Author: Denis Avetisyan
Researchers have developed a new framework that allows humanoid robots to perform complex, coordinated movements while interacting with their environment.
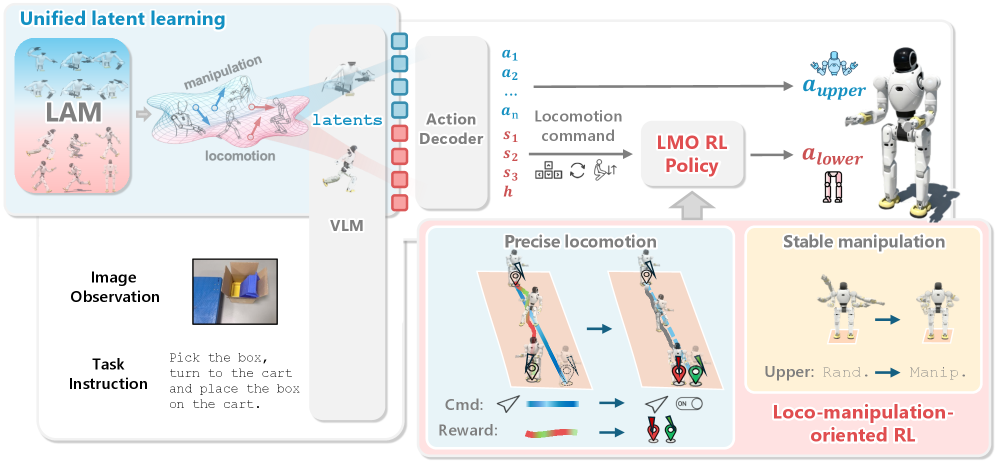
WholeBodyVLA unifies latent action learning and reinforcement learning for robust whole-body loco-manipulation control in humanoid robots.
Achieving truly versatile humanoid robots requires seamless integration of locomotion and manipulation, yet current approaches struggle with manipulation-aware movement in complex environments. This work introduces WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control, a novel framework leveraging unified latent learning from egocentric video and a loco-manipulation-oriented reinforcement learning policy. Demonstrating a 21.3% performance gain on the AgiBot X2 humanoid, WholeBodyVLA enables robust, large-scale loco-manipulation and exhibits strong generalization across tasks. Could this unified approach represent a key step towards more adaptable and capable humanoid robots operating in real-world scenarios?
Deconstructing Movement: The Challenge of Embodied Intelligence
The pursuit of robots capable of both locomotion and dexterous manipulation – often termed loco-manipulation – presents a significant hurdle in the field of robotics. Unlike stationary robots performing repetitive tasks, a truly versatile machine must seamlessly coordinate movement through space with intricate object interactions, all while adapting to unpredictable environments. This requires overcoming challenges in both hardware design – creating robust, multi-limbed systems – and software control, where algorithms must manage a high-dimensional state space and contend with delays and disturbances. Current systems often excel in either locomotion or manipulation, but integrating these capabilities into a fluid, reliable skillset remains a central, unsolved problem hindering the deployment of robots in complex, real-world scenarios like search and rescue, in-home assistance, and disaster response.
Conventional robotic control systems often falter when confronted with the unpredictable nature of real-world environments. These methods typically rely on precisely engineered movements and pre-programmed responses, proving inadequate for tasks demanding real-time adaptation and intricate coordination-such as a robot simultaneously walking and manipulating objects. The sheer number of variables involved – uneven terrain, unexpected obstacles, and the physics of interacting with deformable objects – quickly overwhelms these systems. Consequently, robots struggle with even seemingly simple actions that require nuanced adjustments and the ability to recover from disturbances. This limitation highlights the need for more sophisticated control architectures capable of handling the inherent complexities of dynamic, physical interactions and achieving truly robust and adaptable locomotion and manipulation.
The pursuit of robots capable of complex tasks relies increasingly on learning from demonstration, a technique where robots acquire skills by observing human performance. However, a significant hurdle remains: efficiently generalizing these learned skills to novel situations with minimal training data. Current methods often require extensive examples for the robot to adapt to even slight variations in its environment or the task itself. Researchers are actively exploring techniques like meta-learning and transfer learning to enable robots to quickly assimilate new information from a few demonstrations, effectively building a foundation of prior knowledge that allows for rapid adaptation. This involves developing algorithms that can identify the underlying principles of a task, rather than simply memorizing specific sequences of actions, ultimately paving the way for robots that can reliably perform tasks in dynamic, unpredictable real-world scenarios.
