Author: Denis Avetisyan
A new vision outlines how artificial intelligence can transform every aspect of experimental high-energy physics, accelerating the pace of discovery.
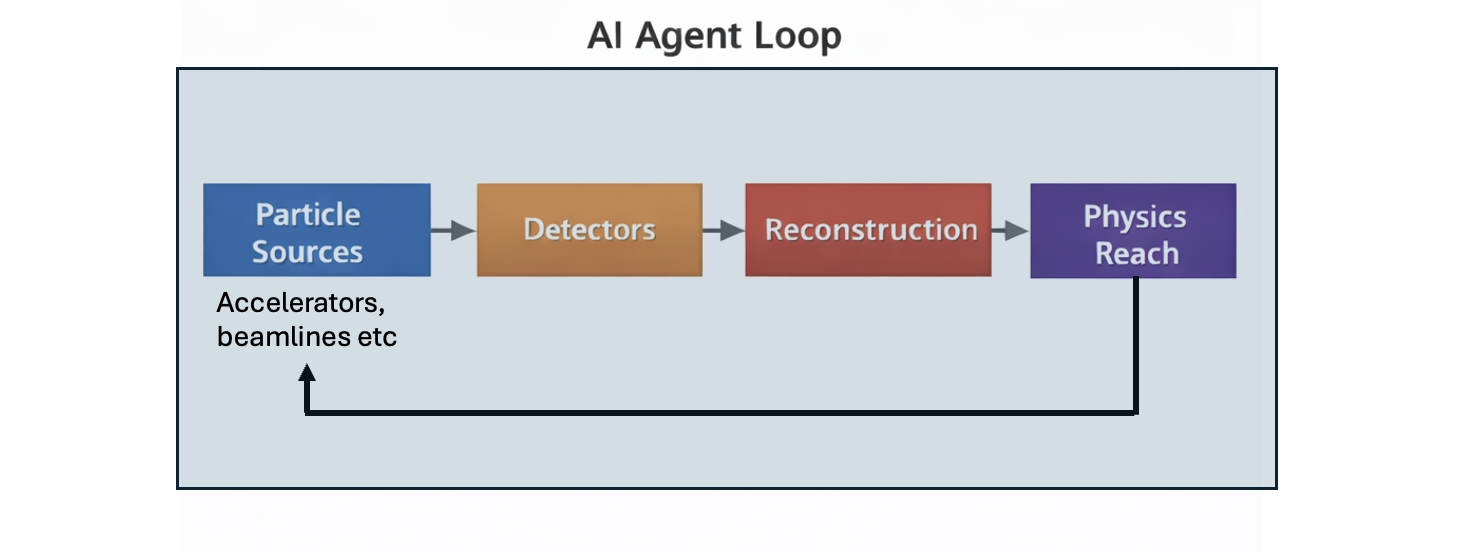
This whitepaper details a community-driven plan to build a fully AI-integrated research ecosystem for data acquisition, analysis, and facility operation in particle physics.
Despite the increasing volume and complexity of data generated by modern experiments, fundamental questions in particle physics remain challenging to address with traditional analysis techniques. This whitepaper, ‘Building an AI-native Research Ecosystem for Experimental Particle Physics: A Community Vision’, outlines a strategic roadmap for integrating Artificial Intelligence (AI) across all facets of the field-from data acquisition and reconstruction to theoretical modeling and experimental design-to accelerate scientific discovery. The vision centers on establishing a cohesive, nationally-coordinated cyberinfrastructure capable of leveraging foundation models and advanced machine learning algorithms. Will this proactive, AI-driven approach unlock the full potential of current and future facilities like the HL-LHC, DUNE, and beyond, ultimately reshaping our understanding of the universe?
The Inevitable Deluge: Experimentation Beyond Capacity
Contemporary scientific experimentation is characterized by an exponential increase in data generation, far surpassing the capacity of conventional analytical techniques. Advances in areas like genomics, astronomy, and particle physics now routinely produce datasets of petabyte scale – and beyond – overwhelming established methods designed for smaller, more manageable quantities of information. This isn’t simply a matter of ‘more data’; the velocity and variety of information also present significant hurdles. Researchers are increasingly challenged not only by storage limitations but also by the need for novel algorithms and computational infrastructure capable of efficiently processing, filtering, and interpreting these massive, complex datasets to extract meaningful scientific discoveries. The sheer volume necessitates a paradigm shift in how experiments are designed, data is collected, and knowledge is ultimately derived.
