Author: Denis Avetisyan
A new approach leverages the power of multi-agent collaboration to enhance how AI understands images and text, even when faced with unfamiliar concepts.
This review details a multi-agent cooperative learning framework for robust cross-modal alignment in visual language models, improving performance on out-of-distribution concepts and enabling better few-shot and zero-shot learning.
Vision-language models struggle to maintain robust cross-modal alignment when confronted with concepts unseen during training, leading to performance degradation. This paper introduces ‘Multi-Agent Cooperative Learning for Robust Vision-Language Alignment under OOD Concepts’, a novel framework employing collaborative agents to mitigate modality imbalance and enhance generalization. By enabling multi-agent feature space learning and adaptive balancing, the proposed method achieves significant gains in few-shot and zero-shot performance on the VISTA-Beyond dataset. Could this multi-agent approach represent a broadly applicable strategy for improving the robustness of vision-language systems in dynamic, real-world scenarios?
The Limits of Familiarity: Why Vision-Language Models Struggle with the Unexpected
Visual Language Models (VLMs) demonstrate remarkable proficiency when processing images and text aligned with their training datasets, achieving high accuracy on familiar objects and scenarios. However, this competence sharply declines when presented with concepts – visual or linguistic – that fall outside of this pre-defined experience. This limitation poses a significant hurdle for real-world deployment, where unpredictable novelty is the norm; a VLM trained on common household objects, for instance, might falter when asked to interpret images of specialized scientific equipment or rare wildlife. The core issue isn’t a lack of processing power, but rather an inability to generalize learned representations to truly unseen data, hindering their adaptability and reliability in dynamic, open-ended environments.
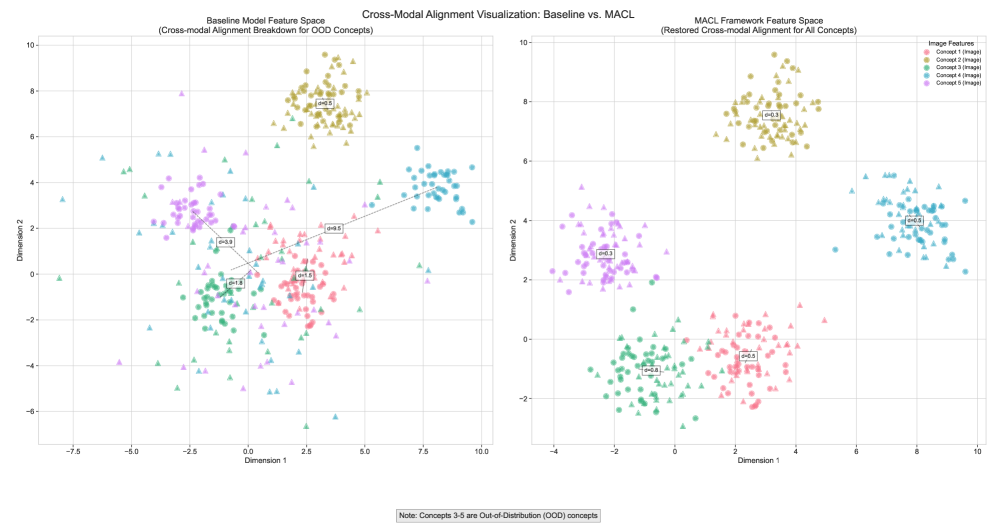
The limitations of visual language models when encountering unfamiliar concepts stem from a fundamental issue in how these models learn: a breakdown in cross-modal alignment. Pre-training, while effective for data seen during training, doesn’t inherently equip a model to build consistently robust feature representations applicable to genuinely novel scenarios. Essentially, the model learns correlations within its training data, but struggles to generalize these to concepts where those correlations don’t hold true. This means that when presented with an image and text describing an unseen object or situation, the model’s ability to connect visual features with linguistic descriptions falters, as the learned associations aren’t strong enough to bridge the gap to this new, out-of-distribution data. Consequently, the model’s understanding isn’t based on true conceptual understanding, but rather on pattern recognition limited to the scope of its initial training.
Despite considerable effort, established techniques for adapting Visual Language Models to new concepts have proven largely insufficient. Parameter-Efficient Fine-Tuning, which aims to modify only a small subset of a model’s parameters, often fails to instill the necessary representational flexibility to generalize beyond known visual categories. Similarly, while Prompt Engineering can guide a model’s existing knowledge, it struggles to create understanding where fundamental visual concepts are absent. These methods frequently result in superficial improvements or rely heavily on carefully crafted prompts, indicating a deeper limitation in the model’s ability to truly learn and apply knowledge about previously unseen objects or scenarios. Consequently, current approaches offer only incremental gains and highlight the need for more robust strategies to address out-of-distribution generalization in VLMs.
