Author: Denis Avetisyan
Researchers are leveraging augmented reality and advanced learning techniques to dramatically improve how robots learn complex manipulation skills.

A novel reinforcement learning framework combining imitation, contrastive learning, and AR-based teleoperation enables scalable and robust sim-to-real transfer for dexterous robotic tasks.
Despite advances in robotic manipulation, efficiently training dexterous robots to perform complex tasks remains a significant challenge. This paper, ‘Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions’, introduces a novel reinforcement learning framework that leverages augmented reality-based teleoperation for scalable data collection and combines imitation learning with contrastive learning to accelerate and stabilize policy optimization. The proposed method demonstrably improves both the speed and success rate of manipulation tasks in both simulated and real-world environments compared to established algorithms. Could this approach pave the way for more intuitive and robust human-robot collaboration in complex, real-world scenarios?
The Inevitable Rise of Adaptive Machines
The evolution of robotics has reached a point where simple, pre-programmed sequences are insufficient for many real-world applications. Contemporary tasks – from surgical procedures to in-home assistance and complex manufacturing – require dexterity and adaptability far exceeding the capabilities of traditionally coded robots. These demands stem from the inherent unpredictability of physical environments and the need for robots to interact with a diverse range of objects, often requiring nuanced force control and precise movements. Consequently, researchers are now focused on developing robotic systems capable of learning and refining their manipulation skills through experience, effectively surpassing the limitations of static, pre-defined routines and paving the way for genuinely versatile robotic assistants.
Traditional robotic control relies on meticulously programmed instructions for every conceivable action, a system inherently brittle when faced with the unpredictable nature of real-world scenarios. However, a shift towards experiential learning is redefining robotic capabilities. Contemporary algorithms now allow robots to improve performance through repeated trials, much like biological organisms. By analyzing the outcomes of their actions – successes and failures – these systems refine internal models and optimize behavior without explicit reprogramming. This approach, often leveraging techniques like reinforcement learning and imitation learning, enables robots to master complex manipulation tasks, navigate dynamic environments, and even generalize learned skills to novel situations, marking a significant departure from the limitations of pre-defined routines and paving the way for truly adaptable machines.
The true test of robotic intelligence isn’t performance in controlled settings, but rather the ability to navigate and function within unpredictable environments and tackle entirely novel tasks. Current robotic systems often struggle when confronted with situations deviating even slightly from their programmed parameters. This limitation stems from a reliance on pre-defined routines and an inability to generalize learned behaviors. Researchers are actively developing algorithms that allow robots to build internal models of their surroundings, predict outcomes, and adjust strategies in real-time. This necessitates advancements in areas like sensor fusion, robust perception, and reinforcement learning, ultimately aiming to create machines capable of autonomous problem-solving and seamless adaptation – essential traits for deployment in dynamic, real-world scenarios like disaster relief, space exploration, and even everyday domestic assistance.
The development of truly intelligent robotics hinges on equipping machines with robust perception and learning capabilities. Beyond simply executing pre-programmed instructions, these robots must accurately interpret sensory data – vision, touch, and sound – to build a comprehensive understanding of their surroundings. This perceived information then fuels sophisticated learning algorithms, allowing the robot to adapt to new situations, generalize from past experiences, and even anticipate future events. Such systems move beyond reactive behavior, enabling robots to not only respond to change but proactively adjust strategies and refine performance. Ultimately, this integration of perception and learning isn’t merely about improving robotic functionality; it’s about creating machines capable of genuine autonomy and intelligent problem-solving, mirroring-and potentially exceeding-human cognitive abilities in specialized domains.
Mimicking Expertise: The Path to Skill Acquisition
Imitation learning enables robots to learn complex skills without explicit programming by leveraging demonstrations from an expert, typically a human operator. This paradigm shifts the focus from reward function design – a significant challenge in reinforcement learning – to data collection, where the robot observes and records the expert’s actions in various states. The robot then utilizes this dataset to train a policy that maps states to actions, effectively mimicking the demonstrated behavior. This approach is particularly valuable in scenarios where defining a precise reward function is difficult or impossible, but obtaining example trajectories is feasible. The resulting policy aims to reproduce the expert’s performance, allowing the robot to execute the task as demonstrated, and forms the foundation for more advanced learning techniques.
