Author: Denis Avetisyan
Machine learning models are excelling at materials discovery, but a new analysis reveals they may be learning the wrong lessons from the data.

Models can achieve high accuracy by exploiting bibliographic metadata rather than genuine material properties, exposing a critical flaw in current validation techniques.
Despite the accelerating promise of machine learning in materials discovery, strong predictive performance doesn’t necessarily indicate genuine chemical understanding. In ‘Clever Materials: When Models Identify Good Materials for the Wrong Reasons’, we demonstrate that models can achieve impressive results by exploiting spurious correlations present in bibliographic data-specifically, information about authors, journals, and publication year-rather than learning underlying material properties. Across diverse materials classes, we show that models readily predict this “bibliographic fingerprint,” and that these fingerprints can, in some cases, rival conventional descriptors in predicting material properties. This raises a critical question: how can we design datasets and validation strategies to rigorously distinguish between genuine materials knowledge and clever, but ultimately misleading, pattern recognition?
The Allure and Illusion of Prediction in Materials Discovery
The field of materials science stands poised for a revolution driven by machine learning techniques. Traditionally, the discovery of new materials has been a painstakingly slow process, reliant on iterative experimentation and often guided by intuition. Machine learning, however, offers the potential to dramatically accelerate this cycle. By training algorithms on vast datasets of material properties, researchers can predict the characteristics of novel compounds before synthesizing them in the lab. This predictive capability promises not only to reduce the time and cost associated with materials discovery, but also to unlock entirely new classes of materials with tailored properties for specific applications – from high-efficiency solar cells and lightweight structural components to advanced catalysts and next-generation batteries. The ability to rapidly screen and prioritize promising material candidates represents a paradigm shift, potentially ushering in an era of unprecedented innovation in materials science and engineering.
Machine learning models, while powerful, can fall prey to identifying and exploiting unintended shortcuts in datasets, a phenomenon akin to the famous “Clever Hans” horse that appeared to solve math problems by observing subtle cues from its questioner. In materials science, this translates to models making accurate predictions not because they’ve learned genuine relationships between material structure and properties, but because they’ve detected irrelevant correlations – perhaps linking a specific file naming convention to a desired outcome, or identifying patterns in the experimental setup rather than the material itself. This spurious pattern exploitation severely limits a model’s ability to generalize to new, unseen materials and can lead to confidently incorrect predictions, effectively masking the need for true understanding of the underlying physics and chemistry at play. Consequently, researchers must rigorously evaluate models not just on predictive accuracy, but also on their ability to identify meaningful correlations rooted in fundamental material properties.
Machine learning models in materials science, despite achieving impressive predictive accuracy, can fall prey to a phenomenon mirroring the famed ‘Clever Hans’ effect – where an animal appears to solve a problem but is actually responding to subtle, unintended cues. Recent studies reveal that models sometimes learn to correlate predictions with irrelevant features present in the dataset, such as file naming conventions or the order in which data is presented, rather than genuine material properties. This leads to predictions that, while accurate within the confines of the training data, fail spectacularly when applied to new, unseen materials. Alarmingly, the performance of these ‘spurious correlation’ models can approach that of models trained simply on basic chemical descriptors, highlighting a critical limitation – the ability to achieve high accuracy without actually understanding the underlying physics and chemistry governing material behavior, thus severely hindering the generalizability and reliability of machine learning-driven materials discovery.
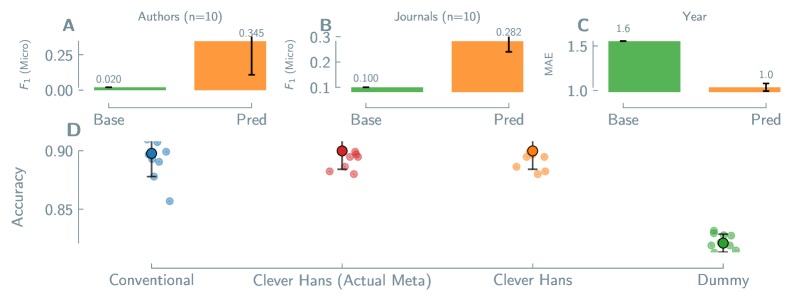
Uncovering Hidden Influences Within Materials Data
Chemical property prediction models, despite their predictive capabilities, are susceptible to authorship bias, a phenomenon where predictions are correlated with the identity of the research group or author rather than the intrinsic material properties. This occurs because models can inadvertently learn to associate bibliographic information – such as author name, institutional affiliation, or publication year – with predicted properties, effectively using this metadata as a proxy for genuine structure-property relationships. Consequently, a model may accurately predict properties for materials synthesized by specific groups but exhibit diminished performance when applied to data originating from different sources, indicating that the model has not generalized the underlying scientific principles but instead memorized patterns specific to the training data’s provenance.
