Author: Denis Avetisyan
Researchers have developed a novel imitation learning framework that allows robots to learn complex manipulation skills by separating trajectory planning from real-time force control.
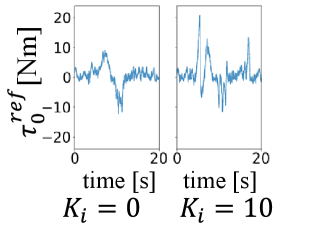
This work introduces a hierarchical model combining memory-based trajectory prediction with PID-based force control for improved robot manipulation in contact-rich tasks.
While obtaining position trajectories for robot manipulation is often straightforward, defining appropriate force commands remains a significant challenge. This is addressed in ‘Force Generative Imitation Learning: Bridging Position Trajectory and Force Commands through Control Technique’, which proposes a hierarchical framework that generates force commands from position trajectories using a memoryless model integrated with Proportional-Integral-Derivative (PID) feedback control. This approach overcomes limitations in generalizing to unseen trajectories and enables stable force control, particularly in contact-rich tasks like writing. Could this decoupling of trajectory prediction and feedback control represent a broader pathway toward more robust and adaptable robot manipulation skills?
The Inevitable Friction of Reality
Conventional robot learning methodologies frequently encounter difficulties when deployed in real-world settings characterized by unpredictable change. These systems, often trained on static datasets or within simplified environments, exhibit diminished performance when faced with even subtle alterations to their surroundings. A slight shift in lighting, the introduction of a novel object, or a minor adjustment to the robot’s position can necessitate a complete retraining process, proving both time-consuming and computationally expensive. This sensitivity stems from the reliance on precisely calibrated models and the inability to generalize learned behaviors beyond the specific conditions encountered during training – a significant limitation for robots intended to operate autonomously in the inherently variable human world. Consequently, the pursuit of more robust and adaptable learning paradigms remains a central challenge in the field of robotics.
A persistent challenge in robotics lies in the difficulty of transferring skills acquired in simulated environments to the complexities of the real world – a phenomenon known as the ‘sim-to-real’ gap. This disconnect arises from inherent discrepancies between the idealized conditions of simulation and the unpredictable nature of physical reality. Variations in sensor noise, friction coefficients, actuator performance, and even subtle lighting changes can dramatically alter a robot’s perception and execution of learned behaviors. Consequently, a policy successfully trained in simulation often exhibits diminished performance, or even complete failure, when deployed on a physical robot. Researchers are actively exploring techniques like domain randomization – intentionally varying simulation parameters – and domain adaptation – refining simulated data to more closely resemble real-world observations – to mitigate these discrepancies and enable more robust skill transfer, ultimately reducing the need for costly and time-consuming real-world training.
Conventional robot control systems typically employ a monolithic architecture, where all functionalities are integrated into a single, complex unit. While seemingly efficient, this approach significantly hinders adaptability when confronted with novel or unpredictable scenarios. A failure in one component can cascade through the entire system, halting operation, and the rigid structure makes it difficult to isolate and correct errors quickly. Moreover, modifying or upgrading a single aspect of the control system often necessitates a complete overhaul, proving both time-consuming and resource-intensive. Researchers are now exploring more modular and distributed control architectures – inspired by biological nervous systems – to enable robots to learn, adapt, and recover from disturbances with greater resilience and efficiency, mirroring the flexibility observed in natural systems.
