Author: Denis Avetisyan
Researchers have developed a novel method that uses the power of language models and formal verification to automatically discover and exploit vulnerabilities in deep learning libraries.
This paper introduces Centaur, a neurosymbolic technique leveraging large language models and symbolic execution to learn API input constraints for improved bug detection and testing efficiency.
Despite the widespread adoption of deep learning libraries like PyTorch and TensorFlow, their inherent complexity and susceptibility to bugs necessitate more effective testing methodologies. This paper, ‘Testing Deep Learning Libraries via Neurosymbolic Constraint Learning’, introduces Centaur, a novel neurosymbolic technique that dynamically learns input constraints for these libraries by integrating large language models with symbolic execution. Centaur achieves high precision and recall in constraint learning, significantly improving test coverage and detecting 26 previously unknown bugs across PyTorch and TensorFlow. Could this approach pave the way for more robust and reliable deep learning systems through automated, constraint-driven testing?
The Imperative of Robust API Validation
Contemporary software architecture is fundamentally built upon Application Programming Interfaces (APIs), serving as the crucial connective tissue between different applications, services, and data sources. This reliance necessitates rigorous and comprehensive API testing, as any vulnerability or malfunction within these interfaces can cascade into widespread system failures. Unlike traditional software components with clearly defined user interfaces, APIs operate ‘under the hood,’ demanding specialized testing strategies to validate their functionality, security, and performance. The increasing complexity of modern applications, coupled with the growing number of interconnected APIs, amplifies the risk; therefore, robust API testing is no longer simply a best practice, but a critical determinant of software reliability and user experience.
Contemporary APIs, serving as the connective tissue of modern software, present a significant testing hurdle due to their inherent complexity and expansive input domains. Traditional testing approaches, often reliant on manually crafted test cases or limited automated scripts, quickly become impractical when faced with the sheer number of potential inputs and state combinations an API can exhibit. This is further complicated by intricate interactions between different API endpoints and dependencies on external services, making it difficult to achieve comprehensive coverage and reliably identify edge cases. Consequently, bugs can slip through the cracks, leading to unpredictable application behavior and potentially compromising system stability, highlighting the need for more sophisticated and scalable API testing strategies.
Centaur: A Neurosymbolic Synthesis for Constraint Acquisition
Centaur utilizes Large Language Models (LLMs) to interpret API signatures, specifically focusing on the expected input parameters and their associated data types. The LLM analyzes the API documentation and code to generate potential constraints that define valid input ranges, acceptable values, and relationships between parameters. This process involves the LLM’s ability to understand natural language descriptions of the API and translate them into a preliminary set of constraints suitable for further formal verification. The initial constraints proposed by the LLM serve as a starting point, reducing the search space for the subsequent SMT constraint solving phase and accelerating the overall constraint learning process.
Satisfiability Modulo Theories (SMT) constraint solving is employed to rigorously validate and refine the candidate input constraints proposed by the Large Language Model. This process involves formulating the constraints – typically expressed as logical predicates – into a standard SMT format, and then utilizing an SMT solver to determine if a solution exists that satisfies all conditions. If the SMT solver finds a satisfying assignment, the constraint is considered valid and accurately defines a portion of the API’s input space. Conversely, if the solver determines the constraints are unsatisfiable, indicating no valid input exists, the initial constraint is revised or discarded, ensuring the final constraint set comprehensively and accurately represents the API’s acceptable input domain.
Centaur achieves efficient API input constraint learning by integrating the intuitive capabilities of Large Language Models with the rigor of SMT constraint solving for formal verification. Evaluation demonstrates a recall of 88.6% when generating constraints for the Pytorch API, indicating the system correctly identifies 88.6% of valid constraints when compared to a ground truth dataset. For the Tensorflow API, Centaur achieves 100% recall, signifying complete and accurate constraint generation relative to the established ground truth. This performance indicates a strong ability to both propose likely constraints and validate their correctness through formal methods.

