Author: Denis Avetisyan
A new review explores how internal motivation, beyond simple rewards, is key to building truly adaptable and open-ended artificial intelligence.
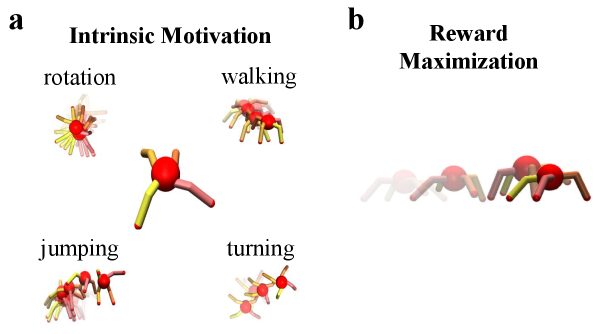
Maximizing action-state path entropy offers a compelling framework for embodied intelligence, moving beyond limitations of extrinsic reward maximization and informing generative models.
While conventional theories often explain behavior as maximizing extrinsic rewards, phenomena like curiosity and spontaneous motor activity suggest a more fundamental drive exists. This paper, ‘How Intrinsic Motivation Underlies Embodied Open-Ended Behavior’, reviews recent formalizations of intrinsic motivation, proposing that maximizing the entropy of action-state paths serves as a core principle organizing behavior, independent of external goals. By breaking infinite regress and offering a unified framework encompassing both internal drives and extrinsic rewards, these theories promise a new generation of generative models for embodied intelligence. Could understanding this intrinsic drive unlock truly open-ended and adaptive behavior in artificial systems?
Unveiling the Hidden Drivers of Behavior
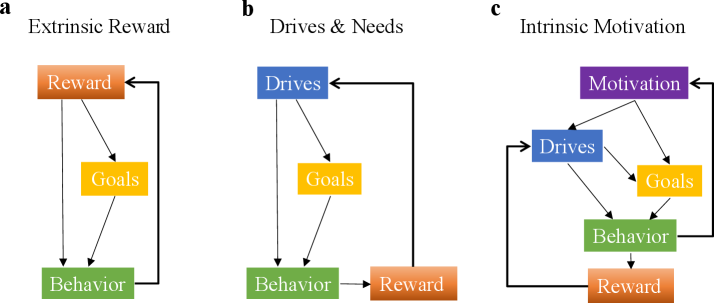
Conventional behavioral models often posit that actions are undertaken to maximize external rewards – a predictable benefit received after a behavior. However, these frameworks struggle to account for instances of exploratory behavior, where individuals – and even animals – actively seek out new information or experiences despite a lack of immediate, obvious gain. This disconnect suggests a fundamental limitation in relying solely on extrinsic motivation as a driving force behind all actions; it fails to explain why organisms persistently investigate, play, or experiment even when no reward is anticipated. The prevalence of curiosity, novelty-seeking, and active learning across species indicates that a separate motivational system, one driven by the properties of the environment itself, must be at play, challenging the traditional emphasis on purely reward-based learning.
The limitations of solely focusing on external rewards to explain behavior have prompted a necessary re-evaluation of motivational forces. Traditional models struggle to account for actions undertaken without obvious benefit, highlighting the importance of intrinsic motivation – the inherent drive to engage with and explore an environment for its own sake. This isn’t simply about seeking pleasure, but rather a fundamental property of systems – be they biological or artificial – that encourages interaction and learning even in the absence of immediate, tangible rewards. Understanding this internally generated impetus is crucial because it suggests behavior isn’t always driven by outcomes, but can emerge from the process of interaction itself, potentially explaining curiosity, creativity, and the persistent exploration seen in both humans and other animals.
The development of truly adaptive and robust agents, be they artificial intelligences or robotic systems, hinges on moving beyond reliance on externally defined rewards. Current approaches often falter when faced with novel situations lacking pre-programmed incentives; therefore, a deeper understanding of intrinsic motivation – the drive to explore and learn for its own sake – is paramount. Researchers are actively investigating the neural mechanisms underlying this drive, identifying key roles for prediction error and novelty signals in driving exploratory behavior. Computationally, this translates to building agents that actively seek out information that reduces uncertainty or challenges existing models of the world. By mirroring these principles, future agents can not only respond to defined goals but also proactively learn and adapt in complex, unpredictable environments, exhibiting a level of resilience and ingenuity currently beyond their reach.
