Author: Denis Avetisyan
Researchers have unveiled ABot-M0, a framework that unifies diverse robotic datasets and employs a novel learning technique to enable more general and adaptable robotic manipulation skills.
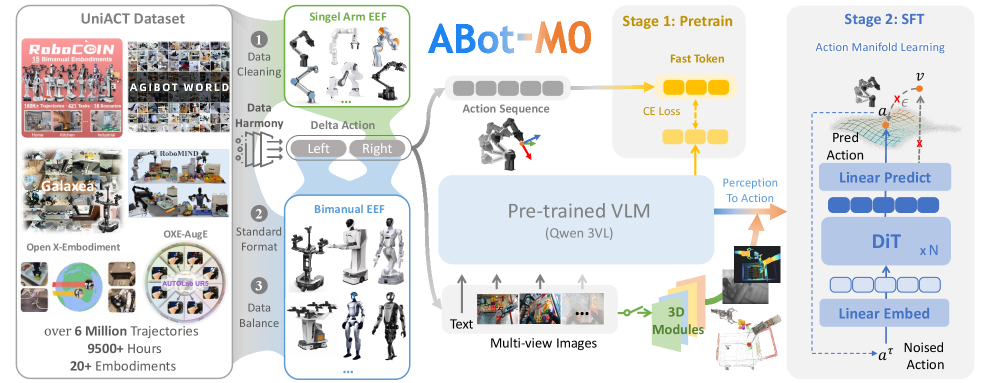
ABot-M0 leverages action manifold learning and standardized data to achieve state-of-the-art performance in cross-embodiment transfer and robotic task completion.
Achieving general-purpose robotic intelligence remains challenging due to fragmented data and inconsistent representations across diverse hardware platforms. This work introduces ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning, a framework designed to unify heterogeneous robotic datasets and learn efficient, transferable policies. Central to this approach is Action Manifold Learning, which posits that effective robot actions reside on a low-dimensional manifold, enabling more stable and efficient prediction. By combining a large-scale, standardized dataset with this novel learning technique, can we unlock truly general-purpose embodied agents capable of seamlessly adapting to new robotic platforms and tasks?
The Fragility of Conventional Robotic Systems
Conventional robotic policies often falter when confronted with even slight variations in their operational environment or assigned task. This inflexibility stems from a reliance on meticulously crafted, task-specific training regimens; a robot adept at grasping a red block in a controlled setting may fail utterly with a blue one, or when presented with a cluttered workspace. Such systems lack the inherent adaptability of biological organisms, demanding substantial retraining for each new scenario. The need for extensive, repetitive training isn’t merely a matter of time and resources; it fundamentally limits the scalability of robotic automation and hinders the development of truly autonomous machines capable of operating reliably in the real world’s inherent unpredictability. Consequently, researchers are actively exploring methods to imbue robots with the capacity for zero-shot or few-shot learning, enabling them to generalize from limited experience and apply existing knowledge to novel situations.
Many contemporary robotic systems are designed to operate by directly predicting individual motor commands – a process akin to micromanaging every joint movement. While seemingly straightforward, this approach creates significant inefficiencies and hinders adaptability. Each new environment or even a slight variation in an object’s position necessitates relearning these low-level actions, resulting in brittle performance and a heavy reliance on extensive training data. Instead of focusing on what needs to be achieved – grasping an object, for example – the robot is preoccupied with how to move its actuators, limiting its ability to generalize to novel situations or unforeseen circumstances. This granular control becomes a bottleneck, preventing the emergence of truly flexible and robust robotic behavior, and contrasts sharply with human manipulation which prioritizes high-level goals and leverages inherent motor skills.
The persistent challenge in embodied artificial intelligence lies in equipping robots with the capacity to interpret and utilize visual data for dexterous manipulation, a skill humans perform effortlessly. Current systems often treat visual input as merely a trigger for pre-programmed actions, failing to truly understand the objects and scenes before them. This limits their ability to adapt to novel situations or unexpected variations in the environment – a robot trained to grasp a red block, for example, might struggle with a blue one, or a red one presented at a different angle. Advancements hinge on developing algorithms that move beyond simple object recognition to encompass a deeper understanding of object properties – shape, size, weight, fragility – and how these properties relate to successful manipulation. The goal is not just to see an object, but to understand how to interact with it robustly, irrespective of variations in lighting, viewpoint, or background clutter.
The persistent gap between robotic manipulation and human dexterity stems from a fundamental challenge in unifying perception and action. Current robotic systems often treat these as separate processes – robots ‘see’ an object and then execute a pre-programmed sequence of movements. This contrasts sharply with human motor control, where visual input is continuously and unconsciously integrated into ongoing actions, allowing for real-time adjustments and nuanced responses to unexpected changes. Existing algorithms struggle to replicate this seamless flow, frequently resulting in rigid, brittle behaviors that fail in dynamic or unpredictable environments. Achieving true dexterity requires systems capable of not just recognizing objects, but also of understanding their affordances – what actions are possible with them – and seamlessly translating that understanding into fluid, adaptable movements, a feat that demands a more holistic and integrated approach to perception and action.