The sheer volume of data now routinely produced in scientific experimentation necessitates a paradigm shift in analytical techniques. Traditional methods, designed for smaller datasets, are increasingly overwhelmed, unable to discern crucial patterns or statistically significant findings hidden within the noise. Researchers are actively developing and implementing novel approaches – including advanced machine learning algorithms, automated data curation pipelines, and visualization tools optimized for high-dimensional data – to not only process this ‘data deluge’ but also to reinterpret the very nature of evidence. These innovations move beyond simply quantifying observations; they aim to establish predictive models, uncover previously unknown correlations, and ultimately accelerate the pace of discovery by transforming raw data into actionable knowledge. The focus is shifting from manual analysis to systems capable of autonomously identifying and highlighting the most salient features within complex datasets, allowing scientists to concentrate on interpretation and hypothesis generation.
The accelerating pace of experimentation across diverse scientific fields has created a critical mismatch between data generation and analytical capacity. Traditional statistical methods and computational tools, designed for smaller datasets, now falter when confronted with the sheer volume, velocity, and variety characteristic of modern research. This struggle isn’t simply a matter of needing faster computers; it represents a fundamental bottleneck in the scientific process, delaying discoveries and potentially obscuring valuable insights hidden within complex data streams. Consequently, researchers are actively pursuing innovative solutions – including advanced machine learning algorithms, distributed computing frameworks, and automated data curation techniques – to effectively manage, interpret, and extract meaningful knowledge from this ever-growing deluge of information, ultimately striving to regain momentum in the pursuit of scientific advancement.
The sheer volume of data now routinely generated in scientific experimentation presents more than just storage and organization challenges; it actively constrains the rate of discovery. Researchers increasingly spend significant portions of their time and resources simply managing data, rather than analyzing it for novel insights. This bottleneck isn’t about slower computers or full hard drives, but a fundamental impedance in the scientific process itself – the inability to efficiently transform raw data into actionable knowledge. Consequently, promising hypotheses may remain untested, subtle patterns overlooked, and the potential for groundbreaking discoveries unrealized, not due to a lack of experimental ingenuity, but due to limitations in data handling capabilities. Addressing this issue requires a shift in focus, prioritizing not just data collection, but also streamlined, automated, and intelligent methods for data processing, interpretation, and knowledge extraction.