Deconstructing the Principles of Intrinsic Drive
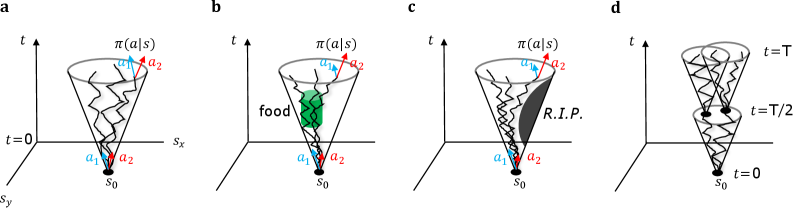
Formalizations of intrinsic motivation frequently center on quantifying novelty and exploration. State\ Transition\ Entropy assesses the unpredictability of an agent’s state transitions; a higher entropy indicates greater novelty in the experienced states. Complementarily, Action-State\ Path\ Entropy measures the diversity of paths an agent takes through its state space, quantifying the breadth of exploration given available actions. Both metrics provide computational frameworks for rewarding agents for visiting previously unseen states or engaging in diverse behavioral patterns, effectively driving exploration without external reward signals. These entropy-based approaches offer quantifiable measures that can be directly incorporated into reinforcement learning algorithms to encourage curiosity and discovery.
The Free Energy Principle posits that self-organizing systems, including agents, operate to minimize F = D_{KL}(Q(s|o) || P(o|s)), where F represents free energy, D_{KL} is the Kullback-Leibler divergence, Q(s|o) is the approximate posterior belief about internal states s given observations o, and P(o|s) is the agent’s generative model predicting observations given internal states. This minimization is achieved by both minimizing perceptual error – making predictions about sensory input more accurate – and actively sampling the environment to test and refine those predictions. Consequently, exploratory behavior isn’t random, but rather a process of ‘active inference’ where agents seek out information that reduces uncertainty in their internal models and improves predictive accuracy, thereby minimizing surprise and maintaining homeostasis.
The Empowerment principle quantifies an agent’s potential for influence over its environment by maximizing the mutual information between possible future states and the actions that could lead to those states. Formally, empowerment is calculated as \sum_{s'} I(a; s') , where I represents mutual information, a denotes the agent’s actions, and s' represents potential future states. A higher empowerment value indicates the agent can predictably produce a wider range of distinct outcomes through its actions, effectively measuring its agency and control within the environment. This contrasts with simply predicting outcomes; empowerment focuses on the ability to cause specific outcomes, regardless of their probability.
Mapping the Neural Landscape of Intrinsic Motivation
Dopaminergic neurons, traditionally understood for their role in signaling discrepancies between predicted and actual rewards – known as Reward Prediction Error – are increasingly recognized for contributions to intrinsic motivation. While Reward Prediction Error signals are critical for reinforcement learning, a subset of dopaminergic neurons in the ventral tegmental area demonstrate activity correlated not with external rewards, but with novelty and uncertainty. This activity suggests these neurons represent a prediction error specifically related to the agent’s internal model of the environment, driving exploration in the absence of immediate external reinforcement. The magnitude of dopaminergic response to novel stimuli, and to conditions where outcomes are unpredictable, indicates a neural mechanism supporting curiosity-driven learning and the active seeking of information.
The orbitofrontal cortex (OFC) and the zona incerta (ZI) are interconnected brain structures demonstrably involved in the neural basis of intrinsic motivation. The OFC integrates information about expected and actual rewards, contributing to reward valuation and prediction. Lesions to the OFC impair stimulus-reward learning and exploratory behavior. The ZI, reciprocally connected with the OFC, appears to encode uncertainty and prediction errors, signaling discrepancies between expected and experienced outcomes. Activity within the ZI correlates with both exploration and the anticipation of novel stimuli, suggesting its role in driving behavior when external rewards are absent or unpredictable. These findings indicate a circuit where the OFC assigns value and the ZI motivates action in the pursuit of potentially rewarding, yet uncertain, experiences.
Bounded cognition, stemming from the limitations of neural processing capacity and available time, constrains an agent’s ability to comprehensively evaluate all possible exploratory actions. Consequently, agents must prioritize exploration based on limited resources – including energy expenditure, computational cycles, and time. This prioritization directly shapes the agent’s behavioral policy, influencing which actions are selected for execution. Policies are therefore not based on exhaustive evaluation, but rather on heuristics and approximations that allow for efficient decision-making within cognitive and resource constraints. These constraints necessitate strategies such as selective attention, simplification of complex problems, and reliance on previously learned information to guide exploratory behavior.