Behavior Cloning functions as a supervised learning technique wherein a robot learns to map observations directly to actions demonstrated by an expert. This is typically achieved by training a model – often a neural network – on a dataset of state-action pairs recorded during expert demonstrations. The trained model then predicts the action the expert would take given a particular observed state. Its simplicity makes it an effective initial approach to skill acquisition, requiring only a dataset of successful demonstrations and a suitable model architecture; however, it’s important to note that the robot’s performance is limited by the quality and diversity of the training data and can be susceptible to errors when encountering states outside of the demonstrated distribution.
Naive behavior cloning, while conceptually simple, is susceptible to compounding errors arising from distribution shift. This occurs because the robot is trained on a dataset of state-action pairs generated by the expert demonstrator. During deployment, the robot operates in a state space influenced by its own actions, which inevitably diverge from the training distribution. Consequently, the robot encounters states it has not seen during training, leading to unpredictable and increasingly inaccurate actions. These errors accumulate over time as the robot’s trajectory drifts further from the expert’s, resulting in performance degradation and potential instability; the model essentially extrapolates beyond its learned experience, amplifying even minor initial discrepancies.
The Revision and Prediction (RP) method addresses the distribution shift problem in imitation learning by augmenting standard behavior cloning with an iterative refinement process. RP operates by training a policy to not only predict the expert’s actions, but also to predict the next state resulting from those actions. A discrepancy between the predicted next state and the actually observed next state is then used as a revision signal, effectively creating an augmented loss function. This revision component penalizes the policy for predicting actions that lead to states inconsistent with the expert demonstrations, reducing the accumulation of errors and improving policy stability, particularly when generalizing to unseen states. The method iteratively refines the policy by minimizing both the action prediction error and the state prediction error, resulting in a more robust and accurate learned behavior.
Trial and Error: Forging Behavior Through Experience
Reinforcement Learning (RL) is a machine learning paradigm wherein an agent, typically a robot, learns to perform tasks by interacting with an environment. The agent receives feedback in the form of rewards or penalties for its actions, and iteratively adjusts its behavior to maximize cumulative reward. This learning process does not require explicit programming of the desired behavior; instead, the robot discovers optimal strategies through trial and error. The core principle involves the agent learning a policy – a mapping from states to actions – that dictates its behavior in any given situation, aiming to achieve a long-term objective defined by the reward function.
Deep Q-Learning (DQN) and Proximal Policy Optimization (PPO) are prominent reinforcement learning algorithms utilized for robotic manipulation. DQN employs a deep neural network to approximate the optimal action-value function, enabling robots to learn optimal policies from high-dimensional sensory inputs. PPO, a policy gradient method, iteratively improves a policy by taking small, safe steps to maximize rewards while avoiding drastic changes that could destabilize learning. These algorithms facilitate the execution of complex manipulation tasks, such as grasping, assembly, and in-hand manipulation, by allowing robots to learn directly from experience and adapt to varying environmental conditions and task requirements. The efficacy of both DQN and PPO is dependent on hyperparameter tuning and careful reward function design to ensure efficient and stable learning.
Integrating Contrastive Learning (CL) and Masked Contrastive Learning (MCL) with Reinforcement Learning (RL) enhances the robot’s ability to develop effective internal representations of its environment. These techniques operate by training the robot to recognize similarities and differences between states, even with partial observations, thereby improving its state understanding. Specifically, CL encourages the learning of embeddings where similar states are close together in vector space, while MCL focuses on learning robust representations from incomplete data by predicting masked portions of the state. This improved representation learning facilitates faster convergence during RL training, as the agent requires fewer interactions with the environment to learn optimal policies. Consequently, the robot’s learning process is accelerated, leading to a reduction in the overall training time and improved sample efficiency.