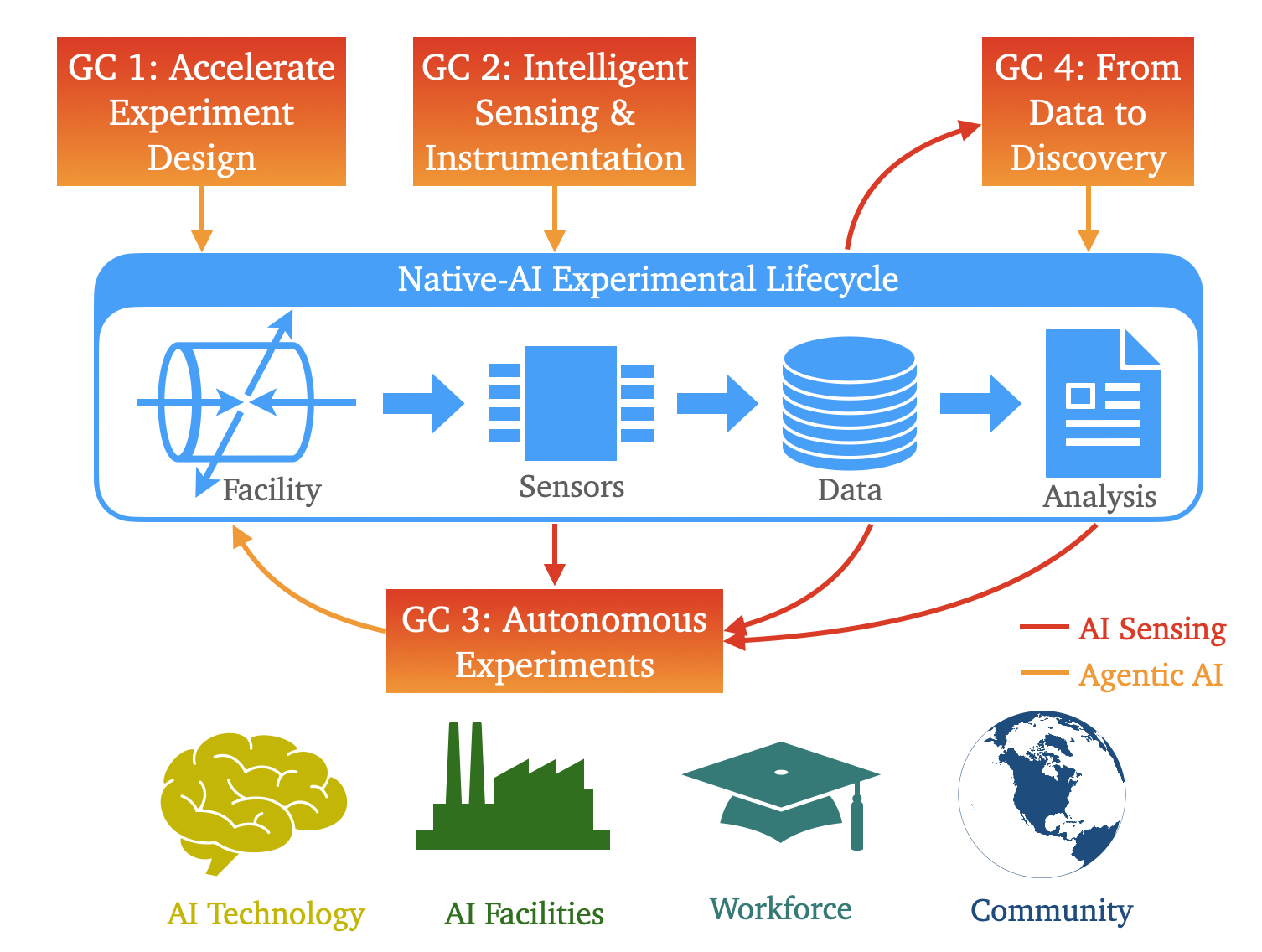
Acceleration Through Abstraction: The Rise of AI-Powered Workflows
Traditional data analysis in scientific fields often relies on manually defined algorithms and statistical methods, which struggle with the scale and complexity of modern datasets and can be computationally expensive. AI-driven simulation and reconstruction techniques address these limitations by employing machine learning models to learn patterns and relationships directly from data, enabling the creation of data representations from incomplete or noisy inputs. These techniques can accelerate analysis by predicting outcomes, generating synthetic data for model training, and identifying subtle features that might be missed by conventional methods. Furthermore, they facilitate the exploration of complex systems through the rapid generation of multiple hypotheses and the automated evaluation of their validity, thereby increasing the efficiency of scientific discovery.
Foundation Models, pre-trained on extensive datasets, enable adaptable reconstruction and physics modeling by transferring learned representations to new, specific scientific challenges. Unlike models trained from scratch for each task, these pre-trained models require significantly less data for fine-tuning, accelerating the development of simulations and analyses. This transfer learning capability allows for the modeling of complex phenomena even with limited experimental data, improving the accuracy of reconstructions and physics-based predictions. Furthermore, the inherent flexibility of Foundation Models facilitates the exploration of diverse parameter spaces and the identification of subtle patterns within complex datasets, ultimately yielding deeper insights than traditional methods allow.
Differentiable simulation establishes a bidirectional link between simulation environments and machine learning frameworks. Traditionally, simulations operated as “black boxes” with discrete inputs and outputs, hindering gradient-based optimization. By rendering simulations “differentiable,” meaning that gradients can be computed through the simulation itself, parameters within the simulation can be directly optimized using techniques like backpropagation. This integration allows for inverse problems to be solved – determining input parameters that yield a desired simulation outcome – with significantly improved efficiency. Furthermore, differentiable simulation facilitates tasks such as uncertainty quantification, sensitivity analysis, and real-world data fitting by enabling the optimization of simulation parameters to minimize the discrepancy between simulated and observed data. The technique effectively transforms simulations into learnable components within a larger AI system, unlocking new capabilities for scientific modeling and analysis.
