Author: Denis Avetisyan
Researchers have developed a new system enabling stable, long-duration control of humanoid robots through intuitive human guidance.
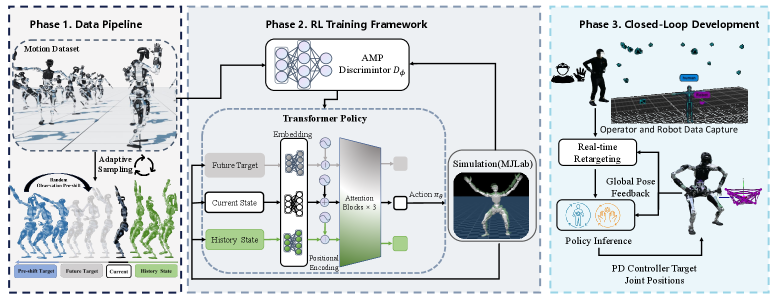
CLOT leverages data-driven randomization and Transformer networks to achieve robust, drift-free whole-body teleoperation and loco-manipulation.
Achieving stable, long-horizon control of full-sized humanoids remains a central challenge in robotics due to accumulating pose drift. This paper introduces CLOT: Closed-Loop Global Motion Tracking for Whole-Body Humanoid Teleoperation, a system that addresses this limitation through real-time, closed-loop global motion tracking. By combining high-frequency localization feedback with a data-driven randomization strategy and a Transformer-based policy, CLOT enables drift-free human-to-humanoid mimicry and robust loco-manipulation. Could this approach pave the way for more intuitive and reliable teleoperation of complex robots in real-world scenarios?
Breaking the Latency Barrier: The Pursuit of Real-Time Teleoperation
Traditional remote control systems, often reliant on visual or haptic feedback loops, frequently encounter significant challenges stemming from latency and instability. These issues arise from the inherent delays in transmitting control signals and receiving corresponding sensory information, particularly over long distances or with limited bandwidth. This delay disrupts the operator’s ability to make fine-grained adjustments, leading to jerky, imprecise movements and difficulty in maintaining stable control. The resulting instability isn’t merely a nuisance; it fundamentally limits the types of tasks a remotely operated system can reliably perform, hindering applications requiring delicate manipulation, such as surgical procedures or hazardous material handling. Consequently, substantial research focuses on minimizing these delays and improving the robustness of the control link to enable more effective and intuitive teleoperation.
Robust teleoperation hinges on the ability to rapidly and accurately perceive a remote environment and translate that understanding into precise control signals. This necessitates high-frequency feedback loops – receiving data on the robot’s state dozens, or even hundreds, of times per second – coupled with sophisticated pose estimation techniques. Accurate pose estimation, determining the robot’s exact position and orientation in three-dimensional space, is crucial because even minor inaccuracies accumulate rapidly, leading to instability and making delicate manipulation impossible. Systems relying on infrequent or imprecise data struggle to compensate for delays and disturbances, resulting in jerky movements and a disconnect between the operator’s intentions and the robot’s actions. Consequently, advancements in both sensor technology and computational algorithms for real-time data processing are paramount to achieving seamless and intuitive teleoperation experiences.
Existing teleoperation systems frequently struggle with the intricate coordination needed for full-body humanoid robots operating in real-world settings, often resulting in jerky movements or instability when faced with dynamic environments. This limitation hinders prolonged and effective remote control. However, a newly developed system demonstrates a significant advancement, achieving stable teleoperation of a humanoid robot for an extended duration of 30 minutes. This long-horizon control is made possible through innovations in feedback mechanisms and pose estimation, allowing for fluid and precise movements even as the robot navigates complex and changing surroundings. The resulting performance represents a crucial step towards practical applications of humanoid robots in remote or hazardous environments, where sustained and reliable operation is paramount.