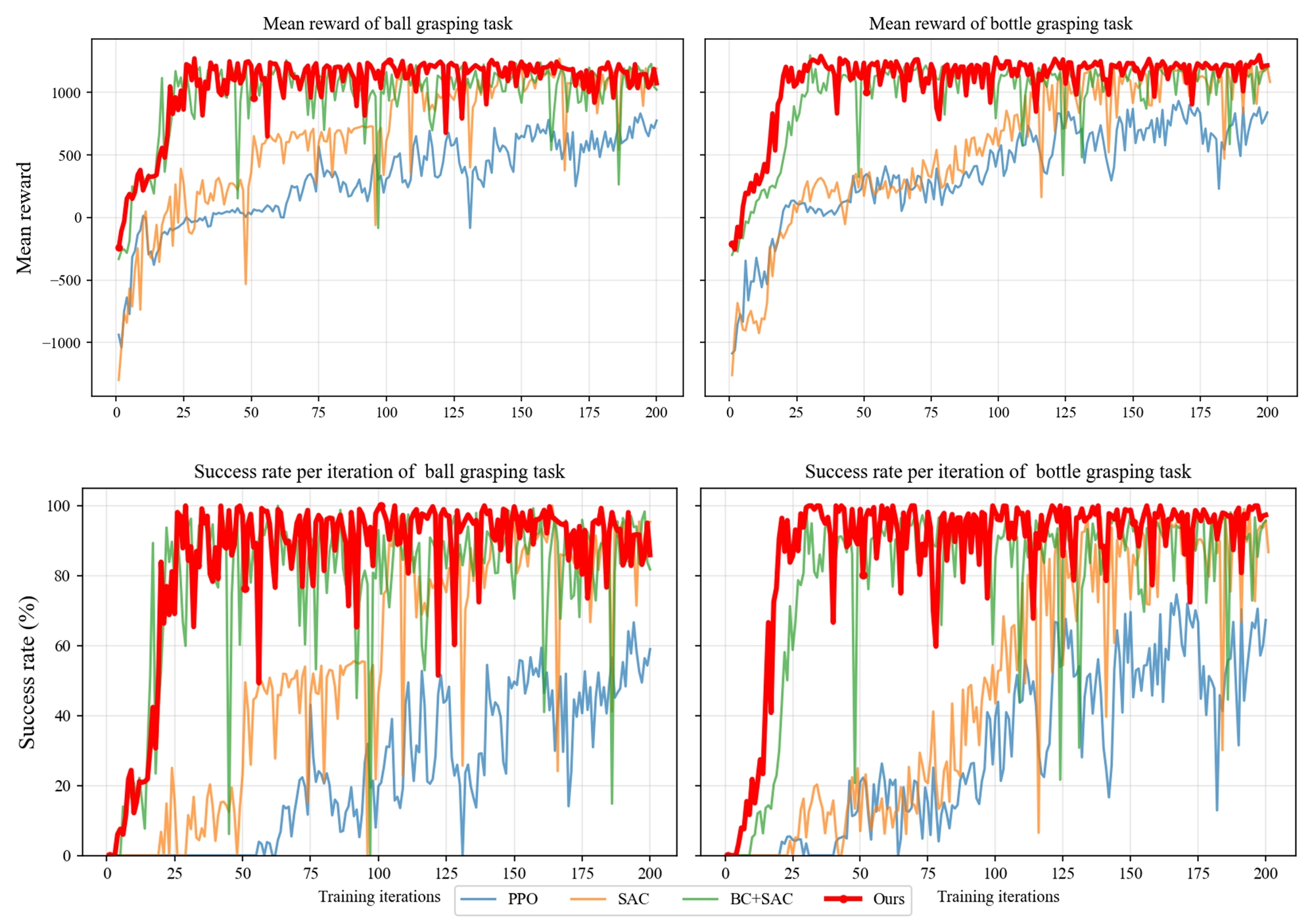
Evaluations of the newly developed imitation and contrastive learning assisted reinforcement learning algorithm demonstrate a substantial improvement in training efficiency. Comparative testing against the Soft Actor-Critic (SAC) algorithm revealed an approximate 4x reduction in training time to achieve comparable performance levels. This acceleration is attributed to the algorithm’s capacity to leverage both imitation learning for initial policy guidance and contrastive learning to enhance the learned representation, thereby reducing the sample complexity typically associated with reinforcement learning tasks and facilitating faster convergence.
