Author: Denis Avetisyan
A new approach combines human intuition with the analytical power of artificial intelligence to pinpoint the most promising questions driving scientific progress.
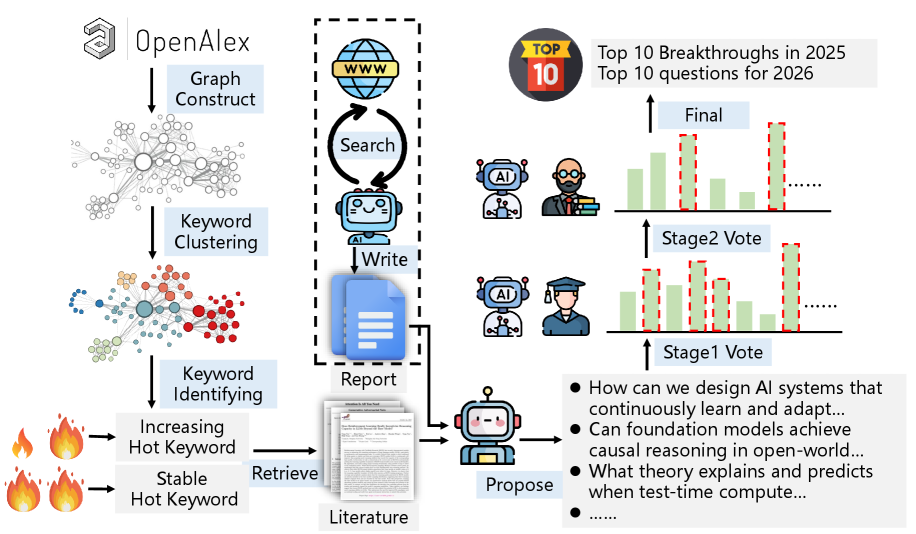
Researchers demonstrate a hybrid human-AI methodology for identifying high-impact research questions and forecasting future scientific breakthroughs through literature analysis and large language models.
While the promise of the “AI Scientist” paradigm suggests accelerating scientific discovery, a critical gap remains in determining whether artificial intelligence can proactively identify genuinely impactful research questions. This work, ‘HybridQuestion: Human-AI Collaboration for Identifying High-Impact Research Questions’, introduces a human-AI hybrid methodology for forecasting major scientific breakthroughs and challenges, demonstrating that AI excels at recognizing established achievements but requires human oversight for evaluating forward-looking inquiries. Our system combines AI-driven literature analysis with human judgment to propose and refine a candidate pool of questions, validated through an experiment predicting breakthroughs and questions for 2025 and 2026. Ultimately, can strategically integrating human expertise with scalable AI capabilities unlock a more robust and insightful approach to shaping the future of scientific inquiry?
The Shifting Sands of Knowledge: Why We Can’t Trust Static Maps
Conventional literature reviews, while valuable, inherently struggle to accurately represent the ever-shifting landscape of scientific inquiry. These assessments often depend on expert judgment, introducing unavoidable subjectivity in determining research significance and identifying genuinely novel directions. This reliance on interpretation means that subtle but crucial changes in focus – a gradual drift from one research area to another, or the burgeoning importance of interdisciplinary approaches – can be easily overlooked or mischaracterized. The inherent limitations of manually synthesizing information from a rapidly expanding body of scientific work create a challenge for accurately tracking momentum and recognizing the emergence of groundbreaking ideas, potentially hindering the efficient allocation of resources and the acceleration of discovery.
To move beyond the limitations of traditional literature reviews, researchers are increasingly turning to data-driven methodologies for assessing scientific momentum. These approaches leverage large datasets of publications, citations, and keywords to objectively quantify research prominence and pinpoint emerging trends across diverse disciplines. By employing network analysis, topic modeling, and other computational techniques, it becomes possible to map the evolving landscape of scientific inquiry, identifying rapidly growing fields and influential research areas. This quantitative perspective allows for a more nuanced understanding of knowledge diffusion and innovation, offering insights that subjective reviews often miss. Ultimately, this shift towards data-driven analysis promises a more accurate and dynamic representation of the scientific process, facilitating informed decision-making for funding agencies, researchers, and policymakers alike.
