Author: Denis Avetisyan
Researchers are leveraging principles of pedagogy to create more effective training data for smaller language models, dramatically improving their reasoning and instruction-following abilities.
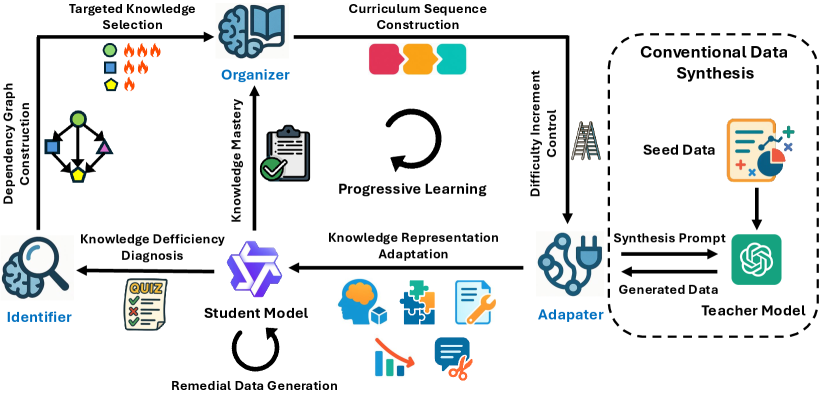
This work introduces IOA, a framework for dynamically synthesizing data and adapting curriculum to address specific knowledge gaps during language model knowledge distillation.
While knowledge distillation effectively compresses large language models, current data synthesis techniques often treat learning as a single-step process, overlooking crucial pedagogical principles. This work, ‘Pedagogically-Inspired Data Synthesis for Language Model Knowledge Distillation’, introduces a novel framework-IOA-that dynamically adapts curriculum and synthetic data to address specific knowledge deficiencies in student models. Experiments demonstrate that IOA significantly improves performance-retaining 94.7% of teacher performance with less than 1/10th the parameters-particularly in complex reasoning tasks. Could this pedagogically-informed approach unlock a new era of efficient and robust language model development?
Addressing the Core Challenge: Catastrophic Forgetting in Language Models
Large language models demonstrate remarkable abilities in identifying and replicating patterns within vast datasets, enabling them to generate human-quality text and perform complex linguistic tasks. However, this proficiency is often undermined by a phenomenon known as ‘catastrophic forgetting’. When these models are trained on a new task or dataset, they can abruptly and significantly lose previously acquired knowledge, effectively overwriting older learnings with the new information. This isn’t a gradual decline, but a swift and substantial loss of performance on prior tasks, hindering the development of truly adaptable and continuously learning AI systems. The core issue stems from the models’ reliance on adjusting all parameters during training, meaning new knowledge is not integrated with old knowledge, but rather replaces it, creating a significant obstacle to building robust, general-purpose language AI.
While knowledge distillation offers a pathway to create smaller, more efficient language models, a critical limitation arises when transferring complex reasoning abilities. Traditional methods often prioritize matching the outputs of a larger ‘teacher’ model, overlooking the intricate internal logic that drives those outputs. This superficial mimicry can lead to a student model that performs well on benchmark datasets but falters when faced with novel situations requiring genuine understanding. The nuances of problem-solving, such as identifying subtle relationships or applying common sense, are frequently lost in the simplification process, resulting in a student model capable of impressive feats of pattern recognition yet lacking in robust, adaptable intelligence. Consequently, researchers are actively exploring techniques to preserve these higher-order cognitive skills during distillation, moving beyond simple output matching to capture the ‘how’ as well as the ‘what’ of intelligent reasoning.
The pursuit of deploying artificial intelligence in resource-constrained environments hinges on the effective transfer of knowledge from large, capable models – often termed ‘teachers’ – to smaller, more efficient ‘student’ models. This process isn’t simply a matter of replicating performance; it demands preserving the nuanced reasoning and generalization abilities embedded within the teacher. Current techniques often struggle with this fidelity, resulting in student models that mimic outputs without truly understanding the underlying principles. Consequently, research focuses on innovative distillation methods that go beyond surface-level imitation, aiming to imbue student models with the capacity to learn how to learn, rather than merely what to output, ultimately unlocking the potential for widespread and practical AI applications.