The development and deployment of AI models for scientific workflows are heavily reliant on the availability of substantial, high-quality datasets for both training and validation. Traditional data acquisition methods often prove insufficient to meet the demands of these data-intensive models, necessitating techniques for rapid data generation. Synthetic data generation, leveraging physics-based models or generative AI, allows for the creation of large, labeled datasets that can augment or replace experimentally obtained data. This is particularly critical when real-world data is scarce, expensive to obtain, or contains inherent biases. Rigorous validation of these AI models requires independent datasets, also frequently generated synthetically, to assess performance and ensure generalization beyond the training data, thereby establishing the accuracy and reliability of the resulting scientific insights.
![This diagram illustrates an automatically optimized data analysis process, as detailed in reference [11].](https://arxiv.org/html/2602.17582v1/images/Analysis_Diagram_summary.png)
The Autonomous Facility: A Self-Correcting System
AI-Native Experimental Design leverages artificial intelligence algorithms to systematically optimize experimental parameters and detector layouts prior to data acquisition. This process moves beyond traditional methods of manual parameter tuning and grid searches by employing techniques like Bayesian optimization and reinforcement learning to identify configurations that maximize key scientific metrics. Optimization considers factors including signal strength, resolution, and minimization of systematic errors. By computationally exploring a vast parameter space, AI-Native Design identifies optimal settings that enhance data quality and increase the probability of detecting significant results, ultimately improving the scientific return on investment for large-scale facilities.
Autonomous experiments leverage Agentic Systems – AI agents designed to perform actions and make decisions – to automate facility operations, calibration procedures, and data quality control processes. These systems utilize Digital Twins, virtual representations of physical experimental setups, to simulate and optimize experiment parameters before and during execution. Automation extends to routine tasks such as sample handling, data acquisition setup, and initial data validation, reducing human intervention and potential errors. This integrated approach allows for continuous, self-correcting experimentation, increasing throughput and reliability while minimizing the need for constant manual oversight.
Intelligent sensing and instrumentation systems employ advanced algorithms and hardware to optimize data acquisition processes, significantly reducing data volume while preserving crucial information. These systems utilize techniques such as data filtering, dimensionality reduction, and on-site data processing to identify and retain only the relevant signals. Specifically, methods like compressive sensing and feature extraction are implemented to minimize redundancy and noise. This results in decreased storage requirements, reduced data transfer bandwidth, and faster data analysis. Furthermore, the implementation of smart sensors capable of pre-processing data at the source further contributes to efficient data handling and minimizes the need for extensive post-processing.
The implementation of automated experimental facilities is intended to shift the focus of scientific personnel from operational tasks – such as data collection, instrument calibration, and routine analysis – to higher-level cognitive activities including hypothesis formulation, experimental design, and results interpretation. This reallocation of effort directly supports the US national objective of bolstering the STEM workforce by training 100,000 scientists and engineers in artificial intelligence, providing them with practical experience in leveraging AI-driven tools for scientific discovery and innovation.
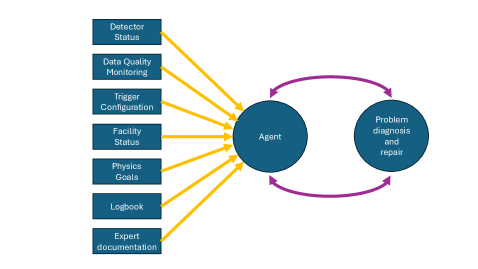
The American Science Cloud: An Inevitable Ecosystem
The American Science Cloud represents a fundamental shift in how scientific research is conducted, providing a robust and scalable infrastructure explicitly designed to harness the power of artificial intelligence. This cloud-based platform moves beyond traditional, often limited, computing resources by offering on-demand access to vast datasets, advanced algorithms, and high-performance computing capabilities. It isn’t simply about increasing computational power, but about creating an interconnected ecosystem where data flows freely and AI models can be trained, tested, and deployed with unprecedented efficiency. By consolidating resources and streamlining workflows, the American Science Cloud aims to accelerate discovery across numerous scientific disciplines, enabling researchers to tackle complex problems that were previously intractable and fostering a new era of data-driven innovation.