![Projected trends indicate that in 2025, key areas of focus within Artificial Intelligence will include [latex] ext{Keyword Hotness}[/latex].](https://arxiv.org/html/2602.03849v1/x2.png)
Decoding Prominence: The Language of Keywords
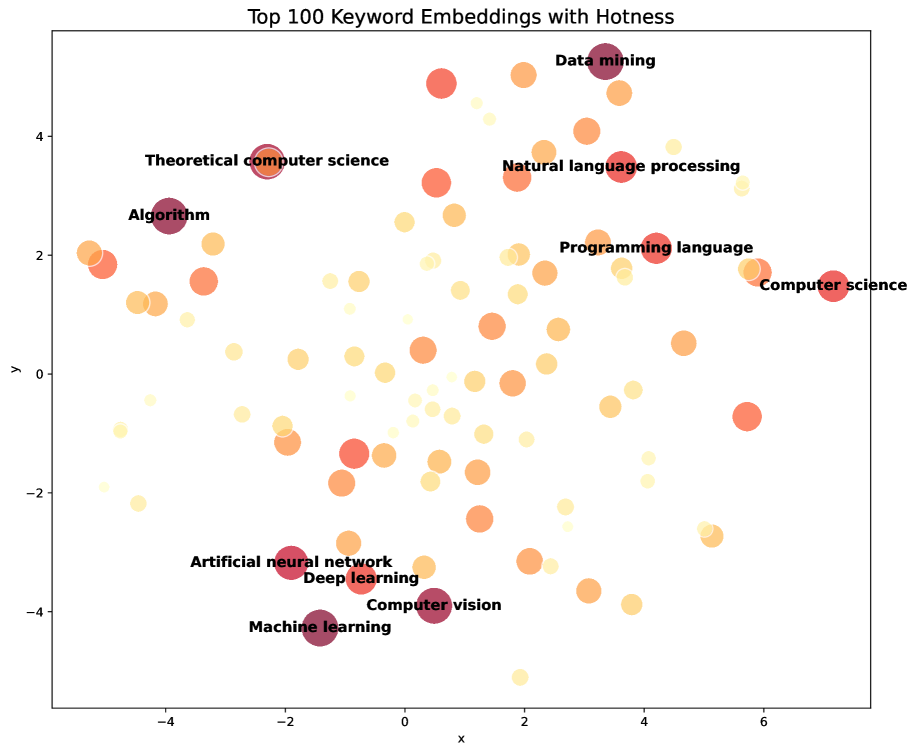
The Hotness Score is a metric designed to quantify research prominence by analyzing keyword co-occurrence within a corpus of publications sourced from OpenAlex. This is achieved through the creation of ‘Keyword Embeddings’, which represent keywords as vectors in a multi-dimensional space, reflecting their semantic relationships. The density of these vectors-how closely keywords cluster-indicates the concentration of research activity around specific topics. By calculating the embeddings based on publication data, the Hotness Score provides an objective measure of semantic density, allowing for the identification of trending research areas and topics gaining increased attention within the scientific literature.
The Gaussian Kernel is applied to initial keyword frequency counts to assign weights, prioritizing keywords with higher occurrences while diminishing the influence of extremely common terms. This weighting process addresses the limitations of raw frequency, which can overemphasize ubiquitous keywords lacking specific research context. Subsequently, the Node2vec algorithm is employed to generate vector embeddings from these weighted keyword frequencies. Node2vec utilizes random walks on a keyword co-occurrence graph to capture not only direct relationships between keywords but also higher-order semantic connections, resulting in a nuanced representation of keyword meaning and context within the scientific literature. The resulting embeddings facilitate a more accurate assessment of semantic density and the identification of emerging research trends.
The Hotness Score provides an annual, objective quantification of keyword prominence based on analysis of publication data. This allows for the identification of research areas experiencing rapid growth, as higher scores correlate with increased research activity and attention within a given year. The metric tracks changes in keyword frequency and semantic density over time, distinguishing between sustained research topics and those demonstrating emergent trends. Consequently, the Hotness Score facilitates proactive monitoring of scientific landscapes and supports the detection of potentially groundbreaking research fields before they become widely established.
Uncovering the Structure of Insight: A Hybrid Mind at Work
Hotness-Priority Greedy Clustering was implemented to identify relationships between keywords by iteratively grouping those with the highest ‘Hotness Scores’. This approach prioritizes keywords demonstrating significant recent attention, measured by publication rates and citation velocity. The algorithm functions by initially designating each keyword as a separate cluster, then sequentially merging the two closest clusters-determined by a cosine similarity metric calculated from their respective Hotness Score vectors-until a pre-defined number of clusters is reached. This method effectively identifies thematic connections, both within specific research areas and across disciplines, by aggregating keywords experiencing concurrent increases in scholarly interest. The resulting clusters provide a data-driven foundation for understanding emerging research trends and identifying potential areas for interdisciplinary collaboration.
The cluster analysis process incorporated a Human-AI Hybrid Intelligence framework designed to combine the computational power of Large Language Models (LLMs) with human expert validation. LLMs were initially used to automatically group keywords generated from scientific literature. Subsequently, subject matter experts reviewed and refined these groupings, providing critical assessment and interpretation. This iterative process ensured that the resulting thematic clusters were not only statistically relevant, but also conceptually sound and aligned with established knowledge within the relevant disciplines. The framework facilitated a collaborative approach, leveraging the strengths of both AI-driven analysis and human contextual understanding.