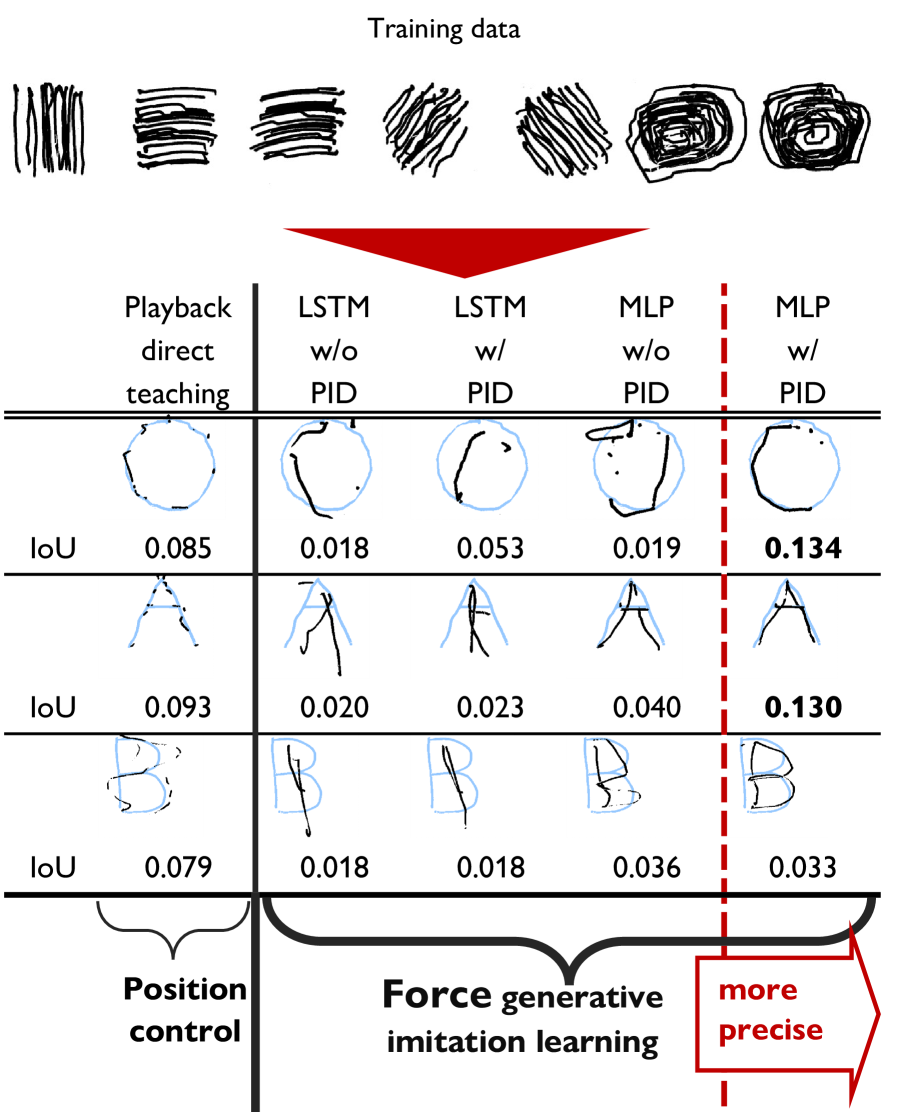
Hierarchical Control: A Necessary Decomposition
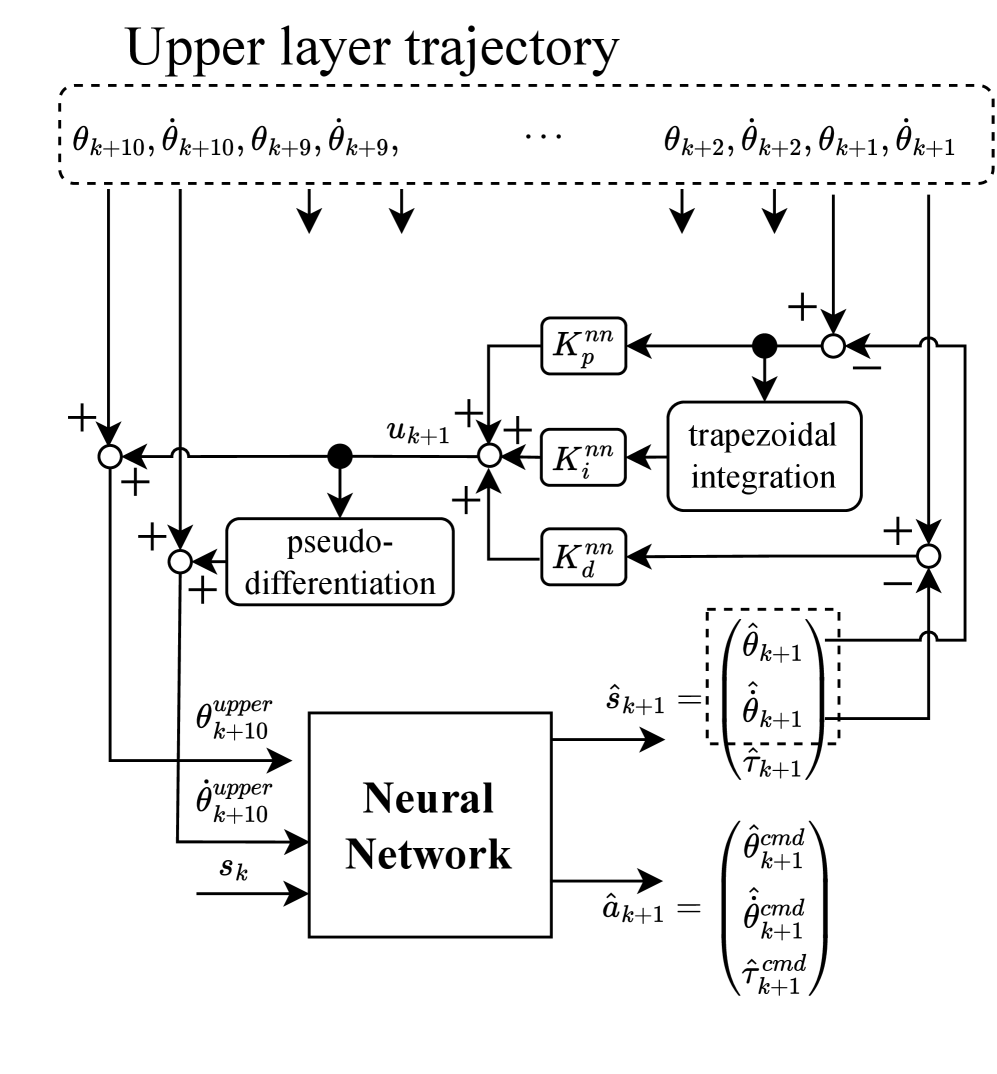
The Force Generative Imitation Learning framework employs a hierarchical model consisting of distinct layers for planning and control. This decoupling allows the system to separate the determination of overall task objectives – the ‘what’ – from the precise execution of motor commands – the ‘how’. The upper layer handles high-level trajectory generation, while the lower layer focuses on low-level force control. This architecture improves robustness by isolating potential errors; inaccuracies in high-level planning do not necessarily propagate to unstable low-level control, and vice-versa. Adaptability is increased as changes to the high-level planner do not require retraining of the low-level control policy, and conversely, improvements to low-level force control generalize across different planned trajectories.