Unlocking Intuition: Unified Latent Learning
WholeBodyVLA is a proposed framework designed to learn from human demonstrations of loco-manipulation tasks. It utilizes Unified Latent Learning to distill essential movement characteristics, termed ‘priors’, from observed human actions. This approach aims to capture the underlying principles of how humans coordinate locomotion and manipulation, enabling robots to generalize beyond specific demonstrated trajectories. The framework functions by analyzing human performance data and extracting a compressed representation of successful strategies, which can then be applied to new, unseen scenarios. This differs from traditional methods by focusing on how tasks are performed, rather than simply replicating specific motions.
The Latent Action Model (LAM) functions by encoding egocentric vision data – that is, visual information captured from a first-person perspective – into a compressed, discrete latent space. This encoding process utilizes vector quantization to represent continuous visual inputs with a finite set of learned codes, resulting in a compact representation. The discrete nature of this latent space facilitates efficient learning and generalization by reducing the dimensionality of the input data and allowing the model to focus on the most salient features for action prediction. This approach allows for the representation of complex, high-dimensional visual data in a manner suitable for downstream tasks such as robot control and imitation learning.
The Latent Action Model (LAM) facilitates efficient representation and generalization of complex movements through a combination of Variational Quantized-Variational Autoencoder (VQ-VAE) and DINOv2. VQ-VAE compresses high-dimensional egocentric vision data into a discrete latent space, reducing computational demands and enabling the learning of distinct movement primitives. DINOv2, a self-supervised vision transformer, provides robust feature extraction, improving the quality of the learned latent representations and their ability to generalize to novel scenarios. This combination allows the LAM to capture the essential characteristics of loco-manipulation tasks with a compact representation, enabling efficient policy learning and transfer to new environments.
The framework seeks to improve robotic autonomy by directly learning from human movement demonstrations, addressing the common discrepancy between observed actions and successful robot execution. This is achieved not through direct imitation, but by extracting underlying principles – or “priors” – of loco-manipulation from human data. By identifying and encoding these learned priors into a compact latent space, the system aims to generalize beyond the specific demonstrations provided and enable robust performance in novel situations. This approach circumvents the need for extensive hand-engineering of control policies and facilitates the transfer of human intuitive understanding to robotic systems, enabling more natural and adaptable behavior.

From Code to Embodiment: Translating Latent Space to Action
Training Locomotion and Manipulation Latent Action Models (LAMs) independently yields performance gains in complex scenarios. This modular approach allows for specialized learning of each skill – locomotion and manipulation – optimizing the latent space representation for each. Specifically, decoupling these skills improves generalization to novel tasks and environments by preventing interference during the learning process. Empirical results demonstrate that a LAM trained solely on locomotion exhibits improved navigational abilities, while a dedicated manipulation LAM achieves higher success rates in object interaction tasks, ultimately leading to superior overall performance when combined in a complete system.
The Loco-Manipulation-Oriented (LMO) Reinforcement Learning (RL) policy utilizes a discrete command interface to facilitate stable and precise execution of combined locomotion and manipulation tasks. This interface allows for the specification of high-level actions, abstracting away low-level motor control and enabling the policy to learn a mapping from these discrete commands to appropriate robot behaviors. By decoupling task specification from execution, the LMO policy achieves improved stability during complex maneuvers and enables precise control over both the robot’s movement and its interactions with the environment. This contrasts with direct velocity control approaches which require precise, continuous state estimation and are more susceptible to accumulated errors.
Comparative analysis demonstrates that the proposed Loco-Manipulation-Oriented (LMO) RL policy exhibits superior performance characteristics to traditional velocity-tracking RL policies. Specifically, the LMO policy demonstrates increased robustness to environmental disturbances and variations in task parameters, as evidenced by a lower failure rate across a suite of complex locomotion and manipulation tasks. Furthermore, the LMO policy displays enhanced adaptability, requiring fewer training iterations to achieve comparable or improved performance on novel scenarios and exhibiting greater generalization capability when presented with previously unseen object configurations or task objectives. These improvements are quantitatively assessed through metrics including success rate, completion time, and path deviation, consistently favoring the LMO approach.
Training of the robotic system utilized a two-stage process for validation and refinement. Initially, teleoperation data, collected from human demonstrations of desired manipulation tasks, served as the primary source for validating the learned policies and ensuring initial performance. This data provided a baseline for acceptable behavior and facilitated the assessment of policy improvements. Subsequently, training was further refined using the AgiBot World dataset, a synthetic environment designed to provide a wider range of manipulation scenarios and facilitate the acquisition of more robust and generalized manipulation skills. This dataset allowed for increased exposure to diverse object properties, task variations, and environmental conditions, leading to improved performance beyond the initial teleoperation validation.