The practical deployment of large language models faces a significant hurdle due to their susceptibility to forgetting previously acquired knowledge. This limitation isn’t merely an academic concern; it directly impacts an LLM’s ability to function reliably in dynamic, real-world scenarios. As these models are continually updated and refined with new information, they often experience a degradation in performance on tasks they were previously proficient in, a phenomenon known as catastrophic forgetting. This creates challenges for applications requiring consistent performance across a broad range of topics, such as complex problem-solving or nuanced conversation. Without mechanisms to preserve prior learning, LLMs struggle to adapt to evolving demands, hindering their robustness and ultimately limiting their potential in critical applications where consistent, dependable performance is paramount.
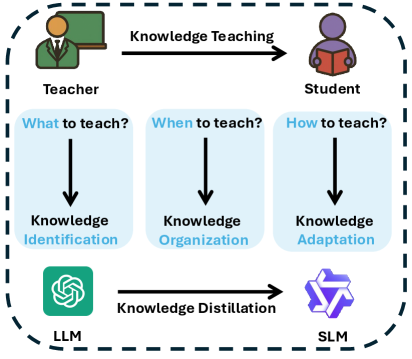
IOA: A Pedagogically-Inspired Framework for Knowledge Transfer
IOA is a distillation framework designed to transfer knowledge from a teacher model to a student model, grounded in established pedagogical principles. This framework operates through three core modules: Knowledge Identification, Organization, and Adaptation. The process begins with identifying specific knowledge deficits within the student model to determine areas requiring focused instruction. Subsequently, the framework organizes knowledge into a progressive curriculum, prioritizing foundational concepts and building towards more complex understanding. Finally, IOA adapts the representation of knowledge to align with the student model’s current capabilities, ensuring effective knowledge transfer and maximizing learning potential. This approach aims to move beyond simple performance matching and facilitate genuine knowledge acquisition within the student model.
The IdentifierModule within the IOA framework functions by analyzing the student model’s performance to detect specific knowledge deficiencies. This analysis extends beyond simple accuracy metrics; it assesses the nature of errors, identifying where the student model lacks understanding of core concepts or exhibits flawed reasoning. The module then quantifies these knowledge gaps, creating a prioritized list of areas requiring focused attention during distillation. This targeted approach ensures that the distillation process isn’t a uniform transfer of knowledge, but rather a focused intervention addressing the student model’s precise weaknesses, maximizing learning efficiency and preventing the reinforcement of incorrect patterns.
The OrganizerModule within IOA constructs a progressive curriculum by establishing dependencies between knowledge components and sequencing them accordingly. This sequencing prioritizes foundational concepts before introducing more complex ones, ensuring a logical learning path. Alignment with Bloom’s Mastery Learning principles is achieved by allowing the student model to progress only after demonstrating competence in prerequisite skills; assessment is continuous and integrated into the curriculum, with iterative refinement of the knowledge sequence based on performance. This ensures the student model achieves a defined level of proficiency before advancing to subsequent concepts, maximizing knowledge retention and minimizing the accumulation of unaddressed knowledge gaps.
The AdapterModule within IOA functions by modifying the complexity and format of knowledge transferred to the student model, directly applying Vygotsky’s Zone of Proximal Development (ZPD) principles. This involves assessing the student model’s current capabilities and presenting information within a range slightly beyond its independent level, but achievable with guidance. Specifically, the module employs techniques such as dimensionality reduction, feature selection, and knowledge simplification to represent concepts in a manner aligned with the student’s capacity. This ensures that the student model isn’t overwhelmed by excessively complex information, promoting efficient learning and minimizing the risk of knowledge bottlenecks. The module dynamically adjusts the knowledge representation based on the student’s ongoing performance, continually optimizing the learning experience within its ZPD.
Augmenting Learning: Synthetic Data Generation for Robustness and Remediation
SyntheticDataGeneration involves the programmatic creation of datasets designed to augment training data and improve model performance in specific areas. This technique allows for the creation of data instances that reflect desired characteristics or edge cases not sufficiently represented in existing datasets. By controlling the parameters of data generation, we can create targeted datasets that enhance a student model’s robustness to variations in input and address identified knowledge gaps, effectively providing focused training on areas where the model exhibits weakness. The generated data is statistically similar to real data but offers greater control over distribution and feature representation, facilitating the development of more resilient and accurate models.
