Author: Denis Avetisyan
A new framework prioritizes tactile feedback to help robots master complex, contact-rich manipulation tasks.
![Across five manipulation tasks, a curriculum informed by force feedback-specifically, the CRAFT enhancement to both [latex]\pi_0[/latex]-base and RDT models-consistently elevates task success rates, with particularly pronounced improvements observed in scenarios demanding substantial physical contact, thus demonstrating the efficacy of force-aware fine-tuning.](https://arxiv.org/html/2602.12532v1/x4.png)
CRAFT adapts Vision-Language-Action models with force-aware curriculum learning for robust robot manipulation.
While recent advances in Vision-Language-Action (VLA) models have enabled robots to follow general instructions, they struggle with the precision and stability required for contact-rich manipulation tasks. This work introduces ‘CRAFT: Adapting VLA Models to Contact-rich Manipulation via Force-aware Curriculum Fine-tuning’, a framework that addresses this limitation by prioritizing force feedback during learning and effectively integrating it with visual and linguistic data via a variational information bottleneck and curriculum strategy. Experimental results demonstrate that CRAFT consistently improves task success, generalizes to new objects, and adapts across diverse VLA architectures. Could this approach unlock more robust and adaptable robotic manipulation capabilities in complex, real-world scenarios?
The Evolving Landscape of Robotic Control
Contemporary robotics is rapidly eclipsing the limitations of conventional control systems, driven by the need for greater adaptability and intelligence in unstructured environments. Historically, robots relied on precisely programmed sequences for specific tasks, proving brittle when faced with even slight variations. However, the field now necessitates models capable of seamlessly integrating perceptual input – what the robot sees – with subsequent action. This shift demands a move beyond pre-defined behaviors, towards systems that can interpret complex scenarios, reason about desired outcomes, and dynamically generate appropriate responses. Consequently, research is increasingly focused on architectures that bridge the gap between sensing the world and effectively interacting with it, paving the way for robots capable of true autonomy and robust performance in real-world applications.
Current robotics research increasingly leverages the power of pre-trained Vision-Language Models and Large Language Models, recognizing their potential to imbue robots with sophisticated understanding and reasoning capabilities. However, simply possessing linguistic and visual comprehension is insufficient for effective action; these models excel at describing the world, but struggle to actively change it. A crucial challenge, therefore, lies in bridging this gap – integrating these powerful models into a cohesive framework that translates high-level instructions and perceived environmental information into concrete, executable robot movements. This integration demands novel architectures and training strategies capable of grounding language and vision not just in understanding, but in the physics and dynamics of robotic manipulation and locomotion, ultimately allowing robots to reliably perform complex tasks in real-world settings.
The Vision-Language-Action (VLA) paradigm represents a significant step towards more intuitive and versatile robotic systems. Rather than requiring precise, low-level instructions, this approach enables robots to interpret high-level goals expressed in natural language – for example, “bring me the red block” or “clean up the table.” This is achieved by integrating advances in computer vision, natural language processing, and robotics control into a unified framework. The system first processes visual input to understand the environment, then decodes the linguistic command to determine the desired outcome, and finally translates this understanding into a sequence of executable actions. This capability promises to dramatically simplify human-robot interaction and unlock applications requiring greater adaptability and autonomy, moving beyond pre-programmed tasks to address dynamically changing situations.
Zero-Shot Generalization: An Emergent Property of Scaled Models
Vision-Language Action (VLA) models, including RT-1, RT-2, SayCan, and OpenVLA, exhibit zero-shot transfer capabilities by leveraging large-scale pretraining on multimodal datasets. This allows these models to generalize to new objects and environments without requiring task-specific training data. The core principle involves associating visual inputs with language instructions, enabling the robot to interpret and execute commands for previously unseen scenarios. Performance is evaluated by assessing the robot’s ability to successfully complete tasks defined through natural language, demonstrating a significant advancement in robotic adaptability and reducing the need for extensive, customized training procedures.
