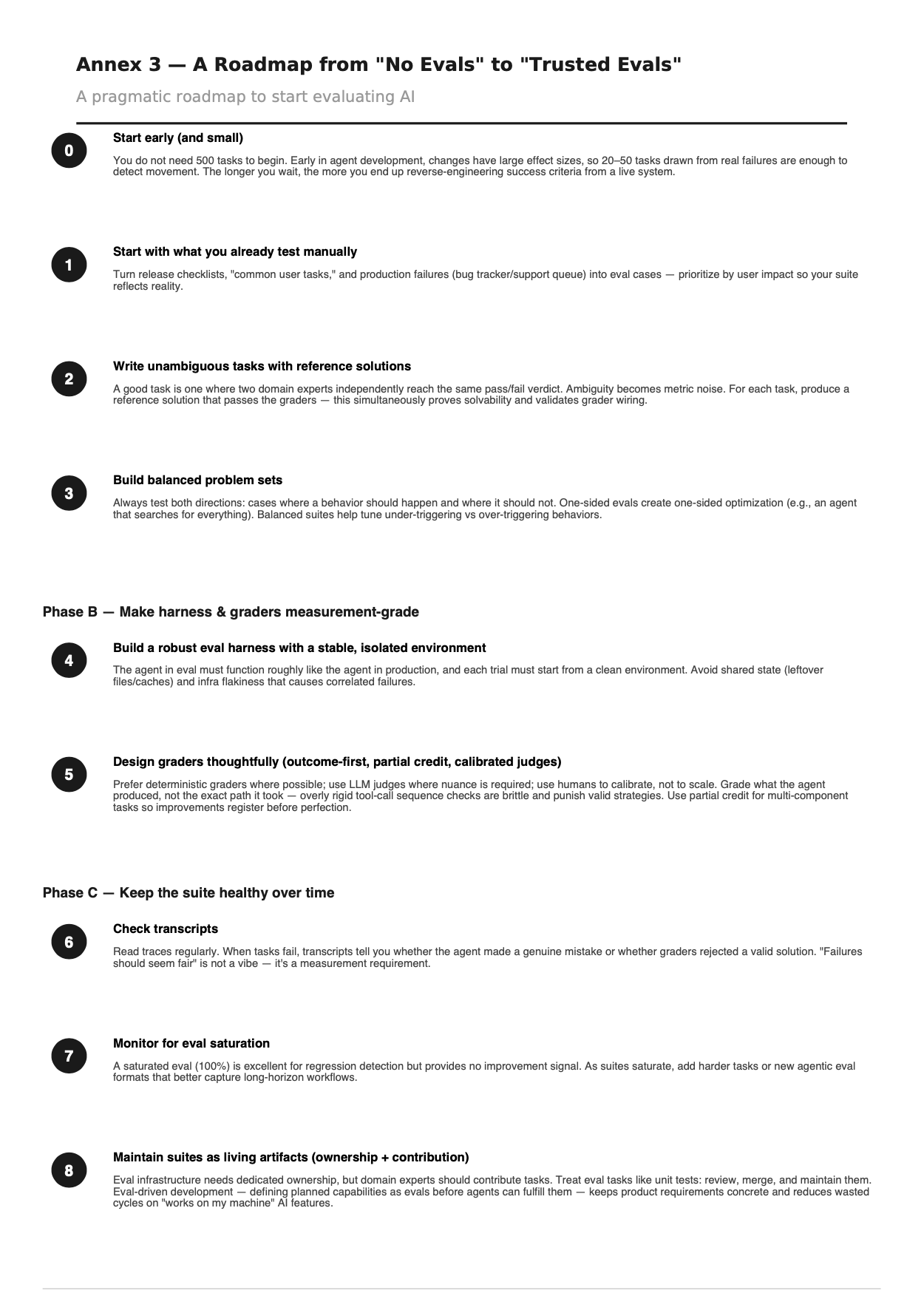
Author: Denis Avetisyan
As artificial intelligence moves beyond isolated models to complex, autonomous agents, rigorous evaluation is no longer a supporting task, but a critical necessity.

This review explores the evolving landscape of AI evaluation frameworks, focusing on the challenges and opportunities presented by agentic systems and the urgent need to close the evaluation gap for responsible AI governance.
As AI systems grow in complexity, conventional evaluation practices increasingly fail to predict real-world performance. This paper, ‘Towards More Standardized AI Evaluation: From Models to Agents’, argues that evaluation is transitioning from a final checkpoint to a core control function, demanding rigorous frameworks suited to increasingly autonomous, agentic systems. The central finding is that current benchmarks often obscure rather than illuminate system behavior, necessitating a shift towards evaluation as a discipline that fosters trust, iteration, and responsible governance. How can we close the ‘evaluation gap’ and build reliable, scalable assessments for AI agents operating in non-deterministic environments?