Envisioning Adaptive Intelligence Through Intrinsic Drive
The capacity for lifelong learning and adaptation in dynamic environments hinges on the interplay between intrinsic motivation and embodiment. Research indicates that agents driven by internally generated curiosity – a desire to explore and master skills for their own sake – exhibit significantly enhanced resilience and performance. This isn’t simply about abstract problem-solving; embodiment-the agent’s physical presence and interaction with the world-is crucial. By grounding intelligence in a physical body, agents develop a richer understanding of cause and effect, allowing them to learn more efficiently and generalize knowledge to novel situations. This combination fosters a continuous learning cycle, where exploration driven by intrinsic rewards leads to improved skills, which, in turn, enable more effective interaction with, and learning from, the environment. The result is an intelligent system capable of not just reacting to challenges, but proactively seeking opportunities for growth and refinement throughout its operational lifespan.
The capacity to effectively balance exploration and exploitation represents a cornerstone of intelligent behavior, as agents operating in dynamic environments must continually decide whether to leverage existing knowledge or seek out novel information. A predominantly exploitative strategy, while initially efficient, risks becoming trapped in local optima – suboptimal solutions that prevent the discovery of superior alternatives. Conversely, relentless exploration without capitalizing on learned information yields inefficient performance and hinders adaptation. Research indicates that optimal performance arises from a nuanced equilibrium, where the rate of exploration is dynamically adjusted based on environmental volatility and the agent’s confidence in its current understanding. Algorithms that successfully navigate this trade-off, often employing techniques like ε-greedy approaches or upper confidence bound methods, demonstrate significantly enhanced robustness and the ability to consistently achieve higher rewards over extended periods, ultimately leading to more adaptive and resilient intelligent systems.
The potential for an agent to encounter Terminal States – conditions resulting in functional compromise or outright failure – underscores a crucial role for intrinsic motivation in sustaining performance. Unlike extrinsic rewards which focus on achieving specific goals, intrinsic motivation drives continued interaction with the environment even when external objectives are absent or unattainable. This persistent engagement is not merely exploratory; it allows the agent to continually refine its internal models, anticipate potential failure modes, and develop compensatory strategies. Consequently, an intrinsically motivated agent is less likely to be caught in a catastrophic failure state, exhibiting greater resilience and adaptability in dynamic and unpredictable circumstances. The ability to maintain functionality, even in the face of adversity, suggests that intrinsic motivation is not simply beneficial, but potentially vital for the long-term survival and robust operation of autonomous systems.
The pursuit of embodied intelligence, as detailed in this work, echoes a fundamental principle of natural systems: exploration driven by internal dynamics. This aligns with Isaac Newton’s observation, “We build too many walls and not enough bridges.” Just as Newton alluded to the importance of connection and overcoming limitations, this research proposes that intrinsic motivation – specifically, maximizing action-state path entropy – allows agents to navigate complex environments and generate novel behaviors, effectively ‘building bridges’ between states without being solely constrained by pre-defined ‘walls’ of extrinsic reward. This approach moves beyond simple reward maximization, enabling a more flexible and adaptable form of intelligence, mirroring the inherent exploratory drive found in biological systems.
Where Do We Go From Here?
The assertion that action-state path entropy serves as a foundational principle for embodied intelligence, while compelling, naturally invites scrutiny. The current landscape of generative models, largely predicated on extrinsic reward maximization, demonstrates a certain brittleness – a tendency to exploit simplified environments rather than genuinely explore them. Future work must address the computational challenges of scaling entropy maximization to complex, high-dimensional state spaces, and more importantly, validating its predictive power beyond simulated environments. A critical next step involves disentangling the interplay between dopamine-mediated reward prediction error and the neural substrates underpinning intrinsic motivation – is dopamine simply a signal for novelty, or does it fundamentally shape the agent’s exploration strategy?
A particularly intriguing, though currently underexplored, avenue lies in examining the limits of entropy maximization. Does unbounded exploration always yield beneficial behavior? The principles of bounded cognition suggest that cognitive resources are finite, implying a trade-off between exploration and exploitation. How does an agent balance the drive for novelty with the need for efficient action selection? Formulating a coherent theory that incorporates both entropy maximization and resource constraints will be essential for building truly robust and adaptable embodied agents.
Ultimately, the pursuit of intrinsic motivation is not merely a quest to replicate intelligence, but to understand the very nature of agency. The patterns revealed by maximizing action-state path entropy may offer a glimpse into the fundamental principles governing self-organization and emergent behavior – a humbling prospect, given the inherent limitations of any model attempting to capture the complexity of a living system.
Original article: https://arxiv.org/pdf/2601.10276.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2026-01-18 02:52