Deconstructing Control: CLOT and the Architecture of Precise Humanoid Movement
CLOT achieves stable and accurate humanoid robot pose through the implementation of a closed-loop control system paired with high-frequency localization feedback. This architecture continuously monitors the robot’s state – position, velocity, and orientation – using external sensors, compares it to the desired pose, and calculates corrective actions. The high-frequency feedback loop, operating at rates exceeding typical robotic control systems, allows for rapid adjustments to counteract disturbances and maintain the desired pose with minimal error. This continuous monitoring and correction process is critical for dynamic movements and maintaining balance, especially in complex or unpredictable environments, and forms the foundation for precise robot control.
The CLOT system employs an Optical Motion Capture (OMC) system to concurrently monitor both human operator movement and the resultant robot state. This simultaneous tracking is achieved through the placement of reflective markers on both the human and the quadrupedal robot, allowing the OMC system to determine the precise 3D position and orientation of each marker. The resulting data streams – human motion intent and actual robot pose – are then integrated within the control loop, providing the necessary feedback for real-time pose correction and ensuring accurate tracking of the desired movements. This combined tracking methodology is critical for establishing the correspondence between human commands and robot execution, and forms the basis for CLOT’s precise control capabilities.
The Pinocchio Inverse Kinematics (IK) solver is utilized to map captured human motion data onto the Unitree G1 quadrupedal robot, facilitating a more intuitive control interface. This approach achieves a demonstrable improvement in positional accuracy, as evidenced by a significant reduction in Global Mean Body Position Error (Emgbp). Quantitative results indicate that the Pinocchio solver outperforms the TWIST2 IK solver on the Unitree G1 platform, demonstrating enhanced precision in robot pose control during motion retargeting. The reduction in [latex]Emgbp[/latex] directly correlates to a more faithful reproduction of human movements by the robot.

Data-Driven Adaptation: Sculpting Policies Through Randomization and Temporal Modeling
Observation Pre-shift is a data-driven technique employed to improve policy learning by randomizing the observed states independent of the reward function. This decoupling allows the agent to explore a broader range of possible states without directly associating them with immediate reward signals. By introducing this randomization, the policy implicitly learns to interpolate between observed states, effectively generating novel motions and improving its ability to generalize to unseen situations. The magnitude of the pre-shift randomization is determined through a data-driven process, optimizing for improved performance and stability during policy training.
The control policy utilizes a Transformer architecture to address the challenges of long-horizon temporal dependencies inherent in complex manipulation tasks. This architecture enables the model to process sequential observation data and capture relationships between states that are distantly separated in time. By employing self-attention mechanisms, the Transformer can weigh the importance of different time steps when predicting future actions, effectively modeling spatiotemporal information. This is crucial for tasks requiring planning and coordination over extended periods, as the policy can maintain a consistent understanding of the environment and the robot’s state even with delays between actions and observations. The Transformer’s ability to handle variable-length sequences also contributes to its robustness and adaptability within the simulation environment.
Proximal Policy Optimization (PPO) was implemented as the training algorithm for the control policy within the Mujoco physics engine. PPO is a policy gradient method that iteratively improves the policy by taking small steps to maximize reward, while simultaneously ensuring the new policy does not deviate too far from the previous policy – a constraint enforced via a clipped surrogate objective function. This approach prioritizes stable learning and prevents catastrophic policy updates, crucial for complex, continuous control tasks. Training within Mujoco, a high-performance physics engine, allowed for realistic simulation of robotic dynamics and accurate evaluation of policy performance, leading to maximized task completion and overall system stability.
Domain randomization was implemented to improve the policy’s ability to perform consistently across variations in simulated environments. This technique involves training the policy on a distribution of randomized parameters, including object masses, friction coefficients, and actuator delays. Evaluations demonstrate that this approach resulted in a higher Success Rate (SR) on desktop manipulation tasks compared to a Model Predictive Control (MPC) baseline; specifically, our system achieved improved task completion rates in environments with varied physical properties, indicating increased robustness and generalization capability.