ABot-M0: A Unified Architecture for Embodied Intelligence
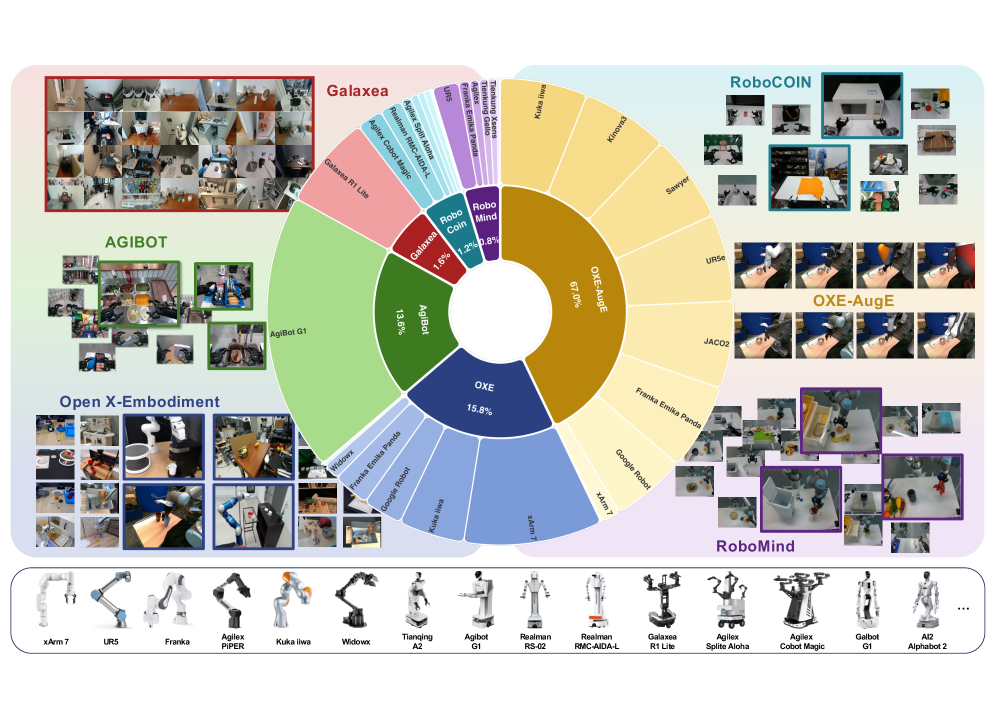
ABot-M0 utilizes a standardized data pipeline centered around the UniACT-Dataset to facilitate training and evaluation across heterogeneous robotic platforms. The UniACT-Dataset comprises a collection of multi-modal data, including visual observations, robot states, and corresponding actions, all formatted consistently. This standardization minimizes the need for data reformatting or platform-specific adjustments during training, allowing a single trained model to be deployed and tested on diverse robotic hardware with minimal modification. The pipeline includes data preprocessing, augmentation, and batching procedures designed to optimize performance and generalization across different robotic systems, thereby promoting efficient transfer learning and reducing development time.
ABot-M0 integrates the Qwen3-VL model to process and encode both visual and linguistic data, creating a unified representation of the robot’s environment and task instructions. This Vision-Language Model (VLM) accepts image inputs and associated text prompts, generating embeddings that capture the semantic relationships between observed features and desired outcomes. The resulting multimodal encoding allows the system to understand complex commands, interpret visual cues, and contextualize actions within the broader environment, ultimately informing the action planning process managed by the Diffusion Transformer.
ABot-M0 incorporates a Diffusion Transformer (DiT) as its core action generation module. The DiT architecture, pre-trained on extensive datasets, is utilized to predict subsequent action steps based on observed states and desired goals. This approach allows for the generation of diverse and adaptable action sequences, moving beyond pre-defined trajectories. The DiT operates by iteratively refining an initial action prediction through a diffusion process, enabling the system to handle complex tasks and environmental variations. This contrasts with traditional methods relying on discrete action spaces or fixed policies, providing a more nuanced and flexible control mechanism.
ABot-M0 utilizes a representation of robotic actions defined as changes in end-effector position, termed “Delta Actions”. This approach encodes actions as a continuous vector indicating displacement in Cartesian coordinates, rather than discrete motor commands. Consequently, the framework decouples action generation from specific robot kinematics and morphologies. This abstraction facilitates transfer learning; a policy trained on one robotic platform can be directly applied to another, even with differing link lengths or joint configurations, without requiring re-training or adaptation layers. The Delta Action space allows the Vision-Language Model and Diffusion Transformer to learn generalizable action primitives, promoting efficient knowledge transfer across heterogeneous robotic systems.