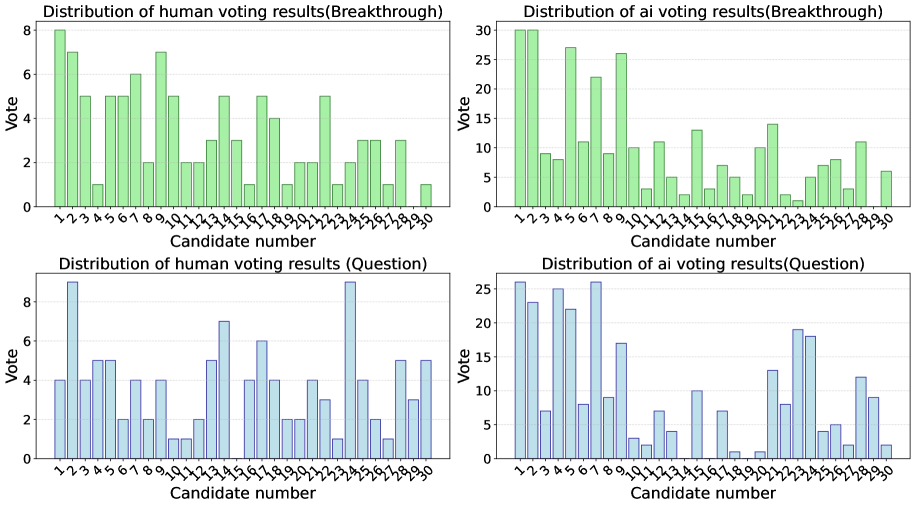
The Human-AI Hybrid Intelligence framework employed a multi-faceted voting system to aggregate preferences from both human experts and the Language Model. ‘Approval Voting’ allowed participants to endorse multiple relevant keywords within each cluster, while ‘Limited Voting’ restricted selections to a fixed number, promoting focused prioritization. To quantify the concordance between human and AI assessments, [latex]Jensen-Shannon (JS) Distance[/latex] was utilized; this metric measures the similarity between probability distributions, with lower values indicating greater alignment. The framework’s ability to refine thematic groupings was assessed by tracking changes in JS Distance between human and AI voting distributions across iterative stages of analysis.
Analysis of voting distributions between human experts and the AI system, quantified using Jensen-Shannon (JS) Distance, revealed increasing alignment across stages of the thematic cluster identification process. Initial assessment in Stage 1, focused on established breakthroughs, yielded a JS Distance of 0.394, indicating a moderate divergence between human and AI preferences. However, subsequent evaluation in Stage 2 demonstrated a significant reduction in divergence, with the JS Distance decreasing to 0.209. This decrease signifies improved concordance between human expert assessments and the AI’s prioritization, suggesting that the system progressively refined its ability to identify and categorize relevant thematic connections with increasing accuracy and alignment to expert knowledge.
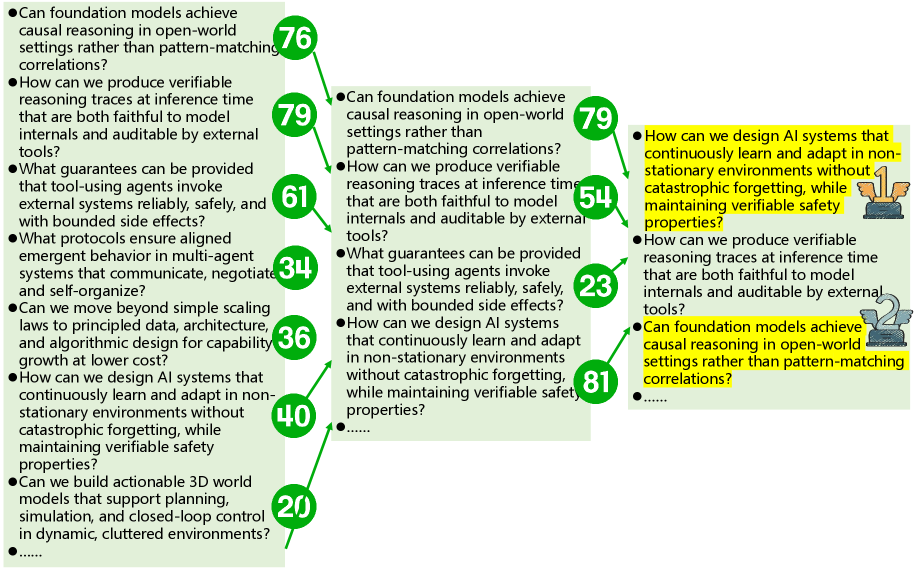
To address potential biases and enhance the reliability of generated research proposals, a combined ‘Ensemble Voting’ and ‘Deep Research’ methodology was implemented. ‘Ensemble Voting’ aggregated the outputs of multiple voting schemes – including Approval Voting and Limited Voting – to create a more balanced and representative assessment of keyword cluster relevance. This aggregated vote was then cross-referenced with findings from ‘Deep Research’, which involved a thorough investigation of existing literature and data sources to validate the proposed thematic connections and identify any overlooked contextual factors. The combination of these techniques aimed to minimize the impact of individual biases within both the AI algorithms and the human expert evaluations, ultimately leading to more robust and well-supported research proposals.