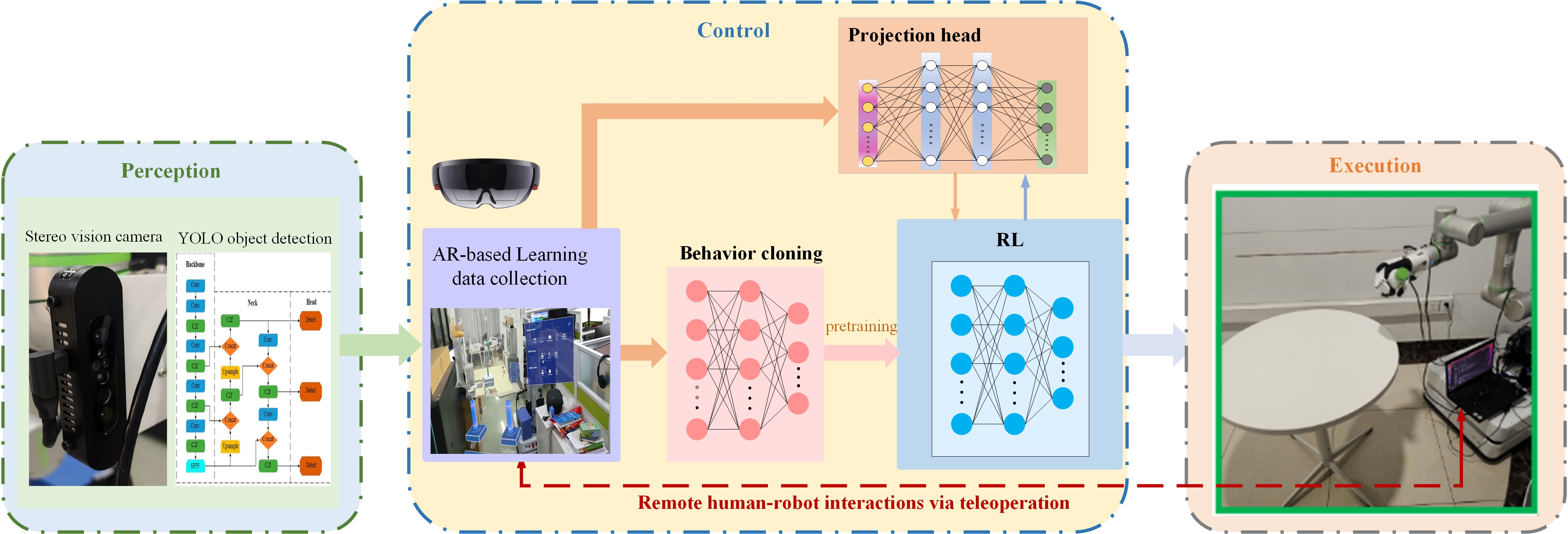
Bridging Perception and Action: A Unified System
The performance of robotic systems is fundamentally dependent on the effective coordination of perception and control subsystems; perception provides the necessary data regarding the robot’s environment, while control utilizes this information to execute actions and achieve desired outcomes. Discrepancies or delays between these two components-for example, inaccurate object detection influencing a grasping maneuver-directly impact system reliability and efficiency. Modern approaches prioritize architectures where perceptual data is continuously processed and fed into control algorithms, enabling real-time adaptation and robust operation in dynamic environments. This integration often involves sensor fusion techniques to combine data from multiple sources, and feedback loops to correct for errors and maintain stability. Ultimately, a truly effective robotic system functions not as a series of discrete steps, but as a unified, responsive entity.
YOLOv8 (You Only Look Once version 8) is a real-time object detection system that provides robots with the capability to identify and localize objects within their operational environment. Utilizing a single convolutional neural network, YOLOv8 achieves high accuracy and speed in identifying multiple objects per image, crucial for dynamic robotic applications. The system outputs bounding boxes and confidence scores for detected objects, allowing robots to not only recognize what objects are present, but also where they are located in 3D space. This enables advanced functionalities like grasping, navigation, and interaction with objects, forming a core component of environmental understanding for autonomous robots.