The Illusion of Life: Adversarial Learning and the Pursuit of Natural Robotic Movement
The pursuit of natural movement in robotic systems has led to the development of Adversarial Motion Prior (AMP), a technique that leverages adversarial learning to instill human-like qualities into generated motions. Rather than explicitly programming desired movements, AMP trains a policy alongside a discriminator network; the policy attempts to generate realistic actions, while the discriminator learns to distinguish between robot-generated and human-performed motions. This creates a competitive dynamic, pushing the policy to refine its output and increasingly mimic the nuances of human movement. By regularizing the policy’s behavior through this adversarial process, AMP effectively shapes the robot’s actions, resulting in smoother, more believable, and ultimately more intuitive motions that enhance the realism of robotic interactions.
The learning process benefits significantly from a carefully constructed reward system that leverages the Adversarial Motion Prior. This reward shaping technique doesn’t simply reward reaching a goal, but actively assesses the quality of the movement itself. By incorporating feedback from the adversarial network – which is trained to distinguish between human and machine-generated motion – the system learns to favor trajectories that mimic natural human movement. Consequently, the control policy is incentivized to execute fluid, realistic actions, while simultaneously receiving penalties for jerky, unnatural, or physically implausible motions. This nuanced approach ensures that the resulting behaviors are not only effective in completing tasks, but also exhibit a level of biomechanical believability that enhances the overall experience and avoids the uncanny valley effect often seen in robotic control.
The culmination of this research delivers a control policy distinguished by its capacity to generate remarkably fluid and human-inspired movements, fundamentally enhancing the user experience in robotic applications. Beyond simply mimicking motion, the system exhibits exceptional stability, maintaining consistent performance without drifting or requiring recalibration over extended operational periods. Notably, demonstrations have achieved stable, drift-free teleoperation lasting up to 30 minutes – a significant advancement towards practical, long-horizon control, opening doors for intuitive and sustained interaction with robotic systems in real-world scenarios and minimizing the need for constant user intervention.

The pursuit of robust humanoid teleoperation, as demonstrated by CLOT, inherently demands a willingness to challenge established limitations. This research doesn’t simply accept existing motion tracking as sufficient; it actively seeks to overcome drift and instability through data-driven randomization and Transformer networks. This echoes Tim Berners-Lee’s sentiment: “The Web is more a social creation than a technical one.” While seemingly disparate, both concepts highlight the power of iterative refinement – the Web evolving through collective contribution, and CLOT improving through continual data adaptation and policy optimization. The system’s ability to achieve long-horizon loco-manipulation is not a result of adhering to pre-defined boundaries, but rather from intelligently testing and extending those boundaries, effectively reverse-engineering a more reliable and adaptable system.
Beyond the Loop
The presented system, while demonstrably effective at closing the loop on humanoid teleoperation, merely shifts the problem. Drift reduction isn’t elimination; it’s a clever re-framing of inevitable error accumulation. The reliance on data randomization, a pragmatic necessity, hints at an underlying fragility. How much can a policy, trained to generalize across synthetic perturbations, truly withstand the beautifully unpredictable chaos of the real world? Future work isn’t about refining the randomization-it’s about dismantling the need for it.
The architecture itself invites further dissection. Transformer networks, currently fashionable, offer a powerful inductive bias, but at what cost? Are they truly the optimal pathway to long-horizon control, or simply a conveniently scalable solution? The true challenge lies in discovering representations that are inherently robust to noise and uncertainty, representations that allow the system to anticipate drift rather than react to it.
Ultimately, this work reveals a fundamental truth: teleoperation isn’t about perfect control, it’s about graceful failure. The next iteration won’t seek to eliminate error, but to exploit it – to imbue the system with the capacity to recover from unexpected disturbances, not through pre-programmed responses, but through genuine, embodied intelligence. The goal isn’t to command a robot, but to cultivate a partner.
Original article: https://arxiv.org/pdf/2602.15060.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Total Football free codes and how to redeem them (March 2026)
- Brawl Stars Brawl Cup Pro Pass arrives with the Dragon Crow skin and Chroma, unique cosmetics, and more rewards
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
2026-02-18 23:16