The upper-layer trajectory generation process within the framework utilizes a memory-based layer to access and incorporate previously observed successful trajectories. This mechanism allows the system to implicitly learn from past experiences without requiring explicit reward signals or pre-defined error metrics. By referencing similar situations encountered during training, the system improves its ability to predict optimal actions in novel scenarios. The utilization of historical data effectively provides a form of contextual feedback, increasing the accuracy of trajectory prediction and resulting in more robust and adaptable robot behavior. The memory-based layer stores a repository of past state-action pairs, enabling the system to retrieve and adapt relevant trajectories based on current state similarity.
The Force Generative Imitation Learning framework distinguishes between trajectory planning and execution through a hierarchical structure. The upper layer defines the desired task – what needs to be accomplished – while the lower layer, a memoryless model, is responsible for the precise motor control required to achieve that task – how it is accomplished. This separation allows the upper layer to focus on high-level strategic decisions without being burdened by the complexities of low-level control. The lower layer, unencumbered by long-term dependencies, can react quickly and accurately to immediate conditions, providing the necessary precision for successful task completion. This decoupling improves both the adaptability and robustness of the robot’s behavior.
Empirical Validation: Grounding Theory in Practice
Direct Teaching is employed as a primary data acquisition method for the imitation learning pipeline. This technique involves an expert operator directly controlling the robot to perform the desired task, with the robot recording the operator’s actions – including kinematic trajectories and applied forces – as demonstrations. These demonstrations constitute the initial training dataset, enabling the imitation learning algorithm to learn the mapping from states to actions. The efficiency of Direct Teaching stems from its ability to rapidly generate a substantial and representative dataset without requiring complex reward function engineering or reinforcement learning procedures. The recorded data is then processed and formatted for use in training the imitation learning model, effectively transferring expert knowledge to the robotic system.
Bilateral control enables the transmission of force and tactile information from the environment back to the operator, effectively allowing the human to ‘feel’ the interactions between the robot and its surroundings. This is achieved through the use of force sensors integrated into the robot’s end-effector, which measure reaction forces during contact. These measured forces are then mapped and relayed to the operator, typically through a haptic device. This feedback loop is crucial for collecting data necessary to train robots in complex force-based skills, such as assembly, polishing, or surgical procedures, where precise force application and adaptation to varying environmental conditions are essential. The method allows for intuitive demonstration of skills requiring nuanced force control, which is then used as training data for imitation learning algorithms.
The Character Writing Task serves as the primary validation method for the framework due to its inherent complexity and demand for both positional accuracy and adaptive control. This task requires the robotic system to reproduce a series of pre-defined characters, introducing challenges related to varying stroke orders, pen pressure, and surface conditions. Successful completion necessitates precise trajectory planning and real-time adjustment to maintain consistent character formation, effectively testing the system’s ability to generalize learned skills to nuanced and unpredictable scenarios. The task’s difficulty lies not only in achieving accurate shapes but also in consistently replicating them across multiple attempts and under varying external disturbances.