Deconstructing the Monolith: Introducing Multi-Agent Collaborative Learning
Multi-Agent Collaborative Learning (MACL) addresses limitations in traditional Vision-Language Models (VLMs) by restructuring them as a distributed network of specialized agents. This decomposition consists of three primary agents: the Image Agent, responsible for processing visual information; the Text Agent, focused on natural language understanding and generation; and the Name Agent, which handles entity recognition and linking. Each agent operates independently on its designated modality, but collaborates with the others to achieve a unified understanding and response. This modular design allows for focused training and optimization of each component, potentially improving overall performance and adaptability compared to monolithic VLM architectures. The agents communicate and share intermediate representations, enabling a more nuanced and comprehensive processing of multimodal data.
Structured Collaborative Learning within the MACL architecture utilizes OpenCLIP as its foundation to facilitate information exchange between specialized agents. Each agent – Image, Text, and Name – processes input data relevant to its modality and then shares refined representations with other agents. This exchange isn’t static; adaptive mechanisms govern the flow of information, allowing agents to prioritize relevant data from peers based on concept complexity. Specifically, agents dynamically adjust the weighting of incoming information, focusing on contributions that improve overall performance and reduce uncertainty in multi-modal understanding. This iterative process of representation refinement and information weighting enables the model to learn more robust and adaptable multi-modal representations.
The Coordinator Agent within the MACL framework functions as a central control unit, responsible for orchestrating interactions between the Image, Text, and Name Agents. This agent implements Difficulty-Based Adaptive Processing by evaluating the complexity of input concepts and dynamically adjusting the collaborative strategy accordingly. Specifically, it modulates information exchange frequencies and weighting between agents; more complex concepts trigger increased communication and a shift towards prioritizing agents with relevant expertise. This adaptive mechanism ensures efficient resource allocation and optimized synergy, allowing the VLM to effectively process both simple and challenging inputs without requiring retraining or manual adjustment of agent roles.