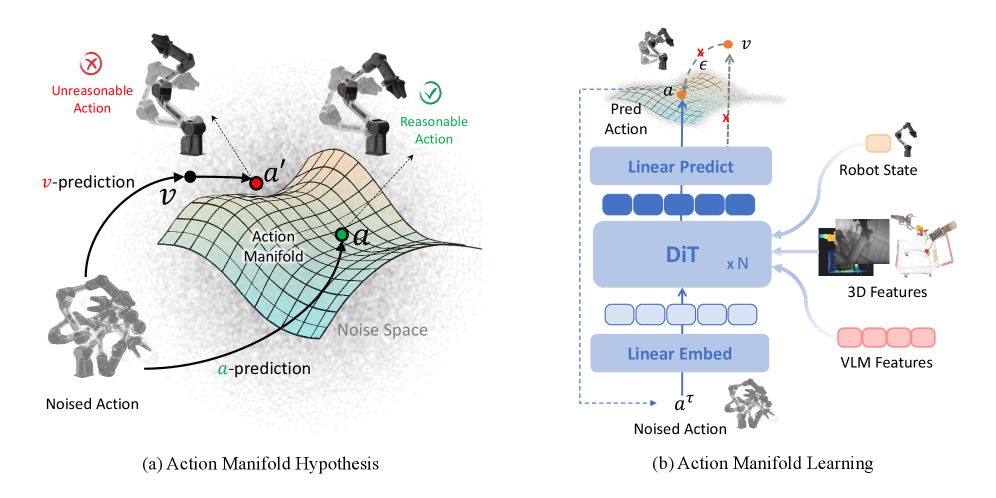
Action Manifold Learning: A Streamlined Path to Robust Control
Conventional robotic control methods often focus on predicting and compensating for noise in action execution, leading to inefficiencies and reduced robustness. In contrast, ABot-M0 employs Action Manifold Learning, a technique that directly predicts the complete sequence of actions required to achieve a desired outcome. This approach bypasses the need to model and mitigate noise, instead learning a mapping from observation to action sequences residing on a lower-dimensional manifold. By directly predicting actions, ABot-M0 streamlines the decoding process and enhances the policy’s ability to generalize to novel situations and maintain consistent performance despite environmental disturbances.
By directly predicting action sequences, ABot-M0 achieves increased decoding efficiency compared to methods that predict action noise. This direct prediction reduces computational demands during the decoding phase, resulting in faster response times. Furthermore, this approach significantly improves policy robustness by focusing on predicting valid actions within the learned action manifold, rather than being susceptible to noisy or irrelevant data. This focus on predictable actions leads to a more stable and reliable policy, particularly in dynamic or uncertain environments where external disturbances may occur.
ABot-M0 utilizes a Cross-Attention mechanism to integrate visual information derived from two distinct feature sets generated by the VGGT network. These feature sets consist of multi-view 2D features, capturing information from multiple camera perspectives, and single-view 3D features, providing a depth-aware representation from a single viewpoint. The Cross-Attention module allows the policy to selectively attend to relevant features from both modalities, effectively fusing them into a unified representation for action prediction. This fusion process enables the agent to leverage the complementary strengths of 2D and 3D visual data, enhancing its understanding of the environment and improving performance across a range of manipulation tasks.
Pad-to-Dual-Arm Modeling addresses the limitations of policies trained for a fixed number of arms by enabling operation across both single-arm and dual-arm manipulation tasks. This is achieved by augmenting action spaces with padding to ensure compatibility with both configurations; single-arm actions are represented with padding in the second arm’s action space, while dual-arm actions utilize the full action space. This unified representation eliminates the need for separate policies for each arm configuration, simplifying deployment and increasing the robot’s operational flexibility without requiring retraining for different task requirements.
Demonstrating Robust Generalization on Standard Benchmarks
A comprehensive evaluation of ABot-M0’s capabilities was conducted using established robotic manipulation benchmarks – LIBERO, LIBERO-Plus, Robotwin, and RoboCasa – to ensure a robust assessment of its performance. These datasets present a variety of challenges, ranging from simple object manipulation in LIBERO to more complex scenarios with increased clutter and object variety in RoboCasa. Rigorous testing across these standards allowed for a direct comparison with existing state-of-the-art methods, demonstrating ABot-M0’s ability to generalize across diverse robotic tasks and environments. The framework’s performance on these benchmarks highlights its potential for real-world deployment, offering a standardized means of measuring progress in robotic manipulation and facilitating further research in the field.
