Author: Denis Avetisyan
Researchers have developed a new AI planning system that allows robots to understand and execute complex, everyday tasks in dynamic home environments.
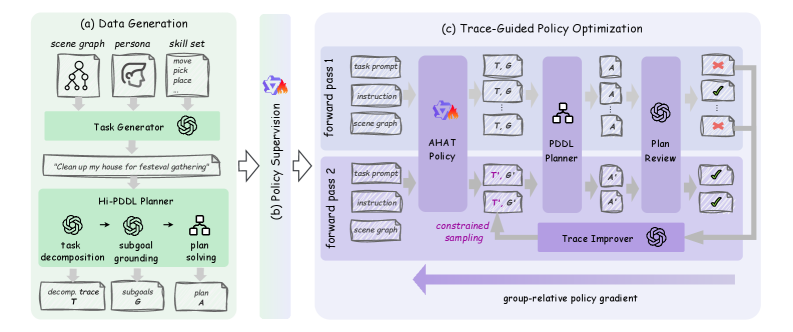
This work introduces AHAT, a reinforcement learning-trained task planner utilizing large language models and subgoal decomposition for scalable long-horizon planning in household robotics.
Despite advances in robotic task planning, scaling to complex, real-world environments with ambiguous human instructions remains a significant challenge. This paper introduces ‘Any House Any Task: Scalable Long-Horizon Planning for Abstract Human Tasks’, a novel framework that addresses this limitation by leveraging a large language model trained to decompose abstract goals into grounded, executable subgoals defined in [latex]PDDL[/latex]. The resulting system, AHAT, achieves improved performance through reinforcement learning, specifically a novel algorithm, TGPO, which incorporates external correction of reasoning traces. Could this approach unlock more intuitive and robust human-robot interaction in everyday household tasks and beyond?
Deconstructing the Horizon: The Limits of Prediction
Conventional Large Language Models, while adept at many linguistic tasks, demonstrably falter when confronted with problems demanding protracted reasoning or multi-step planning. These models typically operate by predicting the next token in a sequence, a process that, while effective for short-term coherence, struggles to maintain a consistent, goal-oriented trajectory over extended sequences of actions. The core limitation isn’t necessarily a lack of knowledge, but rather a deficiency in maintaining contextual relevance across numerous iterative steps; errors accumulate and derail the planning process. Consequently, tasks requiring complex foresight – such as game playing with intricate strategies, robotic navigation in dynamic environments, or long-form content creation with nuanced thematic development – present significant challenges. The model’s ability to ‘look ahead’ and accurately assess the consequences of each action diminishes rapidly as the planning horizon extends, leading to suboptimal or incoherent outcomes.
The difficulty current Large Language Models face in long-horizon planning stems from a limited ability to break down complex goals into manageable, sequential steps. These models often treat extended tasks as monolithic challenges, lacking the capacity to deconstruct them into a series of smaller, executable actions. This deficiency in task decomposition isn’t merely a matter of computational power; even scaled-up models struggle because they fail to identify the intermediate sub-goals necessary for sustained progress. Consequently, performance deteriorates rapidly as the planning horizon extends, as the model becomes increasingly prone to errors and deviations from the intended outcome. Effective long-horizon planning necessitates not just intelligence, but the architectural capacity to systematically dissect a problem and formulate a coherent, multi-step strategy for its resolution.
Despite the remarkable progress in Large Language Models fueled by increased computational power and data, simply scaling these models proves insufficient for tackling genuinely complex, long-horizon planning challenges. Research indicates that performance plateaus arise not from a lack of data or parameters, but from inherent limitations in the models’ architectural capacity to effectively decompose problems into manageable sub-goals and maintain coherent reasoning over extended sequences. This suggests a need to move beyond the current paradigm of monolithic models towards novel architectures explicitly designed for hierarchical planning, incorporating mechanisms for memory, abstraction, and the ability to explore potential future states-a fundamental shift required to achieve robust and reliable long-term decision-making capabilities.
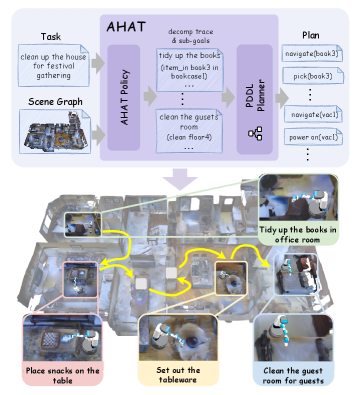
Forging a Path: Introducing AHAT
AHAT employs reinforcement learning to train a Large Language Model (LLM) to forecast sequences of task subgoals. These subgoals are not expressed in natural language but are formally defined using Planning Domain Definition Language (PDDL), a standardized knowledge representation for planning problems. The LLM learns to predict a series of PDDL goals that, when executed, will achieve a larger, complex task. This approach allows AHAT to decompose tasks into manageable steps and leverage the LLM’s predictive capabilities for planning, rather than directly generating executable actions. The reinforcement learning process optimizes the LLM’s policy to maximize the probability of predicting subgoal sequences that lead to successful task completion, as determined by an external reward signal.