Predicting the Unpredictable: Where Knowledge Will Lead Us
The research team’s data-driven methodology successfully pinpointed pivotal scientific breakthroughs across diverse disciplines. This wasn’t simply a cataloging exercise; the analytical process rigorously validated the prominence of these advancements, confirming their substantial impact through quantifiable metrics derived from large-scale research data. By moving beyond subjective assessments and relying on objective indicators of scientific influence – such as citation rates, publication frequency in high-impact journals, and patterns of knowledge diffusion – the study provides a robust and reproducible framework for identifying truly transformative scientific achievements. This approach not only acknowledges past successes but also establishes a valuable benchmark for evaluating emerging research and predicting future areas of significant progress, offering a novel perspective on the evolution of scientific knowledge.
This analytical method doesn’t merely catalog existing scientific achievements; it dynamically maps the research landscape, revealing not only well-established fields but also those experiencing accelerated development. By tracking the co-occurrence of concepts over time, the system identifies areas where research is intensifying, pinpointing emergent themes and potentially disruptive innovations. This capability offers a valuable contrast to traditional citation analysis, which often lags behind actual shifts in research focus. Consequently, scientists and funding bodies gain insight into where resources are most effectively allocated to foster progress, and can proactively anticipate the direction of future discoveries, as opposed to simply reacting to past trends.
The research identified pivotal ‘Grand Scientific Questions’ likely to shape future investigations across diverse disciplines. While an AI-driven approach demonstrated strong concordance with human expertise in recognizing established breakthroughs, the identification of these future research frontiers proved more nuanced. A Jensen-Shannon (JS) Distance of 0.352, calculated in Stage 2 of the analysis, indicates a notable, though not insurmountable, divergence between AI predictions and human judgment in this area. This suggests that, while valuable as a tool for exploration, human insight remains critically important for discerning the most promising avenues for scientific inquiry and anticipating the questions that will define the next era of discovery.
The pursuit of identifying high-impact research questions, as detailed within this study, echoes a fundamental truth about complex systems. It isn’t about building a predictive engine, but cultivating one. The methodology presented – a human-AI hybrid – recognizes that Large Language Models can adeptly analyze the past, charting previous breakthroughs. However, forecasting genuinely grand challenges necessitates the nuanced judgment only human intellect can provide. As Linus Torvalds observed, “Talk is cheap. Show me the code.” This research doesn’t simply discuss scientific forecasting; it demonstrates a functional, iterative approach-a ‘code’ for identifying the questions that will shape the future. The system isn’t silent; it’s actively plotting a course through the landscape of knowledge.
What’s Next?
The demonstrated symbiosis – a human steering an AI’s pattern recognition – isn’t a solution, but a relocation of the problem. The system excels at identifying what was groundbreaking, a task inherently reliant on historical data. The true bottleneck remains forecasting the genuinely novel, where signal is buried within an exponentially expanding noise floor. To mistake correlation for prescience is a comfortable, but ultimately sterile, endeavor.
Future iterations will inevitably focus on refining the AI’s predictive capacity. However, a guarantee of accurate forecasting is merely a contract with probability, and chasing such a phantom risks obscuring more fundamental limitations. The architecture itself – this insistence on ‘intelligent’ agents – presumes a linearity that nature rarely exhibits. Chaos isn’t failure – it’s nature’s syntax.
Stability is merely an illusion that caches well. The next phase isn’t about building a better forecasting engine, but accepting that the most impactful questions will likely emerge from the periphery, from the unexpected collisions of disparate fields. The system, therefore, should be designed not to predict, but to amplify weak signals, even – perhaps especially – those that initially appear illogical or contradictory.
Original article: https://arxiv.org/pdf/2602.03849.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Limbus Company 2026 Roadmap Revealed
- Wuthering Waves Hiyuki Build Guide: Why should you pull, pre-farm, best build, and more
- XO, Kitty season 3 soundtrack: The songs you may recognise from the Netflix show
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Total Football free codes and how to redeem them (March 2026)
- The Division Resurgence Specializations Guide: Best Specialization for Beginners
- Gold Rate Forecast
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
2026-02-05 07:00