Recent advancements in robotic control, specifically the RDT and π0 (Pi-Zero) models, integrate large-scale multimodal pretraining directly with robot control mechanisms. This unification bypasses the traditional need for separate perception, planning, and control pipelines. RDT and π0 are pretrained on extensive datasets of images, language, and robot states, enabling them to map visual inputs and natural language instructions directly to low-level robot actions. The models achieve this by formulating robot control as a sequence modeling problem, predicting future robot states and actions based on observed inputs and specified goals, thereby allowing for generalization to new tasks and environments without task-specific fine-tuning.
The capacity of RT-1, RT-2, SayCan, OpenVLA, RDT, and π0 to execute robotic tasks without requiring task-specific training data represents a substantial advancement in robotics. Traditionally, robot deployments necessitate extensive data collection and model training for each new skill or environment. These Vision-Language-Action (VLA) models, however, leverage large-scale pretraining on multimodal datasets to generalize to unseen tasks described through natural language instructions. This zero-shot capability significantly reduces the time, cost, and complexity associated with robot deployment, allowing for increased adaptability and broader application in dynamic, real-world scenarios. The models achieve this by associating visual inputs with language prompts and then translating those prompts into robotic actions, effectively bridging the gap between human instruction and robot execution without explicit examples for each task.
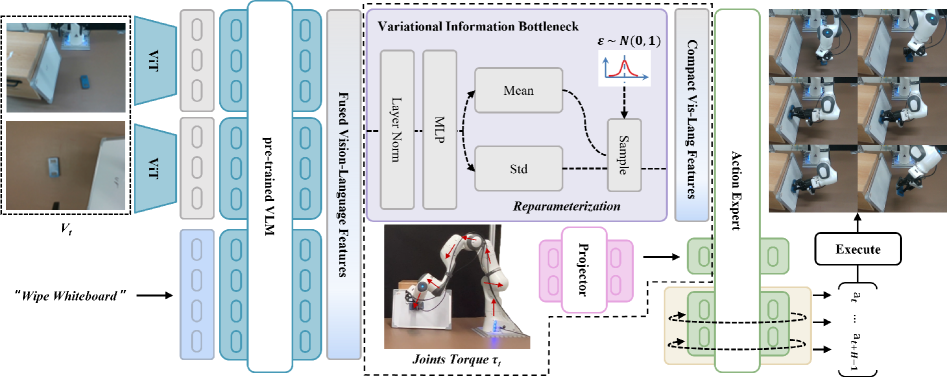
CRAFT: A Principled Approach to Contact-Rich Manipulation
Conventional Visually-guided Learning Approaches (VLAs) often struggle with contact-rich manipulation due to the high dimensionality and noise inherent in force and tactile data. CRAFT addresses these limitations by integrating a Variational Information Bottleneck (VIB) into the learning framework. The VIB functions as a learned compression mechanism, specifically designed to prioritize lower-entropy force inputs while discarding irrelevant information. This selective filtering of sensory data reduces the impact of noise and allows the robot to focus on the most salient force signals necessary for successful manipulation, ultimately improving robustness and performance in complex contact-rich scenarios.
The CRAFT framework leverages the principle of minimizing entropy in force inputs to facilitate robotic manipulation, particularly in scenarios with limited visual data. This is achieved by prioritizing force sensor readings that exhibit low variability – indicating predictable contact interactions – during the learning process. By focusing on these low-entropy force signals, the robot can more effectively infer object properties and refine its actions even with incomplete or noisy visual information. This approach allows the system to learn manipulation skills by emphasizing tactile feedback and reducing reliance on potentially unreliable visual cues, ultimately improving robustness and adaptability in complex contact-rich environments.
Integration of the CRAFT framework with the π0 model resulted in a mean improvement of 35.36% in task success rates when evaluated across five distinct contact-rich manipulation tasks. These tasks were specifically designed to assess a robot’s ability to perform complex manipulations requiring significant physical interaction with objects in the environment. The π0 model provides a prior distribution over task parameters, which constrains the learning process and improves generalization, particularly in scenarios with limited data. This performance increase, measured by the percentage of successfully completed trials, demonstrates a statistically significant advancement in robotic manipulation capabilities when utilizing the combined CRAFT and π0 approach.