The AHAT framework integrates a Planning Domain Definition Language (PDDL) Planner to bridge the gap between high-level task subgoals and concrete robotic actions. This planner receives a sequence of PDDL goals, representing desired states of the environment, and autonomously generates a plan consisting of executable actions to achieve those goals. By leveraging a symbolic planning approach, the system can reason about action preconditions, effects, and constraints, ensuring that the generated plans are valid and feasible within the environment’s defined physics and constraints. This planning process allows for robust task execution, even in complex or uncertain environments, as the planner can adapt to changing conditions and replan as necessary to achieve the desired outcome.
AHAT employs a scene graph representation to provide the LLM with a structured understanding of the environment, facilitating more effective task planning. This scene graph encodes objects, their attributes, and their relationships within the current context. By processing information in this graph format, the LLM can accurately identify relevant entities and their states, which is crucial for formulating appropriate PDDL goals. The scene graph serves as a dynamic, contextual input that improves the LLM’s ability to reason about the environment and select actions that align with the desired task objectives, ultimately enhancing the robustness and success rate of task execution.
Supervised Fine-Tuning (SFT) serves as the initial training phase for the AHAT framework, establishing a foundational policy prior to reinforcement learning. This process involves training the Large Language Model (LLM) on a dataset of demonstrated task completions, where the LLM learns to predict sequences of task subgoals – expressed as Planning Domain Definition Language (PDDL) goals – by mimicking expert behavior. The SFT phase provides the LLM with a preliminary understanding of task structures and subgoal relationships, significantly accelerating and stabilizing the subsequent reinforcement learning process by reducing the exploration space and providing a reasonable starting point for policy optimization. This pre-training minimizes the need for random exploration, enabling the reinforcement learning algorithm to focus on refining the policy for improved performance and generalization.
The Proof Emerges: Empirical Validation
AHAT’s generalization capabilities were assessed through evaluation on the widely-used Habitat Simulated Semantic Dataset (HSSD) and Gibson environments. These datasets provide a diverse range of realistic, 3D scenes with varying complexities and object arrangements. Performance on these benchmarks demonstrated AHAT’s capacity to effectively plan and execute tasks in environments not encountered during training, validating its ability to adapt to novel situations and unseen visual data. This suggests AHAT learns underlying principles of task execution rather than memorizing specific scene configurations, a crucial characteristic for real-world applicability.
Evaluations utilizing the Human Tasks Dataset demonstrate AHAT’s capability to successfully plan and execute tasks modeled after real human demonstrations, achieving an overall success rate of 82.2%. This dataset comprises tasks performed by human subjects, providing a realistic benchmark for assessing the agent’s ability to understand and replicate complex, everyday actions. The success metric is determined by complete and accurate fulfillment of the task objectives as defined by the human demonstration data. These results indicate AHAT’s proficiency in interpreting human-like task instructions and translating them into executable plans within a simulated environment.
Quantitative evaluation demonstrates that AHAT achieves a substantial performance advantage over established robotic planning baselines, specifically DELTA and Reinforce++. On complex tasks, AHAT exhibits a 68.1% improvement in task completion rate when compared to the strongest performing baseline system. This improvement is measured by the percentage of successfully completed tasks across a standardized evaluation suite, indicating a significant increase in both the reliability and efficiency of AHAT’s planning capabilities. The metric accounts for all task parameters, including object manipulation, navigation, and constraint satisfaction, providing a comprehensive assessment of overall performance.
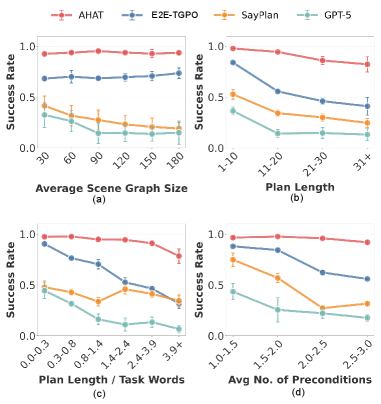
AHAT demonstrates superior performance compared to leading Large Language Model (LLM)-based planners, specifically GPT-5 and Gemini-3, on abstract task planning. Evaluations reveal a 68.9% improvement in performance on these tasks relative to the strongest baseline. Critically, AHAT maintains robust performance across a range of task complexities, exhibiting a maximum performance decrease of only 19% when varying scene graph size, plan length, instruction abstractness, and constraint complexity. This indicates AHAT’s ability to generalize and maintain effectiveness even as task demands increase.