Chain-of-Thought Reasoning (CoT) is implemented to generate synthetic datasets consisting of multi-step problem-solving scenarios. This technique involves prompting a large language model to not only provide a final answer but also to explicitly articulate the intermediate reasoning steps taken to arrive at that solution. The resulting data includes both the problem statement, the complete reasoning trace, and the final answer. By training student models on this type of data, the system aims to improve the student’s ability to generalize to unseen problems by learning to replicate the logical progression of thought required for successful problem-solving, rather than simply memorizing input-output pairings. This approach enhances performance on complex tasks requiring sequential reasoning and improves interpretability of the student model’s decision-making process.
Counterfactual Data Synthesis (CDS) is a technique used to improve the robustness of student models by generating modified examples that present alternative, yet plausible, solutions to the same problem. These synthetically created examples differ from the original data point in specific features relevant to the decision-making process, effectively demonstrating ‘what if’ scenarios. By exposing the student model to these counterfactuals, it learns to discern critical features and avoid relying on spurious correlations, thereby enhancing its performance in ambiguous or adversarial conditions. The generated data doesn’t simply present correct/incorrect pairs, but explores the solution space around a given input, forcing the model to justify its reasoning and generalize beyond the training distribution.
RemedialDataGeneration is a targeted approach to dataset creation, designed to address specific deficiencies in a student model’s performance. This technique involves identifying areas where the model consistently fails or exhibits low confidence, then generating synthetic data examples focused on those identified weaknesses. The generated data is not random; it is carefully constructed to provide focused practice on the problematic skills or knowledge areas. This allows for iterative reinforcement learning, enabling the model to improve its accuracy and robustness in areas where it previously struggled, ultimately leading to a more well-rounded and capable system.
Demonstrating Performance Gains Through Empirical Validation
Instruction Optimization via Alignment (IOA) facilitates knowledge transfer from larger, more capable teacher models – specifically DeepSeekR1 and OpenAIo1 – to smaller student models, namely LLaMA3.1 and Qwen2.5. This distillation process enables the student models to approximate the performance of their teachers despite having fewer parameters. The technique focuses on aligning the student’s behavior with that of the teacher through optimized instruction following, allowing the student to benefit from the teacher’s pre-existing knowledge and reasoning abilities without requiring the same computational resources.
Knowledge transfer via Instruction Optimization Alignment (IOA) is enhanced through the combined application of LogitDistillation and IntermediateLayerRepresentationDistillation techniques. LogitDistillation focuses on aligning the probability distributions output by the teacher and student models, while IntermediateLayerRepresentationDistillation encourages the student model to replicate the internal feature representations of the teacher model at various layers. Utilizing both methods concurrently allows for a more comprehensive transfer of knowledge, encompassing both the final predictions and the underlying reasoning processes, thereby maximizing the student model’s performance and ability to generalize.
AdversarialDistillation is employed as a refinement step following initial knowledge transfer via LogitDistillation and IntermediateLayerRepresentationDistillation. This technique introduces perturbed inputs to the student model during training, forcing it to learn more robust features and improve generalization performance. By training the student to correctly classify slightly modified inputs, the model becomes less susceptible to noise and variations in real-world data, resulting in enhanced performance on unseen examples and improved overall reliability. The method specifically targets vulnerabilities in the student model, strengthening its ability to maintain accurate predictions under challenging conditions.