Valid Input Generation: A Prerequisite for Meaningful API Evaluation
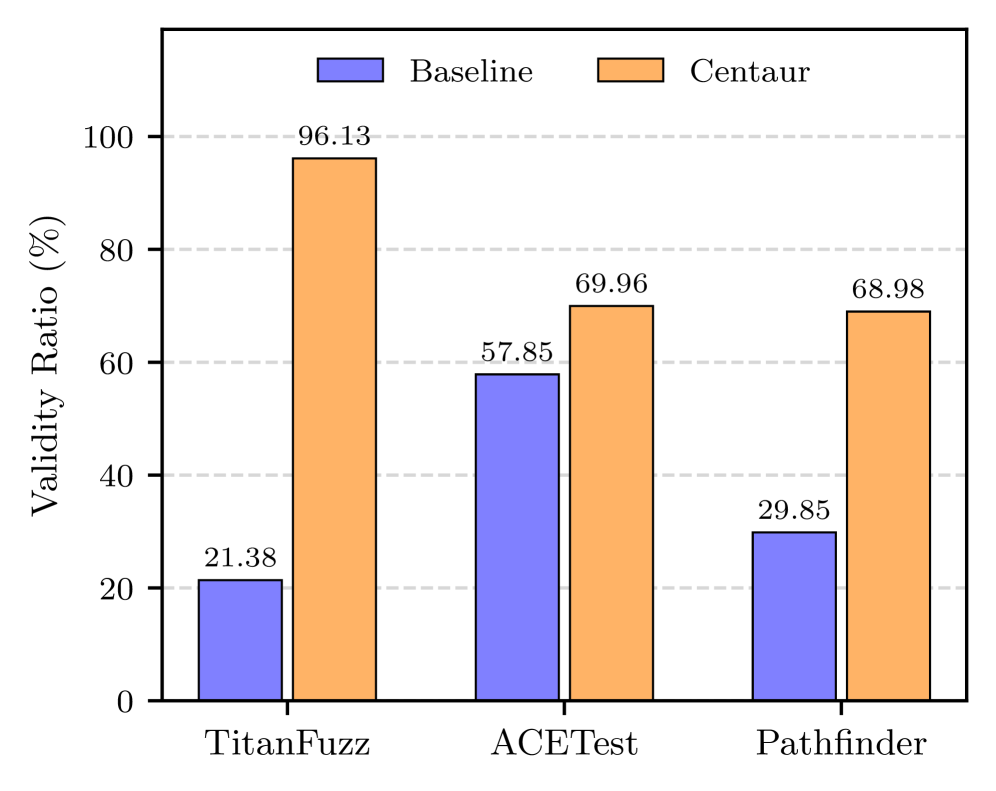
The generation of valid inputs is a primary obstacle in effective API testing, as many tools struggle to create requests that adhere to API specifications and avoid immediate rejection. Traditional approaches often rely on either random input generation – resulting in a high percentage of invalid tests – or heuristic-based methods that may miss critical edge cases. Centaur directly addresses this challenge by focusing on producing inputs guaranteed to be syntactically and semantically correct according to the API’s expected format, thereby maximizing test coverage with functional requests and minimizing wasted testing effort on malformed or invalid calls. This focus on validity is crucial for reliable API evaluation and identifying genuine software defects.
Current approaches to generating valid inputs for API testing, such as FreeFuzz, DocTer, and TitanFuzz, commonly utilize heuristic methods and incomplete information to define input constraints. These tools often infer expected input structures from documentation or code analysis, but lack the capacity to comprehensively identify all valid input combinations or to account for complex interdependencies between input parameters. Consequently, generated test suites may exhibit limited coverage and fail to expose potential vulnerabilities arising from unexpected or edge-case inputs, necessitating manual intervention and increasing testing costs.
Centaur improves API test generation by integrating Large Language Model (LLM)-driven constraint learning with formal verification techniques. This combined approach allows for the creation of more comprehensive test suites compared to existing tools like FreeFuzz, DocTer, and TitanFuzz, which often rely on heuristic methods. Evaluations on Pytorch and Tensorflow APIs demonstrate Centaur achieves a 97.87% validity ratio, indicating a significantly higher proportion of generated inputs adhere to defined constraints and successfully execute without errors, exceeding the performance of current state-of-the-art solutions.

Transcending API-Level Checks: Towards Holistic Model Integrity
Centaur distinguishes itself through a neurosymbolic approach to software testing that moves beyond simple API-level checks to encompass a more holistic, model-level understanding of the system under test. This capability arises from the system’s ability to learn constraints not just from input-output interactions, but also from the internal workings and logical structure of the model itself. By bridging the gap between neural network reasoning and symbolic execution, Centaur can identify violations of expected behavior that would remain hidden to traditional API tests. This transition to model-level testing represents a significant advancement, allowing for a deeper, more nuanced evaluation of software reliability and a greater capacity to uncover complex bugs residing within the model’s core logic.