Rigorous testing demonstrates that the developed framework consistently surpasses the performance of existing robotic manipulation systems on established benchmarks. Specifically, the system achieved a remarkably high success rate of 98.6% when evaluated on the LIBERO dataset, indicating a strong ability to handle a wide range of object manipulations. Furthermore, the framework extended its superior performance to the more complex Robotwin 2.0 benchmark, achieving success rates exceeding 80%. These results highlight the system’s robust capabilities and potential for practical application in demanding robotic tasks, signifying a substantial advancement in the field of robotic manipulation.
Rigorous testing on the LIBERO-Plus benchmark reveals a substantial performance advantage for ABot-M0, exceeding the success rates of existing robotic manipulation frameworks by a margin of 12.6 to 64.9%. This translates to an overall success rate of 80.5% – a significant leap forward in complex object manipulation tasks. LIBERO-Plus presents a heightened challenge through increased object diversity and scene clutter, demanding more robust perception and planning capabilities. The framework’s marked improvement on this benchmark demonstrates its ability to generalize beyond simpler environments and handle the intricacies of real-world robotic applications with greater reliability and precision.
ABot-M0 demonstrates significant advancements in handling complex real-world scenarios, achieving a 58.3% success rate on the challenging RoboCasa GR1 Tabletop Tasks – a benchmark known for its variability and difficulty. Crucially, the framework also exhibits improved robustness to changes in camera perspective, evidenced by a 14% performance increase on the LIBERO-Plus Camera Viewpoint Perturbation task. This enhancement stems from ABot-M0’s implementation of multi-view 3D perception, allowing the system to effectively interpret and react to objects even when viewed from unfamiliar angles – a critical capability for robots operating in dynamic and unpredictable environments.
A significant advancement in robotic manipulation lies in the streamlining of agent training and deployment, achieved through a standardized dataset and a unified architecture. Prior approaches often suffered from fragmented data and bespoke systems, hindering scalability and generalizability. This framework, however, presents a cohesive platform where a single model can be trained on a curated, comprehensive dataset, eliminating the need for task-specific retraining. The resulting simplification not only reduces development time and computational resources but also facilitates rapid prototyping and deployment in diverse environments, fostering a more accessible pathway toward creating adaptable and intelligent robotic systems capable of handling a wider range of real-world challenges.
The development of ABot-M0 signifies a notable advancement in robotic intelligence through its capacity to directly translate diverse visual information into actionable commands. Unlike conventional systems requiring extensive pre-programming or intermediate steps, this framework learns directly from visual inputs, enabling it to anticipate and execute tasks in dynamic and previously unseen environments. This direct perception-to-action pathway allows for a substantial increase in adaptability, as the robot isn’t constrained by rigid, pre-defined parameters, but rather learns and refines its actions based on ongoing visual analysis. Consequently, the success of ABot-M0 suggests a future where robots can operate with greater autonomy and flexibility, readily adjusting to novel situations and complex tasks without requiring human intervention or extensive retraining – a crucial step toward truly intelligent and versatile robotic systems.
The pursuit of generalized robotic intelligence, as demonstrated by ABot-M0, echoes a fundamental principle of elegant design. The framework’s success isn’t merely about achieving state-of-the-art performance-it’s about the harmony created through data standardization and the innovative Action Manifold Learning. Yann LeCun aptly stated, “Simplicity is a key to intelligence.” This sentiment resonates deeply with the core idea of ABot-M0; by unifying diverse datasets and distilling complex robotic actions into a learnable manifold, the framework embodies a remarkable simplicity that belies its power. The elegance of this approach isn’t accidental; it’s a direct consequence of a profound understanding of the underlying principles governing robotic manipulation.
Beyond the Reach of Grasp
The elegance of ABot-M0 lies not simply in its performance, but in the implicit acknowledgment that robotic intelligence has, for too long, been burdened by a lack of common language. Unifying disparate datasets is a crucial step, yet standardization feels less like a solution and more like a temporary truce. The true test will be how readily this framework adapts to data not curated for its convenience-the messy, unpredictable reality of the world. Code structure is composition, not chaos; a beautiful system will reveal its limits through graceful degradation, not brittle failure.
Action Manifold Learning offers a promising path toward generalization, but the ‘manifold’ itself is a construct. The next generation of embodied agents must grapple with the inherent ambiguity of action – the infinite ways a task can be accomplished, and the subtle cues that distinguish competence from mere movement. The question isn’t whether a robot can mimic manipulation, but whether it can understand it, and extrapolate beyond the confines of its training.
Ultimately, the pursuit of general robotic intelligence is a quest for elegant representation. Beauty scales, clutter does not. The challenge ahead is to build systems that not only react to the world, but anticipate it, and reshape it with a clarity of purpose-a harmony of form and function that transcends mere imitation and approaches genuine understanding.
Original article: https://arxiv.org/pdf/2602.11236.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
2026-02-14 10:01