Curriculum Fine-Tuning in CRAFT operates by initially prioritizing force inputs during the early stages of training, effectively leveraging the robot’s proprioceptive sense for initial skill acquisition. Subsequently, the influence of visual and language information is incrementally increased over the course of training. This staged approach allows the model to first establish a robust foundation based on contact forces, and then refine its performance by incorporating higher-level sensory inputs. The gradual increase in reliance on visual and language data mitigates the challenges associated with noisy or ambiguous sensory information, leading to improved generalization and overall task success rates in contact-rich manipulation scenarios.
![CRAFT enhances robotic manipulation by leveraging force feedback to adapt motions and successfully complete tasks like USB insertion and carton flipping, unlike [latex]\pi_0[/latex]-base methods.](https://arxiv.org/html/2602.12532v1/x5.png)
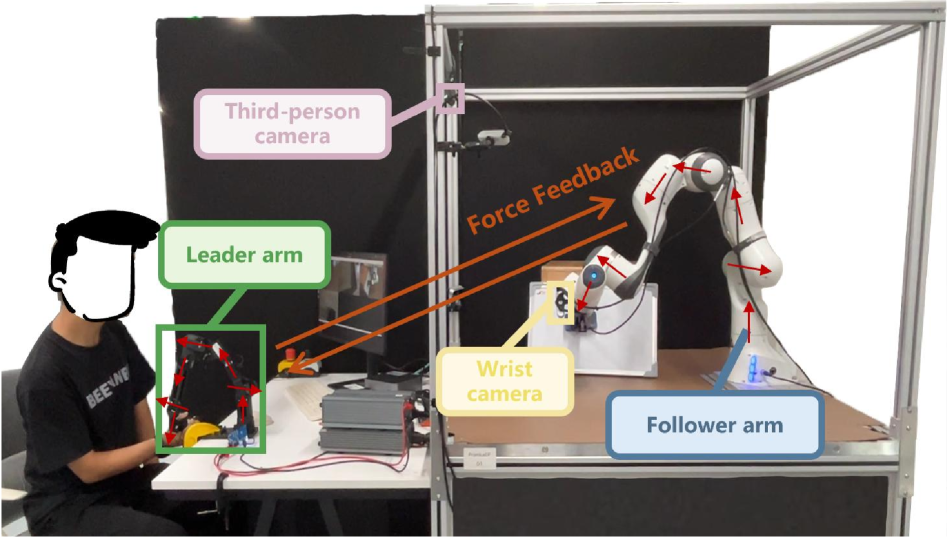
Demonstrating Robustness: Validation on Complex Manipulation Tasks
The robotic system, known as CRAFT, proves its capabilities by successfully completing a diverse set of physically demanding tasks that require intricate contact and manipulation skills. These include seemingly simple, yet technically challenging actions such as inserting a USB drive, flipping a cardboard carton, wiping a whiteboard, rolling plasticine into a desired shape, and precisely aligning a shaft into a hole. Each task demands not only accurate movements, but also the ability to adapt to varying levels of resistance and maintain stable contact-highlighting CRAFT’s proficiency in real-world, contact-rich scenarios where even minor deviations can lead to failure. The successful execution of these benchmarks demonstrates a significant step towards more versatile and reliable robotic manipulation systems capable of functioning effectively in unstructured environments.
The challenge of reliably wiping a whiteboard presented a significant hurdle for robotic manipulation systems, initially achieving a mere 22.66% success rate. However, integrating the CRAFT framework with Reinforcement Learning with Diffusion Transformers (RDT) dramatically improved performance. This synergistic approach allowed the robot to learn a more nuanced understanding of the contact dynamics involved in the task, enabling it to consistently apply the appropriate force and motion to effectively clean the whiteboard surface. The result was a substantial increase in task success, reaching 58.3%, and demonstrating the power of combining learned policies with a robust contact-aware framework for real-world manipulation challenges.