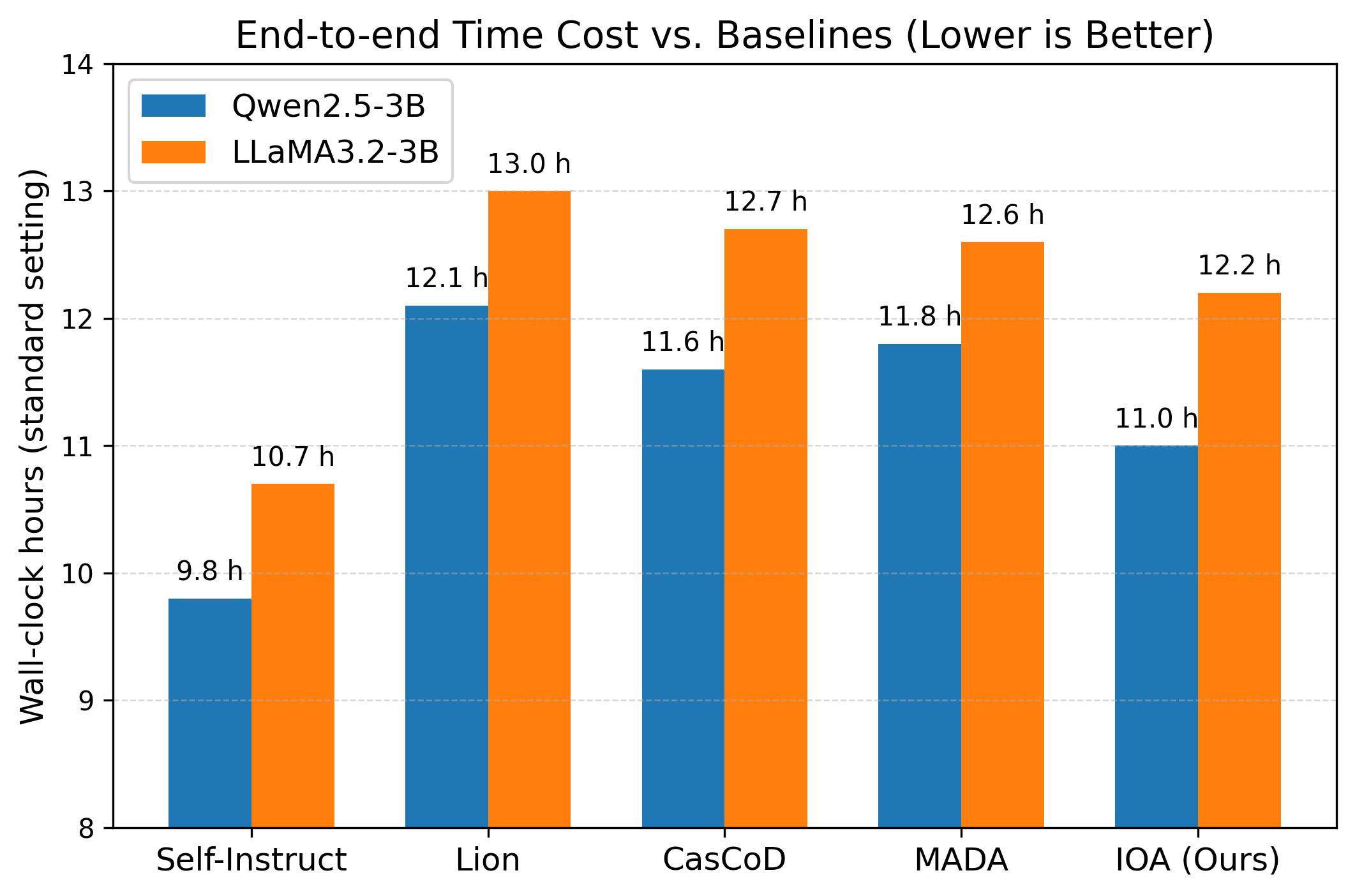
Quantitative evaluation of the knowledge distillation process demonstrates a 7.76% average performance improvement across all reasoning benchmarks. Specifically, the DeepSeek-R1-Distill-Qwen-14B model achieved 65.43% accuracy on the GSM8K benchmark, a dataset of grade school math problems, and a 49.25% Pass@1 rate on the HumanEval benchmark, which assesses functional code generation capabilities. These results indicate a substantial gain in reasoning performance through the implemented distillation techniques and model architecture.
Evaluation of agentic capabilities using the MT-Bench benchmark resulted in a score of 8.23. Furthermore, testing on the AIME2024 dataset yielded an accuracy of 11.62%. These results indicate that the knowledge distillation approach, incorporating IOA and related techniques, positively impacts the student model’s performance in tasks requiring complex, multi-step reasoning and interaction, characteristics of agentic AI systems.
Towards Truly Adaptive and Lifelong Learning Systems
Intelligent Organization of Acquaintances (IOA) presents a novel architecture designed to facilitate continuous learning in artificial intelligence systems. Unlike traditional models requiring retraining from scratch with each new dataset, IOA enables agents to incrementally build upon existing knowledge, identifying and integrating new information without disrupting previously learned concepts. This is achieved by structuring knowledge as a network of interconnected ‘acquaintances,’ where the strength of connections reflects the relationships between different pieces of information. Consequently, the system can dynamically adapt to evolving environments, efficiently refine its understanding, and maintain robust performance even when faced with novel or ambiguous data – paving the way for truly lifelong learning capabilities in artificial intelligence.