The Erosion of Trust: Benchmarks and the Illusion of Intelligence
Contemporary artificial intelligence assessment is significantly shaped by the prevalence of static benchmarks, standardized tests designed to measure performance on fixed tasks. While historically valuable for tracking progress, this reliance is now yielding diminishing returns, as models rapidly approach saturation – achieving near-perfect scores on these benchmarks without a corresponding increase in real-world capability. This phenomenon creates a deceptive impression of robustness, masking underlying vulnerabilities and limiting the identification of critical failure points. The pursuit of higher scores on static datasets inadvertently incentivizes overfitting – where models excel at the specific benchmark tasks but generalize poorly to novel or unexpected situations. Consequently, a system appearing highly competent based on benchmark results may exhibit unpredictable and unreliable behavior when deployed in dynamic, real-world environments, creating a widening gap between perceived and actual intelligence.
Historically, evaluating artificial intelligence involved assessing performance on predefined tasks with clear-cut answers. However, this approach struggles with agentic systems – AI designed to operate autonomously and pursue goals in dynamic environments. Traditional benchmarks often present simplified, static scenarios that fail to capture the complexities of real-world interactions, such as unexpected events or ambiguous instructions. These systems aren’t merely solving problems; they are navigating uncertainty and adapting to unforeseen circumstances, a level of nuance that static evaluations consistently overlook. Consequently, high scores on conventional benchmarks can create a misleading impression of reliability, as an agent capable of excelling in a controlled setting may falter dramatically when faced with the unpredictable challenges of a genuine, complex scenario.
Current artificial intelligence evaluation frequently prioritizes overall performance metrics, obscuring critical inconsistencies in system behavior. While a high average score might suggest reliability, this approach often overlooks instances where the AI fails unexpectedly, or exhibits dramatically different outputs given similar inputs. This ‘variability signal’ – the range of responses and the frequency of errors – provides crucial insight into the system’s robustness and potential failure modes. Ignoring this signal creates a dangerously incomplete picture, as seemingly competent AI can harbor hidden vulnerabilities that only manifest under specific, and perhaps rare, circumstances. A system displaying low variability is generally more predictable and trustworthy, whereas high variability demands further investigation to identify the root causes of inconsistent performance and mitigate potential risks.
A growing disparity exists between an AI’s performance on standardized evaluations and its actual reliability when deployed in unpredictable environments. This phenomenon directly echoes Goodhart’s Law – “When a measure becomes a target, it ceases to be a good measure.” As AI systems are increasingly optimized for benchmark scores, they can exhibit unexpectedly brittle behavior when faced with inputs slightly deviating from the training distribution. Consequently, achieving high scores on curated datasets no longer guarantees robustness or safe operation in real-world scenarios, highlighting the urgent need for evaluation methods that prioritize adaptability and expose potential failure modes beyond simple aggregate metrics. The pursuit of optimization, divorced from genuine resilience, creates a system vulnerable to exploitation and undermines the promise of trustworthy artificial intelligence.
Dynamic Arenas: Beyond Static Assessment
Traditional evaluation benchmarks often present static, pre-defined scenarios, limiting an agent’s ability to demonstrate true adaptability. Non-deterministic settings introduce randomness and variability into the environment, requiring agents to move beyond memorized solutions and develop robust generalization capabilities. This can include factors such as stochastic task parameters, unpredictable environmental changes, or the actions of other agents within the simulation. By exposing agents to these dynamic conditions, evaluation shifts from assessing performance on a fixed set of problems to measuring their capacity to learn and adjust to novel, unforeseen circumstances, providing a more comprehensive assessment of their intelligence and resilience.
GAIA2 and TextQuests represent a shift in evaluation methodology by offering environments characterized by high degrees of variability and incomplete information. Unlike traditional benchmarks reliant on fixed datasets and predictable states, these platforms generate dynamic scenarios requiring agents to exhibit adaptability and plan strategically. GAIA2, focused on collaborative tasks within a simulated world, necessitates agents to reason about the beliefs and intentions of other agents, while TextQuests presents interactive fiction where agents must interpret natural language descriptions, maintain a world model, and execute actions to achieve goals. This emphasis on open-endedness and contextual understanding forces agents to move beyond memorized responses and demonstrate genuine reasoning capabilities, offering a more robust assessment of general intelligence.