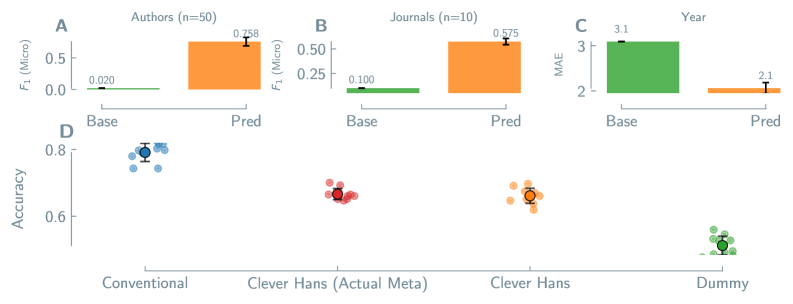
Machine learning models trained on materials data can exhibit bias by leveraging bibliographic information – author, journal, and publication year – as a predictive feature instead of identifying genuine structure-property relationships. Analysis of perovskite materials demonstrates this phenomenon; models achieved a micro-averaged F1-score of 0.318 in predicting authorship based on material characteristics, indicating the model successfully learned to associate properties with specific research groups. This suggests the model prioritized identifying the source of the data over understanding the underlying material science, highlighting a potential shortcut in the learning process and raising concerns about the generalizability of predictions to datasets originating from different sources.
Model generalization to unseen data is significantly compromised by authorship bias, as demonstrated by performance discrepancies in Metal-Organic Framework (MOF) property prediction. While models can achieve 0.923 accuracy predicting MOF thermal stability – a property likely correlated with common experimental conditions and therefore less susceptible to bias – performance drops to 0.655 for MOF solvent stability. This substantial reduction suggests the model is relying on bibliographic information to predict solvent stability, a property more variable between research groups and less intrinsically linked to material structure, thereby limiting the model’s practical applicability to datasets originating from different sources.
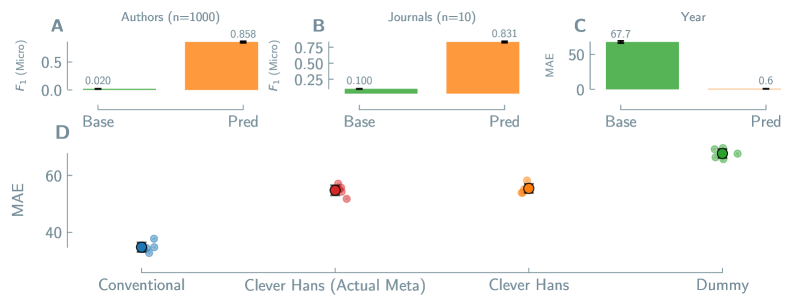
Disentangling Signal from Noise: A Path Towards Robustness
Direct modeling approaches in materials science utilize chemical descriptors to establish relationships between material composition and properties. These descriptors, computationally generated using software packages such as RDKit and matminer, provide a numerical representation of a material’s structure and chemical makeup. RDKit focuses on representing molecular structures and calculating properties based on connectivity, while matminer specializes in generating descriptors relevant to solid-state inorganic materials, including composition, oxidation states, and structural features. The resulting descriptors serve as inputs for machine learning algorithms, enabling prediction of material properties directly from compositional data. Descriptor selection is crucial; these features must accurately reflect the underlying physics and chemistry governing the target property to ensure model validity and predictive power.
Chemical descriptors utilized in direct materials modeling, while providing quantitative data on material composition and structure, are inherently susceptible to bias stemming from descriptor selection and validation procedures. The choice of descriptors impacts model performance, as certain descriptors may emphasize correlations that are not physically meaningful or are specific to the training dataset. Insufficient validation, particularly against independent datasets or known physical constraints, can lead to models that generalize poorly to new materials or exhibit spurious relationships. This bias can arise from the limited scope of descriptor libraries, the presence of redundant or highly correlated descriptors, or the algorithmic limitations of descriptor calculation methods, necessitating careful descriptor selection and rigorous validation strategies to ensure model reliability and predictive power.