The American Science Cloud envisions a transformative approach to scientific discovery through “Workflow as a Service.” This capability moves beyond static computational resources by dynamically provisioning and executing complex simulation workflows on demand. Researchers can define intricate computational tasks – from molecular dynamics to climate modeling – and the cloud infrastructure automatically allocates the necessary processing power, storage, and software. This eliminates bottlenecks associated with resource limitations and lengthy setup times, drastically accelerating the pace of research. By abstracting away the complexities of infrastructure management, scientists are empowered to focus entirely on the scientific questions at hand, fostering innovation and enabling exploration of previously intractable problems. The result is a more agile and responsive research environment, capable of rapidly iterating on hypotheses and driving breakthroughs across diverse scientific disciplines.
The successful implementation of artificial intelligence within scientific discovery isn’t solely a matter of computational power; it critically relies on the continued expertise of the High Energy Physics (HEP) community. These physicists possess a deeply ingrained understanding of complex data analysis, simulation techniques, and the nuances of experimental results-knowledge essential for accurately interpreting the outputs of AI models. This domain expertise isn’t simply about verifying conclusions, but actively shaping the AI’s learning process, guiding model refinement, and ensuring the generated insights are physically meaningful and scientifically valid. Without this specialized knowledge, AI risks identifying spurious correlations or generating results divorced from established scientific principles, hindering rather than accelerating the pace of discovery. Therefore, integrating the HEP community’s experience is paramount to building trustworthy and effective AI-driven scientific tools.
The envisioned AI-Native Facility represents a fundamental shift in how scientific discovery is approached, promising to redefine experimentation and innovation through large-scale, AI-driven workflows. This facility is projected to directly support approximately 120 full-time equivalent positions over the next five years, while fostering a much broader collaborative network encompassing roughly twice that number of contributing researchers. Crucially, this initiative prioritizes workforce development, with ambitious goals to train approximately 2,000 doctoral students and an impressive 20,000 undergraduate students over the coming decade – ensuring a future generation equipped to harness the power of artificial intelligence for groundbreaking scientific advancement.

The pursuit of an AI-native research ecosystem in particle physics isn’t about constructing a flawless edifice, but cultivating a responsive system. This whitepaper acknowledges the inevitable decay inherent in complex infrastructure, mirroring the second law of thermodynamics. As Isaac Newton observed, “What goes up must come down.” The document doesn’t propose a static solution, but a framework anticipating future shifts in data handling and analytical techniques. The emphasis on foundation models and adaptable cyberinfrastructure suggests a recognition that even the most robust systems will require continuous evolution to overcome entropy and maintain relevance in the face of ever-increasing data complexity. This is not architecture; it is careful gardening.
Where Do We Go From Here?
The proposal of an ‘AI-native’ ecosystem for particle physics feels less like construction and more like a carefully tended garden. Each layer of machine learning, each foundation model integrated into data acquisition, is a commitment-a prophecy of the specific failures that will necessitate future adaptation. Scalability is, after all, simply the word used to justify complexity. The vision presented isn’t about eliminating challenges, but about shifting where those challenges manifest. One imagines a future not of effortless discovery, but of increasingly sophisticated debugging at the meta-level-optimizing not what is learned, but how learning itself breaks down.
The emphasis on AI as a tool for enhancing existing workflows feels…safe. A truly radical reimagining might involve ceding control-allowing algorithms to formulate not just analyses, but questions. Such a shift, however, raises the inevitable specter of interpretability-of losing the human thread within the ever-growing web of automated inference. Everything optimized will someday lose flexibility, and the pursuit of ever-greater precision may paradoxically diminish the capacity for serendipitous discovery.
The ‘perfect architecture’ is a myth-a necessary fiction to provide a sense of direction. The true task, then, isn’t to build the ultimate system, but to cultivate an environment where graceful degradation is not merely anticipated, but embraced. The future of particle physics, within this framework, may not be about finding the answers, but about becoming exquisitely attuned to the shape of the unknown.
Original article: https://arxiv.org/pdf/2602.17582.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
2026-02-20 07:07