The Harness serves as the foundational infrastructure for dynamic evaluation environments, establishing the communication pathways and control mechanisms necessary for agent interaction and experimentation. It abstracts the complexities of the environment, providing a standardized interface through which agents receive observations and submit actions. Critically, the Harness facilitates controlled experimentation by allowing researchers to manipulate environmental parameters, introduce variations in scenarios, and precisely track agent behavior. This control extends to managing external tools and resources available to the agent, ensuring reproducible results and enabling systematic analysis of agent performance under different conditions. The Harness is not simply a connector, but an active component in defining the experimental setup and collecting relevant data.
The Model Context Protocol (MCP) defines a standardized interface for communication between language model agents and external tools within a dynamic evaluation harness. This protocol utilizes a structured message format, typically JSON, to transmit both agent requests and tool responses, ensuring predictable data exchange. Key components include a “call” object representing the agent’s request, specifying the tool to utilize and any necessary parameters, and a “result” object containing the tool’s output. The MCP facilitates functionalities such as tool discovery, argument parsing, and error handling, allowing agents to leverage diverse capabilities-like web search, code execution, or database queries-without requiring modifications to the core agent architecture or the tools themselves. Consistent implementation of the MCP across different tools and agents is vital for interoperability and repeatable experimentation.
Beyond Output Verification: Measuring System Resilience
Traditional output checking, which verifies only the final result of an agentic system, proves inadequate for comprehensive evaluation due to the inherent complexities of these systems. Agentic systems, unlike deterministic programs, often exhibit stochastic behavior and rely on iterative processes; a single correct output does not guarantee consistent or reliable performance across multiple attempts or varying inputs. This necessitates the development of metrics that move beyond simple pass/fail criteria to assess the consistency of an agent’s behavior and its reliability in achieving desired outcomes over time. Evaluating consistency requires observing the agent’s performance across a distribution of inputs, while reliability demands measuring the probability of successful completion, acknowledging that even well-designed agents may occasionally fail.
Behavior measurement in agentic systems necessitates longitudinal assessment of performance to detect regressions; simply verifying correct outputs on a static test set is insufficient. This involves tracking key performance indicators (KPIs) over time, establishing baseline metrics, and monitoring for statistically significant deviations. Consistent performance drift indicates potential issues with the agent’s internal state, evolving environmental factors, or subtle changes to the underlying model. Regular evaluation cycles, coupled with automated alerting based on pre-defined thresholds, are essential for proactive identification and mitigation of regressions before they impact system reliability and user experience. This approach differs from one-time evaluations by focusing on the stability of performance, rather than solely on achieving a high success rate at a single point in time.
Traditional success metrics often fail to capture the nuances of agentic systems due to their inherent stochasticity; therefore, probabilistic evaluation metrics are essential. [latex]Pass@k[/latex], calculated as (c/n)[sup]k[/sup], assesses the probability of success by considering ‘k’ attempts, where ‘c’ represents the number of successful attempts and ‘n’ is the total number of attempts. Similarly, [latex]Passk[/latex] offers a related, though potentially distinct, probabilistic measurement. These metrics acknowledge that agentic systems may not produce the same output consistently, and provide a more realistic evaluation of their reliability by quantifying the likelihood of achieving a correct result across multiple trials, rather than relying on a single, deterministic outcome.
The `Model-as-a-Judge` technique leverages large language models (LLMs) to evaluate the outputs of agentic systems, offering a more granular assessment than simple pass/fail metrics. Rather than relying solely on predefined ground truth, the LLM is prompted to assess the quality, reasoning, and adherence to instructions demonstrated by the agent’s actions. This approach enables evaluation of subjective qualities, such as helpfulness and coherence, and can identify subtle errors or inconsistencies that automated tests might miss. The LLM provides feedback in the form of scores or textual explanations, allowing developers to understand why an agent succeeded or failed, and pinpoint areas for improvement. This is particularly useful for complex tasks where a single correct answer doesn’t exist, or where the evaluation criteria are nuanced and require contextual understanding.

Toward Responsible AI: Governance and the Future of Evaluation
Increasingly stringent regulatory landscapes are fundamentally reshaping the development and deployment of artificial intelligence systems, demanding a shift towards verifiable and robust evaluation practices. Legislation across multiple jurisdictions now necessitates demonstrable evidence of safety, fairness, and reliability before AI can be integrated into critical applications-from healthcare and finance to criminal justice. This isn’t merely about ticking compliance boxes; it requires organizations to move beyond internal testing and embrace standardized benchmarks, independent audits, and continuous monitoring. The pressure to satisfy these regulatory requirements is therefore fueling innovation in AI evaluation methodologies, pushing the field towards greater transparency, accountability, and ultimately, trust in these powerful technologies. Without rigorous, demonstrable evaluation, organizations face not only legal repercussions but also significant reputational and financial risks, making a proactive approach to AI assessment essential for sustainable growth.