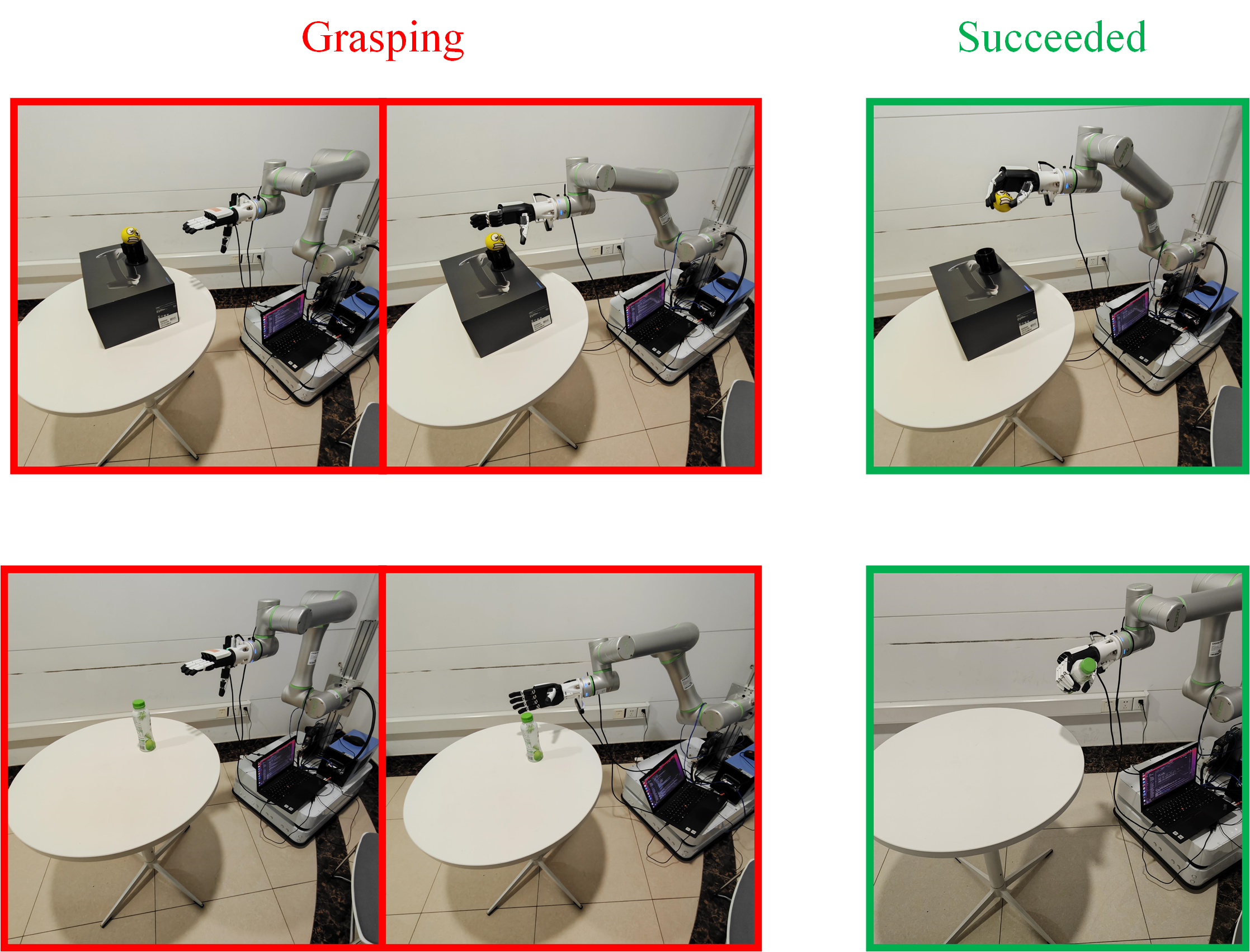
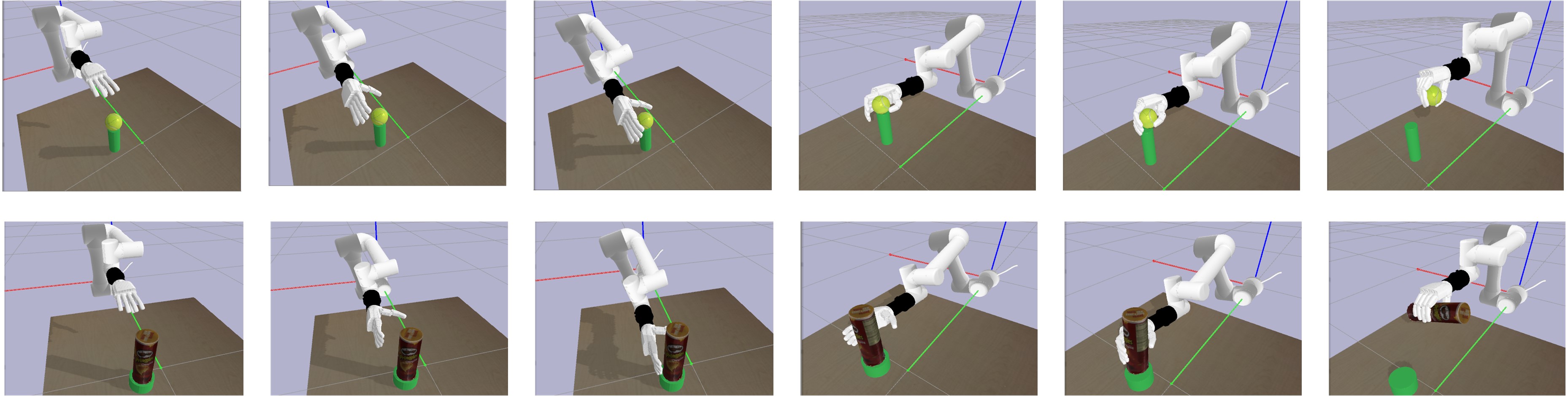
Augmented reality (AR)-based teleoperation utilizes platforms such as Unity and the HoloLens 2 to enable human operators to remotely control robots with enhanced situational awareness. The system overlays a live video feed from the robot onto the operator’s view through the HoloLens 2 headset, creating a combined real and virtual environment. This allows the operator to intuitively guide the robot’s movements and actions, perceiving the robot’s surroundings as if directly present. Furthermore, the AR interface facilitates the provision of real-time feedback to the robot, including corrections and task-specific instructions, improving operational precision and efficiency in complex or hazardous environments.
Robotic system development necessitates extensive testing and iterative improvement, which is efficiently facilitated by physics-based simulation environments like PyBullet. These simulators allow for the creation of virtual worlds where robots can operate and interact with objects without the risks and costs associated with real-world experimentation. PyBullet provides capabilities for modeling robot dynamics, sensor simulation, and collision detection, enabling developers to train control algorithms, evaluate system performance under diverse conditions, and identify potential failure points. The use of simulation significantly reduces development time and resource expenditure, while also providing a safe platform for testing potentially hazardous scenarios or complex maneuvers before deployment on physical hardware. Furthermore, simulated data can be used to augment real-world datasets for machine learning applications, improving the robustness and generalization capabilities of robotic systems.

The Inevitable Future: Autonomous Systems Emerge
A transformative leap in robotic intelligence is unfolding through the synergistic integration of imitation learning, reinforcement learning, and increasingly sophisticated perception systems. Historically, robots required explicit programming for each task, limiting their adaptability. Now, imitation learning allows robots to acquire skills by observing demonstrations – essentially learning ‘by watching’. This is then refined through reinforcement learning, where robots learn through trial and error, maximizing rewards for successful actions. Crucially, advanced perception – leveraging computer vision and other sensory inputs – provides the robots with a richer understanding of their surroundings, enabling them to generalize learned skills to new, unpredictable environments. This convergence isn’t merely incremental; it’s fostering robots capable of not just automating pre-defined tasks, but of adapting, problem-solving, and ultimately, exhibiting a level of autonomy previously confined to the realm of science fiction.