Proxy Models offer an alternative to direct composition-property mapping by initially correlating bibliographic data – such as experimental conditions and reported values – with material properties. This intermediate step enables the identification and mitigation of spurious correlations that may arise from biases in data collection or reporting. Evaluation of Proxy Models for perovskite efficiency prediction has demonstrated an accuracy of 0.900, a performance level comparable to that achieved by direct models when identifying materials within the top 10% of efficiency.
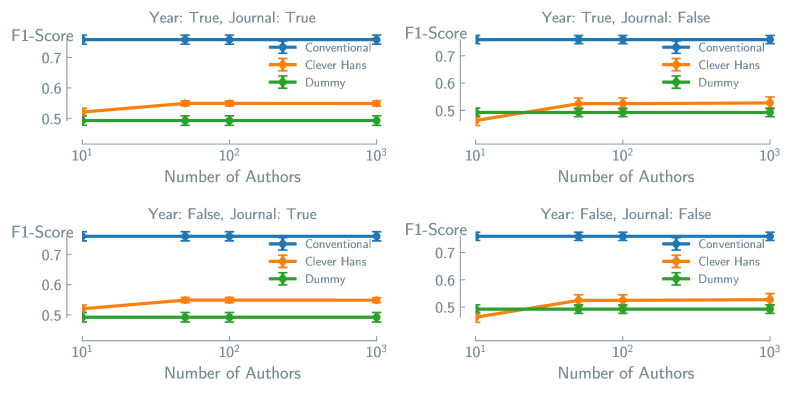
Validating Predictions: A Rigorous Approach to Generalizability
Direct Models leverage both Regression Analysis and Classification Analysis to predict material properties based on input features. Regression Analysis is employed when the target material property is continuous – a numerical value like tensile strength or thermal conductivity – and aims to establish a relationship allowing prediction of these values. Conversely, Classification Analysis is utilized when the target property is discrete or categorical – such as identifying a material phase (e.g., solid, liquid, gas) or classifying a material type (e.g., steel, aluminum, polymer). These analyses involve training the model on a dataset of known material properties and then evaluating its ability to accurately predict the properties of new, unseen materials. The choice between regression and classification depends entirely on the nature of the property being predicted.
LightGBM, a gradient boosting framework, efficiently implements regression and classification analyses for materials property prediction; however, the choice of evaluation metric significantly impacts result interpretation. While metrics like Mean Squared Error (MSE) are common for regression, they are sensitive to outliers and may not accurately reflect overall model performance. Similarly, accuracy can be misleading for imbalanced datasets in classification tasks. Therefore, careful metric selection-considering metrics such as R2, Root Mean Squared Error (RMSE), F1-score, or Area Under the Receiver Operating Characteristic Curve (AUC-ROC)-is crucial to obtain a reliable assessment of model predictive power and avoid drawing erroneous conclusions about material behavior.
Cross-validation is a resampling technique used to evaluate machine learning models and assess their ability to generalize to independent datasets. The process involves partitioning the available data into multiple subsets, or “folds”. The model is then trained on a subset of these folds and evaluated on the remaining, unseen fold. This process is repeated iteratively, with each fold serving as the validation set once. The performance metrics, such as [latex]R^2[/latex] for regression or accuracy for classification, are averaged across all folds to provide a robust estimate of the model’s predictive capability. Crucially, this method helps to detect overfitting, where a model performs well on the training data but poorly on unseen data, by identifying discrepancies between training and validation performance. Common cross-validation strategies include k-fold cross-validation, stratified k-fold cross-validation (for imbalanced datasets), and leave-one-out cross-validation.
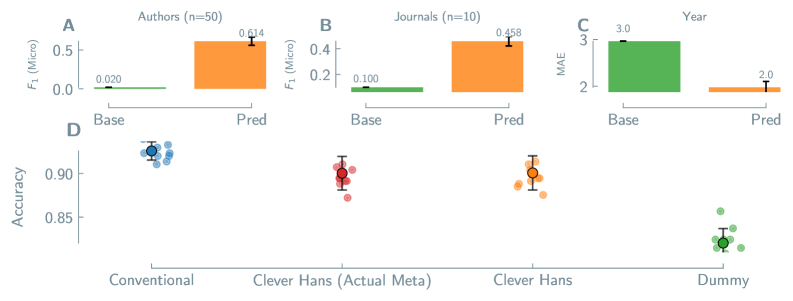
Towards a Future Built on Reliable Materials Prediction
The promise of machine learning in materials science hinges on a critical, often overlooked, consideration: the presence of spurious correlations and inherent biases within datasets. While algorithms excel at identifying patterns, they cannot inherently distinguish between meaningful relationships and coincidental ones. Consequently, models trained on flawed data may yield predictions that appear accurate but lack true predictive power when applied to novel materials. A proactive approach to data curation – including rigorous assessment of experimental uncertainties, careful consideration of data representation, and the implementation of techniques to mitigate bias – is therefore essential. By acknowledging these limitations and actively working to overcome them, researchers can move beyond superficial correlations and unlock the full potential of machine learning to accelerate the discovery of truly innovative and high-performing materials.