Demonstrating Adaptability: Validation on Unseen Concepts
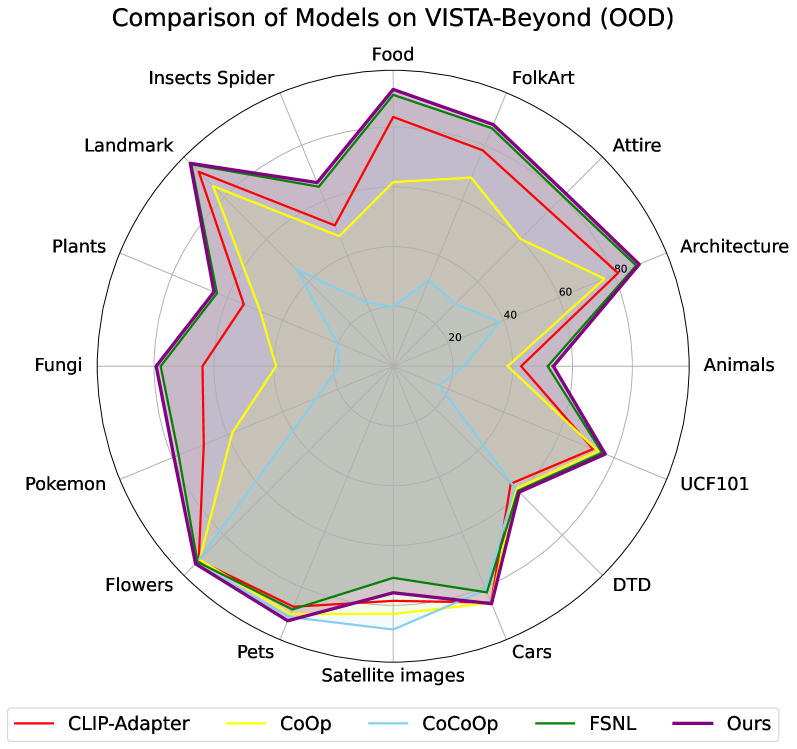
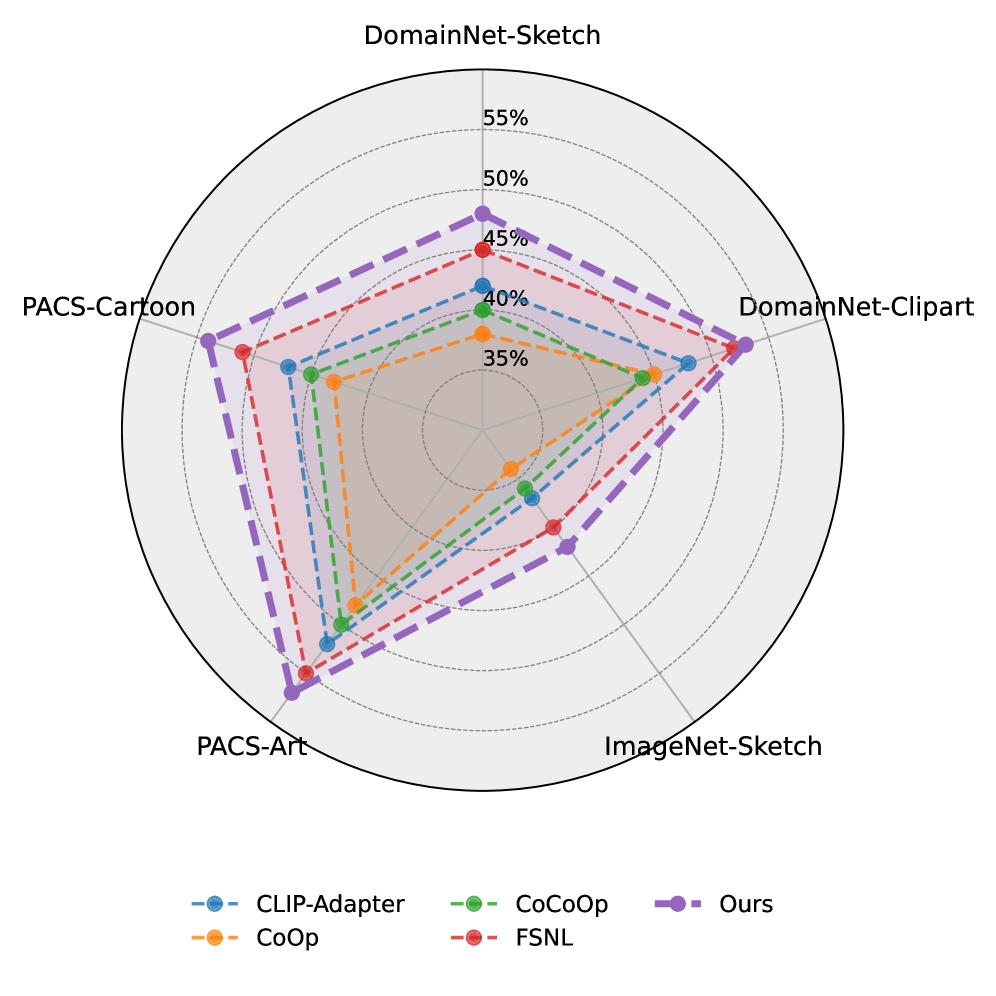
Evaluation of the Multi-Agent Collaborative Learning (MACL) framework was conducted using the VISTA-Beyond dataset, a benchmark specifically constructed for assessing performance in zero-shot and few-shot learning scenarios involving previously unseen concepts. This dataset facilitates the measurement of an agent’s ability to generalize to new tasks without, or with limited, task-specific training examples. The VISTA-Beyond dataset’s design centers on evaluating cross-modal understanding and collaborative problem-solving, making it well-suited for demonstrating MACL’s capabilities in novel environments and challenging scenarios where pre-existing knowledge is insufficient.
The Context-Aware Cross-Modal Fusion mechanism within the MACL framework facilitates information exchange between agents operating on different data modalities – specifically, visual and textual inputs. This fusion process addresses the inherent challenges of cross-modal misalignment, where discrepancies between visual and textual representations can hinder accurate perception and reasoning. By effectively correlating information across modalities, the mechanism improves the agent’s ability to understand complex scenarios and generate appropriate responses. Evaluation on the VISTA-Beyond dataset demonstrates an average precision gain ranging from 1% to 5% attributable to this fusion capability, indicating a significant performance improvement in zero-shot and few-shot learning scenarios involving novel concepts.
The implementation of ‘TransCLIP’ facilitates knowledge transfer from previously learned, in-distribution concepts to improve performance on unseen tasks, enabling both zero-shot and few-shot learning capabilities. Ablation studies conducted to assess the contribution of each agent demonstrate the importance of each component; removal of the Image Agent results in a 3.8% performance decrease, while the Text and Name Agents contribute to a 2.5% and 4.0% performance drop, respectively. Further analysis indicates that removing the Coordination Agent leads to a 3.5% reduction in overall performance, highlighting its crucial role in the system’s functionality.