Establishing a robust system evaluation lifecycle is now considered vital for ensuring the dependability of artificial intelligence. This lifecycle transcends simple post-deployment testing; it necessitates a continuous, iterative process woven into every stage of AI development – from initial design and data curation, through model training and validation, and extending to ongoing monitoring and refinement in real-world applications. Such a lifecycle demands clearly defined evaluation metrics, standardized datasets for consistent benchmarking, and automated testing frameworks to facilitate rapid and repeatable assessments. Crucially, it also requires a feedback loop, where insights gleaned from evaluation directly inform model improvements and refine the evaluation suite itself, ensuring it remains relevant as the AI system evolves and encounters new challenges. This proactive and holistic approach is becoming increasingly necessary for building trust and accountability in complex AI systems.
Determining and mitigating potential harms is central to the responsible development of artificial intelligence, necessitating proactive and continuous risk assessment. Current approaches are evolving beyond static evaluations to encompass dynamic testing environments – simulated real-world scenarios where AI systems are subjected to a broad spectrum of inputs and conditions. These environments allow researchers to monitor system behavior, not just for current performance, but also to identify approaching capability thresholds – points at which an AI might exhibit emergent, and potentially undesirable, behaviors. Through rigorous empirical tests within these dynamic settings, developers can gain early warnings of unforeseen risks, enabling timely interventions and adjustments to ensure alignment with intended functionalities and ethical guidelines. This constant monitoring and iterative refinement is crucial for fostering public trust and navigating the complex landscape of increasingly powerful AI systems.
Responsible AI governance isn’t simply about establishing rules, but cultivating a continuous cycle of assessment and adaptation. A robust evaluation framework, built upon empirical testing and lifecycle management, allows for proactive identification of potential risks before they manifest as real-world harms. This detailed understanding of an AI system’s capabilities – and limitations – is the cornerstone of trustworthy deployment. By prioritizing rigorous evaluation, organizations move beyond reactive compliance with regulatory requirements and toward a proactive posture, fostering public trust and enabling the beneficial integration of artificial intelligence into society. The pursuit of reliable AI isn’t merely a technical challenge; it’s a foundational element of ethical and sustainable innovation.
The pursuit of standardized AI evaluation, as detailed in the paper, highlights a critical need for systemic understanding. It’s not merely about testing individual models, but recognizing how these components interact within agentic systems. This echoes Tim Bern-Lee’s sentiment: “The Web is more a social creation than a technical one.” Just as the Web’s strength lies in its interconnectedness, so too does the reliability of AI hinge on evaluating the boundaries between its components. Failure to acknowledge these connections, to see the whole system, inevitably leads to unforeseen weaknesses and risks, particularly as AI moves beyond simple tasks into complex, autonomous action. The ‘evaluation gap’ isn’t just a technical challenge; it’s a failure to perceive the inherent structure governing behavior.
The Road Ahead
The transition detailed within suggests a fundamental shift: evaluation is no longer a trailing concern, appended after development, but a foundational constraint shaping that very development. This implies a move beyond merely measuring performance on static benchmarks, towards assessing the emergent behaviors of increasingly autonomous systems. The challenge, however, lies in acknowledging that attempting to constrain one aspect of such a system invariably introduces unforeseen consequences elsewhere. The architecture dictates the behavior, and a partial understanding of that architecture guarantees incomplete control.
Closing the ‘evaluation gap’ requires not simply more evaluation, but a qualitatively different approach. Current metrics often fail to capture the nuances of agentic systems operating in complex, real-world scenarios. A focus on robustness, adaptability, and – crucially – the ability to detect and mitigate unintended consequences will be essential. The field must resist the temptation to prioritize easily quantifiable metrics over those that capture genuine reliability and safety.
Ultimately, the true test will not be the creation of ever-more-capable agents, but the development of frameworks capable of anticipating – and accommodating – their inherent unpredictability. The pursuit of standardized evaluation risks becoming a paradoxical endeavor; the very act of defining ‘acceptable’ behavior may inadvertently stifle the emergence of truly innovative, and potentially beneficial, solutions.
Original article: https://arxiv.org/pdf/2602.18029.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Total Football free codes and how to redeem them (March 2026)
- Limbus Company 2026 Roadmap Revealed
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Brawl Stars Sands of Time Brawl Pass brings Sandstalker Lily and Sultan Cordelius sets, along with chromas and more
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- Clash of Clans April 2026 Gold Pass Season introduces a Archer Queen skin
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Gold Rate Forecast
2026-02-23 21:22