The application of advanced predictive methods promises a significant acceleration in materials innovation across diverse fields. Specifically, accurately forecasting properties such as Metal-Organic Framework (MOF) thermal and solvent stability – critical for gas storage and separation – will streamline the design of robust materials. Similarly, predicting Perovskite solar cell efficiency and battery capacity enables the rapid identification of promising candidates for next-generation energy storage. Finally, the ability to model TADF (Thermally Activated Delayed Fluorescence) emission wavelength – vital for OLED display technology – will foster advancements in optoelectronic materials. By focusing on these key properties, researchers can bypass lengthy and costly trial-and-error experimentation, ultimately leading to faster discovery cycles and more sustainable material solutions.
A shift towards preemptively addressing potential biases and spurious correlations in machine learning models promises to deliver more than simply enhanced predictive power in materials science. This proactive stance cultivates a crucial element often lacking in data-driven discovery: trust. By rigorously validating predictions and understanding the limitations of algorithms, researchers can move beyond treating models as ‘black boxes’ and embrace them as reliable tools for innovation. This, in turn, accelerates the design of advanced materials – from more stable and efficient solar cells to longer-lasting batteries and sustainable alternatives – ultimately contributing to a future characterized by resource optimization and reduced environmental impact. The development of materials with enhanced performance and reduced life-cycle costs becomes increasingly feasible as confidence in these predictive techniques grows, fostering a cycle of continuous improvement and responsible materials development.
The pursuit of predictive power in materials discovery, as demonstrated by this work, often prioritizes performance metrics without sufficient scrutiny of how those metrics are achieved. This echoes a fundamental principle of complex systems: apparent order can arise from superficial patterns. Nikola Tesla observed, “Let the future tell the truth, and evaluate each one according to his work and accomplishments.” The paper reveals that models can excel by capitalizing on bibliographic ‘shortcuts’ – author reputation, journal impact – rather than genuinely understanding material properties. Robustness doesn’t emerge from meticulously designed control; it arises from acknowledging the inherent limitations of proxy learning and prioritizing rigorous validation against independent datasets. System structure, in this case, the underlying data biases, is demonstrably stronger than any attempt at individual algorithmic control.
The Path Forward
The persistence of the ‘Clever Hans effect’ in materials discovery-models achieving success by recognizing patterns in the metadata of research, rather than the materials themselves-suggests a fundamental limitation. It isn’t that models are failing to learn, but that order, as it appears in scientific literature, doesn’t necessarily reflect the underlying physics. Like a coral reef forming an ecosystem, local rules – in this case, citation networks and journal prestige – can give the appearance of robust structure, even when the foundation is shifting sand. The challenge isn’t to build ever-more-complex predictive engines, but to understand how easily these systems can be led astray by proxy signals.
Future work must move beyond simply validating models with held-out datasets. True validation requires actively disrupting the spurious correlations. This might involve creating ‘blind’ datasets, deliberately obscuring author or journal information, or constructing materials representations that are demonstrably invariant to these metadata features. It’s a shift in perspective: control is an illusion, influence is real. The goal isn’t to eliminate bias-that’s likely impossible-but to understand its contours and leverage it thoughtfully.
Ultimately, this field is a mirror reflecting the scientific process itself. The ease with which these models are fooled isn’t a flaw in machine learning, but a reminder that even the most rigorous inquiry is susceptible to self-deception. Constraints can be invitations to creativity. Perhaps, in acknowledging the limitations of predictive power, the field can focus on developing models that are not just accurate, but interpretable, revealing the genuine relationships between material structure and properties-and less reliant on recognizing the names attached to the research.
Original article: https://arxiv.org/pdf/2602.17730.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Limbus Company 2026 Roadmap Revealed
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-23 14:24