Towards Truly Intelligent Systems: The Promise of Collaborative AI
The development of Multi-Agent Contrastive Learning (MACL) signifies a notable advancement in the pursuit of robust vision-language models (VLMs). Traditional VLMs often rely on contrastive learning techniques, specifically ‘InfoNCE Loss’, which can lead to fragility when faced with novel situations or variations in data. MACL addresses this limitation by framing the learning process as a collaborative effort between multiple agents, each with a slightly different perspective on the visual and linguistic input. This approach encourages the model to develop a more nuanced and generalized understanding, diminishing its susceptibility to spurious correlations and enhancing its ability to adapt to real-world complexities. Consequently, MACL not only improves performance on existing benchmarks but also promises a VLM that is demonstrably more resilient and capable of handling unforeseen circumstances, marking a key step toward truly adaptable artificial intelligence.
Further development of Multi-Agent Collaborative Learning (MACL) prioritizes increasingly complex strategies for agent coordination, moving beyond simple communication to encompass nuanced teamwork and collaborative problem-solving. Researchers intend to investigate lifelong learning paradigms, enabling the model to continuously refine its capabilities through ongoing interaction with dynamic environments and novel data. This involves developing mechanisms for incremental knowledge acquisition, skill consolidation, and adaptation to evolving tasks, ultimately fostering a system that doesn’t merely perform well on pre-defined benchmarks but genuinely learns and improves over time, mirroring the adaptability seen in human intelligence. The goal is not just enhanced performance, but a vision-language AI that actively refines its understanding of the world through continuous experience.
The development of MACL signifies a departure from conventional, single-network vision-language models, instead embracing a modular architecture where specialized agents collaborate to process information. This distributed approach allows for greater flexibility and robustness, mirroring the way humans integrate visual and linguistic cues. By breaking down complex tasks into manageable sub-problems handled by individual agents, MACL demonstrates an increased capacity to generalize beyond the specific training data, ultimately striving for AI that doesn’t merely recognize patterns, but truly understands the relationships between what it sees and what it’s told. This move toward modularity isn’t simply a technical improvement; it represents a fundamental shift in how AI is constructed, bringing it closer to the adaptable, interconnected processing of the human brain and opening possibilities for more nuanced and human-like interactions with the world.
The pursuit of robust vision-language alignment, as detailed in this work, benefits from a relentless distillation of complexity. The framework proposed, MACL, strives for efficiency in cross-modal understanding, particularly when faced with novel concepts-a clear move toward parsimony. This echoes John von Neumann’s sentiment: “The best way to predict the future is to invent it.” The researchers haven’t simply accepted the limitations of existing models when encountering out-of-distribution data; instead, they’ve engineered a solution, demonstrating that true understanding isn’t about accumulating features, but about discerning the essential elements for effective generalization. The elegance of MACL lies in its ability to foster collaboration and focus learning, removing unnecessary layers to achieve a more streamlined and adaptable system.
Where Do We Go From Here?
The proliferation of ‘frameworks’ often signals a discomfort with fundamental limitations. This work, while elegantly addressing the brittle nature of visual-language alignment when faced with the genuinely novel, does not escape that pattern entirely. It treats the symptom – out-of-distribution concepts – with a clever collaborative strategy. The underlying unease, however, remains: these models still fundamentally see only what they have been taught to expect. Future efforts might well benefit from a shift in emphasis – from increasingly complex alignment techniques, to a more honest reckoning with the limits of distributional learning.
The current paradigm prizes scalability and generalization, often at the cost of genuine understanding. A truly robust system will not merely learn to associate labels with features, but to construct something akin to causal models of the world. The marginal gains from incremental improvements to contrastive learning are diminishing; the next leap may require embracing approaches that prioritize interpretability, and perhaps even a degree of ‘forgetting’ – a willingness to discard obsolete associations in the face of new evidence.
It is tempting to envision a future of ever-expanding datasets and model parameters. Yet, the most fruitful path may lie in parsimony. Simplicity, after all, is not merely an aesthetic preference, but a practical necessity. The true test of intelligence is not how much one can know, but how effectively one can learn – and, crucially, how gracefully one can admit what remains unknown.
Original article: https://arxiv.org/pdf/2601.09746.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- M7 Pass Event Guide: All you need to know
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- JJK’s Worst Character Already Created 2026’s Most Viral Anime Moment, & McDonald’s Is Cashing In
2026-01-19 02:29