Intelligent Open Adaptation (IOA) distinguishes itself by moving beyond uniform learning approaches and instead emphasizing the interconnectedness of knowledge. This framework posits that efficient artificial intelligence isn’t simply about acquiring more information, but about understanding how new data relates to existing concepts. By mapping these knowledge dependencies, IOA enables systems to prioritize learning efforts, focusing on areas where new information can most effectively build upon-or correct-current understanding. Furthermore, IOA facilitates personalized learning pathways; recognizing that each ‘student’ – be it a robot or an algorithm – possesses a unique knowledge base, the system tailors the learning process to address individual gaps and optimize knowledge integration. This adaptive approach not only accelerates learning but also results in more robust AI, less susceptible to errors arising from incomplete or misconstrued information.
The principles of individualized organization of aptitude extend far beyond theoretical foundations, holding significant promise for a diverse range of real-world applications demanding constant adaptation. In robotics, this framework could enable robots to dynamically adjust their skill sets based on environmental changes and task requirements, moving beyond pre-programmed routines. Personalized education stands to be revolutionized by tailoring learning paths to each student’s unique knowledge dependencies and pace, fostering deeper understanding and retention. Furthermore, the development of truly autonomous agents – whether navigating complex environments or making critical decisions – relies on systems capable of continuous self-improvement and adaptation, a capability directly addressed by this innovative approach to knowledge organization and learning.
Ongoing research endeavors are directed towards broadening the applicability of the Integrated Opportunity Assessment (IOA) framework to encompass increasingly intricate knowledge domains, moving beyond current limitations. This includes investigations into methods for representing and reasoning with nuanced, multi-faceted information inherent in fields like medical diagnosis or advanced engineering. Crucially, exploration extends to the potential of unsupervised learning within IOA, aiming to enable systems to autonomously identify relevant knowledge dependencies and refine their understanding without explicit guidance. Successfully integrating unsupervised approaches promises to unlock a pathway towards truly lifelong learning systems, capable of continuous adaptation and knowledge expansion in dynamic, real-world environments, ultimately enhancing robustness and efficiency in applications like robotics and personalized education.
![Analysis of five key hyperparameters-[latex]\tau_{gap}[/latex], [latex]\tau_{high}[/latex], [latex]\tau_{low}[/latex], [latex]\tau_{dep}[/latex], and α-demonstrates the robustness of the Identifier component within the IOA framework.](https://arxiv.org/html/2602.12172v1/Figures/supplementary_hyperparameter_analysis.png)
The pursuit of efficient knowledge distillation, as detailed in the study, echoes a fundamental principle of system design: elegance through simplicity. The IOA framework, with its dynamic curriculum and targeted data synthesis, embodies this approach. It doesn’t attempt to brute-force knowledge transfer, but rather carefully orchestrates a learning path, addressing deficiencies as they arise. As Ken Thompson observed, “Sometimes it’s better to rewrite the code than to debug it.” Similarly, IOA suggests that rather than simply shrinking a large model, a more effective strategy lies in re-architecting the learning process itself – crafting a curriculum that fosters understanding rather than rote memorization, a concept central to the paper’s innovative approach to reasoning and instruction following.
Beyond the Lesson Plan
The pursuit of efficient knowledge distillation, as demonstrated by this work, often feels like reinforcing a structure with increasingly sophisticated duct tape. The IOA framework offers a compelling move toward principled curriculum design, but it highlights a deeper truth: modularity, even in learning, is an illusion of control without a robust understanding of the underlying cognitive architecture. A model can become adept at following instructions, yet remain brittle when confronted with genuinely novel situations. The next phase necessitates a move beyond simply what is learned, to how knowledge is represented and integrated – a focus on internal consistency, not merely external performance.
Currently, the field largely treats data synthesis as a means to an end – a tool to nudge a smaller model towards the outputs of a larger one. But what if the synthesis process itself is the key? A truly elegant system would not simply generate examples to fill gaps, but actively seek out contradictions, forcing the student model to refine its internal representation of the world.
Ultimately, the success of pedagogically-inspired distillation hinges on acknowledging that intelligence isn’t simply a matter of scaling parameters or refining loss functions. It’s about building systems capable of genuine adaptation, systems that learn not just from data, but about data – recognizing its limitations, inconsistencies, and inherent biases. The path forward lies in embracing the messiness of learning, rather than attempting to engineer a flawlessly curated experience.
Original article: https://arxiv.org/pdf/2602.12172.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Gold Rate Forecast
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
2026-02-15 23:00