Performance evaluation relies on the metric Intersection over Union (IoU), which calculates the ratio of area where the predicted character shape overlaps with the ground truth, providing a quantifiable measure of accuracy. Specifically, IoU is computed as the area of intersection divided by the area of union of the predicted and actual shapes. Higher IoU values indicate greater accuracy; the models tested within this framework consistently achieved the highest IoU values compared to alternative approaches, demonstrating superior performance in the character writing task. [latex] IoU = \frac{Area_{intersection}}{Area_{union}} [/latex]
Towards Robust Autonomy: Embracing Systemic Complexity
The increasing demand for robotic systems operating beyond controlled settings necessitates a shift towards more adaptive and robust intelligence. Current robotic deployments often struggle with the unpredictable nature of unstructured environments – spaces lacking pre-defined maps or consistent conditions. This research introduces a framework designed to overcome these limitations, enabling robots to navigate and perform tasks reliably even when faced with unforeseen obstacles or changes. By prioritizing adaptability, the system aims to move beyond rigid, pre-programmed behaviors, allowing for real-time adjustments and improved performance in dynamic, real-world scenarios. This represents a crucial step towards deploying robots in complex environments such as disaster relief, agricultural settings, and even domestic assistance, where flexibility and resilience are paramount.
A core innovation within the proposed robotic intelligence framework lies in its implementation of the Time-Scale Separation principle, a technique borrowed from control theory. This principle structures the robot’s hierarchical model by assigning distinct operational speeds to different layers – slow for planning and high-level decision-making, and fast for low-level motor control. By operating these layers at vastly different speeds, the system effectively minimizes interference between them, preventing rapid planning adjustments from destabilizing precise motor actions, and conversely, ensuring quick reactions don’t overwhelm the planning process. This decoupling fosters a more stable and predictable system, allowing the robot to execute complex tasks with greater reliability and precision, especially in dynamic and unpredictable environments where quick, coordinated responses are paramount. The result is improved overall performance and a substantial reduction in the computational burden required for robust operation.
A key advancement lies in the system’s ability to separate the high-level task of planning from the low-level execution of control; this decoupling dramatically improves a robot’s adaptability. Traditionally, robots require significant re-programming when faced with even minor environmental changes or new tasks, as both planning and control are intertwined. However, by treating these as distinct modules, the system allows for the reuse of learned control skills across a variety of plans. This means a robot proficient in grasping an object can readily apply that skill to a new task involving grasping, even in unfamiliar settings, without requiring extensive retraining. The result is a more versatile and efficient robotic system capable of operating reliably in dynamic and unpredictable environments, fostering true autonomy and reducing the burden of constant re-calibration.
The system’s performance relies on a sophisticated optimization process, employing the Adam optimizer to minimize a specifically designed loss function. This minimization isn’t merely about achieving accuracy; it directly translates to optimal performance and precise trajectory prediction using the generated Variable-Lattice Approximation (VLA) models. Rigorous testing demonstrates that this optimized, model-based approach achieves performance levels comparable to traditional rule-based feedback control systems, but with the added benefit of adaptability and learning capabilities. The VLA models, refined through this process, effectively capture the dynamics of complex movements, allowing the robot to navigate and interact with its environment with increased efficiency and robustness – a significant step towards truly intelligent robotic systems.
The pursuit of seamless robotic manipulation, as detailed in this work, echoes a fundamental tenet of complex systems: prophecy is inherent in design. Every choice regarding the hierarchical model, the separation of trajectory prediction and feedback control, prefigures potential limitations and necessary adaptations. Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment applies equally to the iterative refinement of such systems; one doesn’t build a perfect manipulator, but rather cultivates one through continuous learning and adjustment, acknowledging that the initial design is merely a starting point. The framework, by isolating trajectory from force commands, doesn’t eliminate failure, it prepares for it – anticipating the inevitable discord between prediction and reality, and establishing a responsive lower layer to mitigate the consequences.
What Lies Ahead?
This work, while demonstrating a functional partitioning of trajectory and force control, merely postpones the inevitable encounter with complexity. The separation itself is not a solution, but a refinement of the problem. Systems built on hierarchical models inevitably reveal the brittleness inherent in any attempt to impose structure on a fundamentally chaotic process. The fidelity of the predicted trajectory, however impressive, is ultimately a transient illusion, susceptible to the slightest perturbation in a contact-rich environment.
Future efforts will likely focus on embracing, rather than suppressing, this inherent instability. A guarantee of successful manipulation is, after all, just a contract with probability. The true challenge lies not in predicting the ideal path, but in constructing a system capable of gracefully recovering from inevitable deviations. Stability is merely an illusion that caches well. The field may well shift from predictive architectures to reactive ones, focusing on real-time adaptation and the exploitation of contact dynamics, accepting that chaos isn’t failure-it’s nature’s syntax.
Further research should explore the limitations of PID control within this framework. While adequate for initial demonstration, its reliance on fixed parameters will undoubtedly prove insufficient for truly robust, adaptive manipulation. The eventual convergence may not be toward precise replication of demonstrated skill, but toward a statistically plausible range of acceptable outcomes – a pragmatic acceptance of imperfection as the defining characteristic of embodied intelligence.
Original article: https://arxiv.org/pdf/2602.06620.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- Magicmon: World redeem codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Hatch Dragons Beginners Guide and Tips
2026-02-10 06:43