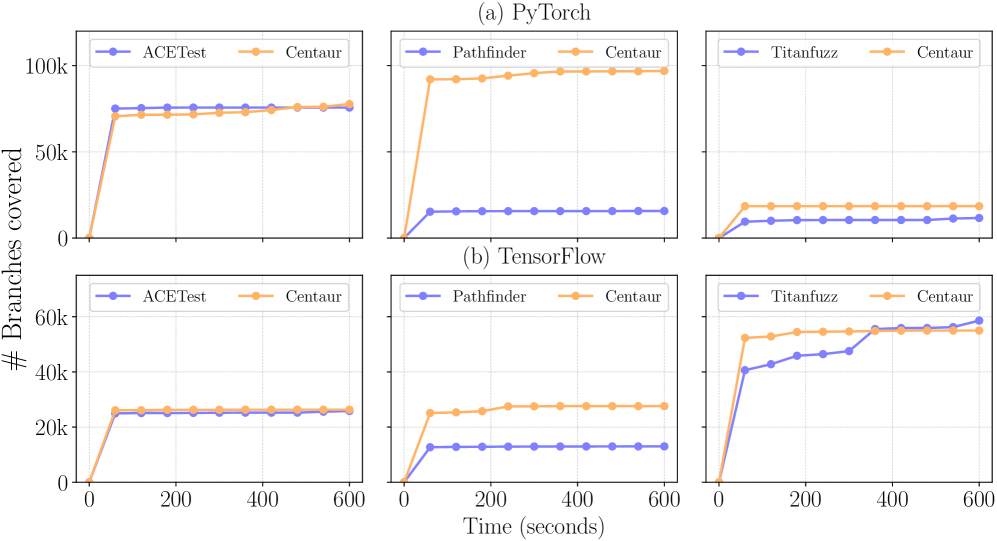
The efficacy of Centaur’s neurosymbolic testing framework is significantly amplified when combined with established formal methods. Integrating tools like Daikon – a dynamic invariant detector – allows for the automated discovery of likely program properties, which then inform constraint generation. Pathfinder, a symbolic execution engine, deepens path exploration, while ACETest, focused on automated constraint solving and test case generation, further refines the search for violating conditions. This synergistic approach doesn’t merely add tools; it cultivates a more robust constraint learning process, enabling Centaur to achieve broader test coverage and, crucially, identify a wider range of potential software defects than any single technique in isolation.
Evaluations demonstrate that Centaur achieves substantially improved model testing coverage compared to the established Pathfinder tool. Quantitative analysis, utilizing Cohen’s d, reveals a remarkably large effect size – 17.05 for Pytorch models and 4.76 for Tensorflow implementations – indicating a genuinely significant advancement in test efficacy. This heightened coverage translated directly into practical results; Centaur successfully identified a total of 26 potential software defects, of which developers have confirmed 18 as legitimate bugs. These findings underscore Centaur’s ability to not only explore a broader range of model states but also to pinpoint critical vulnerabilities that might otherwise remain undetected, representing a considerable step forward in ensuring the reliability and robustness of machine learning systems.
The pursuit of robust deep learning libraries demands more than empirical validation; it requires formal guarantees of correctness. Centaur, as presented in the study, embodies this principle through its neurosymbolic approach to API input constraint learning. This aligns perfectly with the sentiment expressed by Marvin Minsky: “You can’t always get what you want, but sometimes you get what you need.” The ‘need’ here isn’t simply for bug detection, but for a rigorous, mathematically grounded method of ensuring software reliability. By combining the power of large language models with symbolic execution, Centaur moves beyond merely finding errors to proving the absence of certain classes of errors, a cornerstone of truly elegant and dependable code.
What Lies Ahead?
The presented work, while demonstrating a pragmatic advance in the verification of deep learning libraries, merely scratches the surface of a fundamentally difficult problem. The reliance on large language models to infer API constraints, though empirically effective, introduces a concerning reliance on stochastic pattern matching. A truly elegant solution would derive these constraints a priori from formal specifications of the library’s intended behavior – a task, admittedly, currently beyond the capabilities of most developers to express with sufficient precision. The current approach is, therefore, a sophisticated heuristic, not a proof of correctness.
Future research must address the scalability of neurosymbolic techniques beyond the relatively constrained APIs examined herein. The asymptotic complexity of symbolic execution, even when guided by neural networks, remains a significant bottleneck. Exploration of alternative constraint solving strategies, perhaps leveraging SMT solvers with specialized heuristics for deep learning operations, is warranted. Further, the generalization capability of the learned constraints-their robustness to minor API revisions or library implementations-requires rigorous investigation.
Ultimately, the quest for verifiable deep learning is not merely an engineering challenge, but a philosophical one. It forces a confrontation with the inherent limitations of empirical testing. A system that merely ‘passes tests’ is not necessarily correct, and the space of possible inputs is, in principle, infinite. The pursuit of formal guarantees, however arduous, remains the only path toward truly trustworthy artificial intelligence.
Original article: https://arxiv.org/pdf/2601.15493.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Total Football free codes and how to redeem them (March 2026)
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
2026-01-25 13:34