The potential of advanced robotics extends far beyond automated assembly lines, promising transformative capabilities across a spectrum of challenging environments. In manufacturing, these systems can adapt to dynamic production needs and handle intricate components with unprecedented precision. Healthcare stands to benefit from robotic assistance in surgery, rehabilitation, and even remote patient care, improving outcomes and access to specialized treatment. Beyond terrestrial applications, robots equipped with these technologies are poised to become indispensable tools for space exploration, conducting research in harsh conditions and constructing habitats on other planets. Furthermore, in the face of natural disasters, they offer a crucial lifeline, navigating dangerous terrain to locate survivors, deliver aid, and assess structural damage – effectively extending human reach and enhancing response efforts where it is too risky for people to venture.
Recent advancements in robotic intelligence have yielded a novel approach to dexterous manipulation, demonstrably outperforming established algorithms like Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC). This methodology achieved unprecedented success rates in both simulated environments and real-world applications, specifically in the challenging tasks of ball and bottle grasping. Rigorous testing revealed a significant improvement in the robot’s ability to reliably identify, approach, and secure these objects, indicating a substantial leap forward in robotic handling capabilities. The heightened performance suggests the potential for broader implementation across industries requiring precise and adaptable manipulation, from automated assembly lines to complex surgical procedures, ultimately paving the way for more versatile and efficient robotic systems.
Graph Convolutional Networks (GCNs) are emerging as a powerful tool for tackling complex robotic tasks, particularly those involving collaborative packaging and assembly. Unlike traditional neural networks which struggle with relational data, GCNs excel at processing information structured as graphs – representing objects and their relationships within a scene. This allows robots to not merely see objects, but to understand how they connect and interact, crucial for tasks like arranging items in a box or assembling components. By representing a workspace as a graph where nodes are objects and edges represent possible interactions, the robot can strategically plan movements and coordinate actions with greater efficiency. Recent studies demonstrate GCNs’ ability to learn optimal packing configurations and predict the stability of arrangements, potentially leading to fully automated and adaptable packaging solutions in logistics and manufacturing.
The pursuit of scalable dexterous robot learning, as demonstrated in this work, echoes a fundamental truth about complex systems. The algorithm’s blend of imitation and contrastive learning, coupled with AR-based teleoperation, doesn’t so much build a solution as cultivate one – a gradual emergence of capability from the interplay of simulation and reality. This resonates with Donald Knuth’s observation: “Premature optimization is the root of all evil.” The focus isn’t on immediate perfection, but on creating a robust, adaptable system capable of surviving the inevitable chaos of real-world deployment. Each iteration, each refinement, is a testament to the principle that order is merely a cache between two outages, and the goal is not to eliminate those outages, but to build a system resilient enough to withstand them.
The Garden Grows
This work, like all attempts to command complex systems, reveals more about the limits of control than its successes. The combination of imitation and reinforcement learning, guided by remote human input, isn’t a shortcut to autonomy – it’s the construction of a more elaborate feedback loop. Each improved manipulation, each successful sim-to-real transfer, is merely a temporary reprieve from the inevitable drift of a system away from its initial conditions. Resilience doesn’t lie in isolating components, but in forgiveness between them – in the capacity to absorb error and continue functioning, albeit imperfectly.
The true challenge isn’t scaling dexterity, but understanding the ecosystem of learning itself. The current paradigm treats data as a resource to be harvested, but perhaps it’s better understood as a form of cultivation. A robot doesn’t simply learn from demonstrations; it co-evolves with them, shaping and being shaped by the human operator’s intentions. The next frontier isn’t about achieving flawless execution, but about designing systems that gracefully accommodate ambiguity and change.
One anticipates a move away from monolithic algorithms toward more distributed, adaptive architectures. A system isn’t a machine to be built, but a garden to be grown – neglect it, and one will grow technical debt. The focus will shift from optimizing for specific tasks to fostering a capacity for continuous learning and adaptation, recognizing that true intelligence isn’t about solving problems, but about learning to live with them.
Original article: https://arxiv.org/pdf/2602.07341.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Magicmon: World redeem codes and how to use them (March 2026)
- Gold Rate Forecast
- “Wild, brilliant, emotional”: 10 best dynasty drama series to watch on BBC, ITV, Netflix and more
- Total Football free codes and how to redeem them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Seeing in the Dark: Event Cameras Guide Robots Through Low-Light Spaces
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
2026-02-10 21:55