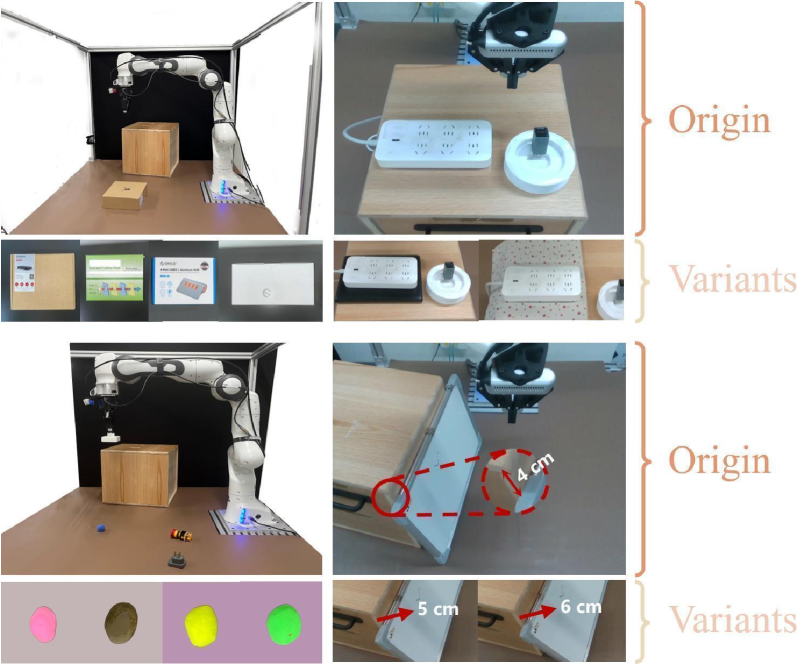
The capacity of the CRAFT framework to generalize beyond its training data is demonstrably strong, as evidenced by a 36.25% average improvement in task success rates when tested on out-of-distribution (OOD) variants. This robust generalization stems from the integration of the π0 model, which enables the robot to effectively adapt to novel situations and unforeseen circumstances. By successfully navigating OOD scenarios – representing variations in object pose, lighting, or even minor physical properties – CRAFT proves its potential for real-world deployment where environmental conditions are rarely identical to those encountered during training. This adaptability signifies a significant step toward creating robotic systems capable of reliably performing complex manipulation tasks in unstructured and unpredictable environments.
The ability of a robotic system to reliably perform everyday manipulation tasks remains a significant challenge, particularly when faced with novel situations. Recent work demonstrates a substantial improvement in the success rate of USB insertion – a task demanding precise alignment and force control – through the implementation of CRAFT. In out-of-distribution testing, where the robot encountered previously unseen variations in the task environment, CRAFT elevated the success rate from a mere 10% to a noteworthy 40%. This fourfold increase highlights the system’s capacity to generalize learned skills, suggesting a robust approach to handling the inherent uncertainties of real-world manipulation and paving the way for more adaptable robotic systems.
Successful completion of tasks like USB insertion, whiteboard wiping, and plasticine rolling hinges on a robot’s ability to modulate applied forces and respond to unpredictable contact dynamics. The demonstrated performance underscores the advantages of the Variational Imitation and Belief (VIB) framework, which enables robust policy learning under uncertainty, and curriculum learning, which strategically increases task complexity. By initially mastering simpler scenarios and gradually progressing to more challenging ones, the system develops the necessary fine motor skills and adaptive behaviors for complex manipulation. This approach facilitates the acquisition of precise force control, allowing the robot to overcome variations in object pose, surface friction, and unexpected disturbances – ultimately leading to significant improvements in task success rates even when faced with previously unseen conditions.