Beyond Simulation: Implications for Autonomous Systems
The architecture of AHAT reveals a potent synergy between large language models and symbolic planning systems, effectively bridging the gap between intuitive reasoning and rigorous execution. LLMs, adept at understanding natural language and inferring high-level goals, provide the initial decomposition of complex tasks into a series of achievable subgoals. However, these models often lack the precision required for reliable, long-term planning. This is where symbolic planners step in, leveraging formal logic and search algorithms to generate concrete action sequences that satisfy the defined objectives. By integrating these distinct strengths, AHAT avoids the pitfalls of relying solely on either approach, achieving a robust and adaptable planning framework capable of tackling intricate challenges beyond the reach of conventional methods. The result isn’t simply a combination of tools, but a system where the LLM’s reasoning guides the planner’s execution, creating a more intelligent and versatile autonomous agent.
The capacity to break down intricate objectives into a sequence of achievable subgoals represents a significant advancement in autonomous planning. This decomposition allows agents to navigate complex scenarios that extend far into the future – a capability known as long-horizon planning. Unlike traditional methods often stymied by the exponential growth of possibilities, this framework focuses on progressively solving smaller, more manageable problems. This approach is particularly crucial in dynamic and uncertain environments, where unforeseen circumstances frequently disrupt pre-defined plans; by re-planning at the subgoal level, the agent can adapt to changing conditions and maintain progress towards its ultimate goal. Consequently, tasks that were previously intractable due to their complexity and unpredictability become feasible, opening new avenues for autonomous operation in real-world applications.
The architecture underpinning AHAT isn’t confined to simulated environments; its learned policies and planning strategies demonstrate a remarkable capacity for transfer to real-world applications. This adaptability stems from the system’s ability to abstract core task decomposition and execution principles, allowing it to be readily deployed in fields like robotics and industrial automation. Imagine a robotic arm, guided by AHAT’s framework, not simply following pre-programmed instructions, but intelligently breaking down complex assembly tasks into achievable steps, dynamically adjusting to unforeseen obstacles, or even learning from iterative performance. Similarly, in automated manufacturing, AHAT’s planning capabilities could optimize production workflows, manage resource allocation, and proactively address potential disruptions – effectively broadening the scope of what autonomous agents can achieve beyond narrowly defined parameters and opening avenues for greater efficiency and resilience in complex operational systems.
The success of the AHAT framework signals a shift in how autonomous agents approach task planning, moving beyond reliance on meticulously crafted prompts and towards systems that learn and adapt. Unlike prompting-based methods such as SayPlan, which depend on explicitly instructing the agent for each step, AHAT develops a learned policy for decomposing tasks and generating plans. This allows the agent to navigate complex scenarios with greater flexibility and robustness, as it isn’t constrained by the limitations of pre-defined instructions. The demonstrated outperformance suggests that prioritizing learning and adaptation – enabling the agent to refine its planning strategies through experience – unlocks a new level of autonomy and efficiency, particularly in dynamic and unpredictable environments where explicit instruction proves insufficient.
“`html
The pursuit of abstract task planning, as demonstrated by AHAT, mirrors an inherent drive to dismantle complexity. The system doesn’t simply execute instructions; it dissects them, probing for fundamental components – a process echoing the exploratory spirit of rigorous inquiry. This echoes G.H. Hardy’s sentiment: “A mathematician, like a painter or a poet, is a maker of patterns.” AHAT, through its subgoal decomposition and reinforcement learning, isn’t merely solving problems; it’s constructing a pattern of solvable steps from the amorphous shape of an abstract request, revealing the underlying structure of even the most complex human tasks. The system’s capability to navigate long-horizon planning relies on questioning the initial prompt and reversing the initial approach.
Beyond the Blueprint
The architecture presented here – a large language model dissecting tasks into manageable components – feels less like a solution and more like a sophisticated relocation of the difficulty. The system efficiently plans around uncertainty, but does not fundamentally resolve it. Consider the inherent ambiguity in “tidy the living room.” The planner generates subgoals, yet the definition of ‘tidy’ remains stubbornly subjective, reliant on a training signal that inevitably embodies someone’s biases. The real frontier isn’t longer plans, but plans that can gracefully negotiate the inevitable misalignment between instruction and interpretation – a system that questions the task itself, rather than blindly executing it.
Current benchmarks, focused on discrete action sequences within constrained environments, offer limited insight into a system’s ability to cope with genuinely novel situations. A spilled glass of water, an unexpected obstruction, these aren’t errors in planning so much as failures of understanding. The next iteration demands a planner capable of actively building and refining its internal world model, treating each interaction not as a step towards completion, but as a data point for recalibration.
Ultimately, the pursuit of “general” task planning may be a misdirection. The universe doesn’t adhere to predefined plans; it improvises. Perhaps the most fruitful path lies not in creating a system that executes plans flawlessly, but one that learns to plan better through sustained, iterative failure – a system that embraces the chaos inherent in real-world interaction, recognizing that the most valuable knowledge is often found at the edge of predictability.
Original article: https://arxiv.org/pdf/2602.12244.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
2026-02-15 07:39