The Proof of Concept: Validating Performance Across Complex Tasks
The WholeBodyVLA framework has proven capable of tackling a diverse set of loco-manipulation challenges, effectively merging movement and object interaction. This system doesn’t simply perform isolated actions; it coordinates full-body motion with precise manipulation, allowing it to navigate complex scenarios like packing a bag with multiple items, loading boxes onto a conveyor, and dynamically pushing a cart through an environment. The success across these varied tasks-each requiring different strategies for balance, force application, and spatial awareness-highlights the framework’s adaptability and robustness. It signifies a step towards robots that can fluidly operate in real-world settings, handling both movement and manipulation simultaneously with a level of proficiency previously unseen.
The WholeBodyVLA framework’s versatility is demonstrated through its successful execution of complex, real-world tasks such as bag packing, box loading, and cart pushing. These scenarios were specifically chosen to test the system’s ability to adapt to diverse environments and handle objects with varying shapes, sizes, and weights. Successfully completing bag packing requires delicate manipulation and spatial reasoning within a confined space, while box loading demands precise movements and force control to safely stack items. The cart pushing task further assesses the system’s capacity for dynamic balancing and navigation while interacting with an external object. The consistent success across these tasks highlights the framework’s robust adaptability and its potential for deployment in unstructured, everyday settings.
The core strength of the WholeBodyVLA framework lies in its seamless integration of locomotion and manipulation, allowing for remarkably efficient and robust task completion. This coordination isn’t simply about moving and acting; it’s about dynamically adjusting movement based on manipulation requirements, and vice versa. The system doesn’t treat these as separate problems; instead, it solves them simultaneously, enabling the robot to navigate complex environments while skillfully interacting with objects. This holistic approach proves particularly valuable in dynamic scenarios where unexpected obstacles or shifts in object position demand immediate, coordinated responses, resulting in a system capable of completing tasks with a high degree of reliability and speed, even under challenging conditions.
Rigorous evaluation of the WholeBodyVLA framework on the Agibot X2 platform demonstrates a significant advancement in robotic performance. Comprehensive experiments reveal that this system surpasses existing state-of-the-art methods by a substantial margin – achieving improvements of 21.3% and 24.0% across a suite of complex loco-manipulation tasks. These results highlight not only the efficacy of the framework’s integrated approach to coordinating movement and manipulation, but also its capacity to reliably execute tasks with greater efficiency and robustness than previously possible. This measurable performance gain establishes WholeBodyVLA as a leading solution for robots operating in dynamic and demanding real-world environments.
The pursuit of unified latent learning, as demonstrated by WholeBodyVLA, echoes a fundamental principle: understanding isn’t about passively accepting defined boundaries, but actively probing them. This framework doesn’t simply teach a robot loco-manipulation; it establishes a system where the robot learns to navigate the space between actions, finding emergent solutions. Ada Lovelace observed that “The Analytical Engine has no pretensions whatever to originate anything.” Yet, WholeBodyVLA suggests a compelling counterpoint-the engine, when given the right framework, reveals possibilities not explicitly programmed, hinting at a generative capacity born from systematic exploration. The system isn’t about avoiding bugs, but recognizing that unexpected behaviors can illuminate deeper patterns within the control architecture.
Pushing the Boundaries
The elegance of WholeBodyVLA lies in its consolidation – a unified latent space for locomotion and manipulation. But consolidation, by its nature, invites interrogation. What happens when the latent space over-consolidates? When the distinctions between subtle manipulations and gross locomotor adjustments become blurred, does the system exhibit a brittle form of generalization? The demonstrated robustness is encouraging, yet the true test lies in deliberately introducing ambiguity – tasks demanding a fluid transition between locomotion and manipulation, not simply their co-occurrence. A truly unified system should fail gracefully when pushed to the limits of its abstraction, revealing the underlying principles that still require refinement.
Furthermore, the reliance on reinforcement learning, while effective, begs the question of sample efficiency. Current methods often require extensive simulation or real-world interaction. A compelling next step involves actively misleading the RL agent – injecting adversarial perturbations into the visual or linguistic input. Can the system maintain performance under conditions designed to exploit its perceptual vulnerabilities? Identifying these failure modes isn’t about damage control; it’s about reverse-engineering the internal representations that allow it to function at all.
Ultimately, the pursuit of unified latent spaces isn’t about achieving a singular, all-encompassing solution. It’s about identifying the necessary abstractions-the minimal set of representations that allow a complex system to navigate a complex world. The true innovation won’t be in minimizing the number of parameters, but in maximizing the information encoded within each one.
Original article: https://arxiv.org/pdf/2512.11047.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- M7 Pass Event Guide: All you need to know
- Best Arena 9 Decks in Clast Royale
- Clash Royale Furnace Evolution best decks guide
- Best Hero Card Decks in Clash Royale
- Clash of Clans January 2026: List of Weekly Events, Challenges, and Rewards
2025-12-15 14:22