Towards Increasingly Versatile Robotic Systems
Recent advancements suggest a powerful synergy between Deep Variational Information Bottleneck (VIB) and techniques like Flow Matching for bolstering the capabilities of Visual Language-Action (VLA) models. VIB, a machine learning framework focused on learning efficient representations by discarding irrelevant information, when combined with Flow Matching-a probabilistic modeling approach capable of generating complex data distributions-allows robots to learn more robustly from limited data. This integration addresses a critical challenge in robotics: the need for models that can generalize effectively to unseen scenarios and recover gracefully from noisy or incomplete sensory inputs. By encouraging the learning of compact, informative representations and facilitating the generation of plausible action sequences, these techniques promise to significantly enhance the efficiency and reliability of robotic systems operating in complex, real-world environments, ultimately paving the way for more versatile and adaptable machines.
Advancements in robotic adaptability and performance are increasingly reliant on mimicking the way humans learn and interact with their environment. Researchers are focusing on curriculum learning, a technique that structures learning tasks from simple to complex, allowing robots to build foundational skills before tackling more challenging scenarios. Complementing this is the integration of tactile feedback – equipping robots with ‘sensitive touch’ – enabling them to understand material properties, grasp objects securely, and adjust to unforeseen circumstances. By combining these approaches, robots can move beyond pre-programmed routines and develop a more nuanced understanding of the physical world, ultimately leading to greater versatility and resilience in dynamic, real-world applications.
The culmination of this research suggests a pathway towards robots exhibiting a new level of physical competency. These machines are envisioned not simply as automated tools, but as agents capable of genuine interaction with, and understanding of, their surroundings. By developing models that prioritize efficient learning and adaptable control, the groundwork is being laid for robots that can reliably manipulate objects, navigate complex environments, and perform intricate tasks with a human-like dexterity. This isn’t merely about automating existing processes; it’s about creating robotic systems that can generalize learned skills to novel situations, ultimately enabling them to contribute meaningfully to a wide range of real-world applications, from advanced manufacturing and healthcare to disaster response and exploration.
The pursuit of robust robotic manipulation, as demonstrated by CRAFT, echoes a fundamental tenet of mathematical rigor. The framework’s emphasis on force-aware curriculum fine-tuning, prioritizing tactile feedback alongside visual and linguistic data, aligns with the demand for provable solutions, not merely functional ones. As David Hilbert famously stated, “We must be able to answer the question: what are the fundamental principles that govern the behavior of systems?” CRAFT, in its methodical integration of multimodal information and prioritization of force, strives to establish those principles for contact-rich manipulation, moving beyond empirical success toward a more mathematically grounded approach to robotic control. The VLA model’s adaptation, driven by demonstrable forces, isn’t simply about making the robot work, but understanding why it works.
What’s Next?
The pursuit of robust robotic manipulation, as exemplified by CRAFT, continually reveals the fragility of purely data-driven approaches. Prioritizing force information represents a logical step – contact is reality for a manipulator – but it does not resolve the fundamental issue of generalization. The framework, while demonstrably improving performance within defined curricula, still relies on exposure to a sufficiently diverse set of conditions. A truly elegant solution would not require such exhaustive training; it would deduce appropriate actions from first principles, informed by a concise, provable model of physics and contact mechanics.
Future work must address the limitations inherent in variational information bottlenecks. While useful for dimensionality reduction, these methods introduce approximation errors. The question remains: how much information can be discarded without sacrificing the deterministic reproducibility necessary for reliable operation? If a system cannot consistently replicate a manipulation sequence, its practical utility diminishes rapidly. The focus should shift from simply learning policies to verifying their correctness – establishing guarantees, not merely observing empirical success.
Ultimately, the field requires a more formal treatment of uncertainty. Current approaches often treat noise as a nuisance to be filtered, rather than an intrinsic property of the physical world. A truly intelligent system would not only react to disturbances but anticipate them, and its actions would be demonstrably robust to unmodeled variations. The path forward lies not in more data, but in more rigorous mathematical foundations.
Original article: https://arxiv.org/pdf/2602.12532.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- The most surprising Hannah Montana cameos: From John Cena to Dwayne Johnson and even a Coronation Street soap star as show celebrates its 20th anniversary
- Charlie Day Confirms What Always Sunny Scene Is His Career Highlight
2026-02-16 17:44