Author: Denis Avetisyan
New research explores how large language models can automatically craft incentive structures that foster better collaboration in multi-agent reinforcement learning systems.

This work introduces an objective-grounded reward search framework leveraging large language models to design shaping rewards for improved coordination and performance in cooperative multi-agent reinforcement learning.
Designing effective incentives for cooperative multi-agent systems remains a challenge, often requiring extensive manual effort and potentially yielding suboptimal coordination. This is addressed in ‘Large Language Model Guided Incentive Aware Reward Design for Cooperative Multi-Agent Reinforcement Learning’, which introduces an automated framework leveraging large language models to synthesize objective-grounded reward programs from environment instrumentation. Through iterative search and evaluation under fixed computational budgets, the method consistently yields improved task performance and coordination, particularly in complex environments with interaction bottlenecks. Could this approach offer a scalable solution for reward engineering, ultimately enabling more robust and adaptable cooperative agents?
The Challenge of Sparse Rewards: A Fundamental Impediment
Traditional reinforcement learning algorithms often falter when faced with sparse reward signals, a common characteristic of complex environments. These algorithms rely on frequent feedback to correlate actions with outcomes, but when rewards are infrequent or significantly delayed, the agent struggles to discern which actions contributed to eventual success. This presents a substantial challenge because the agent may perform many actions before receiving any indication of progress, making it difficult to learn an effective policy. Consequently, the exploration of the environment becomes inefficient, and the agent may get stuck in suboptimal behaviors, unable to discover rewarding sequences of actions despite their potential existence. This difficulty highlights the need for methods that can effectively bridge the gap between action and reward, even when those rewards are scarce and distant in time.
The scarcity of immediate rewards poses a significant hurdle for multi-agent systems, largely because effective coordination amplifies the difficulty of learning. When multiple agents operate within a shared environment, the impact of any single action is often diffused across the collective, making it challenging to attribute reward to specific contributions. This creates a ‘credit assignment problem’ – determining which agent(s) deserve recognition for a successful outcome, or conversely, should be corrected for a failure. The complexity escalates with the number of agents and the intricacy of the task, as the space of possible joint actions grows exponentially. Consequently, agents may struggle to discern beneficial behaviors from random occurrences, hindering their ability to learn effective cooperative strategies and achieve shared objectives.
The ability to deploy effective multi-agent systems hinges on overcoming the difficulties presented by sparse rewards; without robust learning in these conditions, real-world applications remain limited. Consider scenarios demanding complex coordination – automated warehouse logistics, swarms of drones performing search and rescue, or even collaborative robotics in manufacturing – all necessitate agents that can learn from infrequent signals indicating successful task completion. Progress in this area isn’t merely an academic exercise, but a practical requirement for translating artificial intelligence research into tangible benefits. Successfully addressing sparse reward challenges unlocks the potential for agents to operate autonomously in complex, dynamic environments, fostering truly collaborative behavior and scalable solutions for a wide range of societal problems.
Addressing the challenge of incentivizing desired behaviors in complex environments requires a departure from traditional reward structures. When agents operate within intricate systems, assigning clear and frequent rewards for every beneficial action proves impractical, if not impossible. Consequently, researchers are exploring innovative techniques such as reward shaping – crafting intermediate rewards to guide learning – and intrinsic motivation, where agents are rewarded for novelty or progress. Furthermore, approaches like credit assignment – determining which agent contributed to a collective success – are being refined to ensure fair and effective learning. These advancements aim to overcome the limitations of sparse rewards, enabling agents to learn efficiently and collaborate effectively even when immediate feedback is scarce, ultimately paving the way for robust multi-agent systems capable of tackling real-world challenges.
![The CTDE paradigm enables scalable multi-agent reinforcement learning by leveraging a centralized critic [latex]\mathbf{V}[/latex] with access to global state during training to guide decentralized actors [latex]\pi_{i}[/latex] that operate solely on local observations during execution.](https://arxiv.org/html/2603.24324v1/x3.png)
Automated Reward Design: A Logical Progression
Objective-Grounded Reward Search introduces a framework leveraging Large Language Models (LLMs) to automate the creation of reward programs for reinforcement learning agents. This process involves prompting LLMs with task objectives, which the model then translates into executable reward functions – termed ‘candidate programs’. These programs are not manually designed, but rather generated through the LLM’s understanding of the stated objectives. The framework differs from traditional reward engineering by shifting the focus from explicitly defining rewards to specifying desired outcomes, enabling a more scalable approach to reward design and potentially uncovering reward structures that might not be immediately apparent to human designers.
Large Language Models (LLMs) are utilized to automatically generate reward functions by interpreting high-level task objectives provided as input. This contrasts with traditional reward engineering, which relies on human experts to manually design and tune reward signals – a process that is both time-consuming and often limited by human bias or foresight. LLMs offer a scalable alternative by programmatically creating candidate reward functions based on the specified objectives, allowing for rapid iteration and exploration of a wider range of reward structures. The resulting functions are expressed as code, enabling direct integration into reinforcement learning environments for evaluation and refinement. This programmatic approach facilitates the creation of reward programs for complex tasks where defining effective rewards manually is challenging or impractical.
Validation of proposed reward programs, termed ‘Valid Candidate Programs’, is achieved through behavioral testing of an agent interacting within the target environment. This process involves deploying the candidate reward function and observing the resulting agent behavior over a defined period. Key metrics, such as task completion rate, efficiency, and adherence to safety constraints, are then recorded and analyzed. Significant deviations from desired behavior, or unintended consequences arising from the reward function, indicate a failed validation, prompting the system to either refine the reward program or discard it in favor of another candidate. This iterative testing and evaluation loop is crucial for ensuring the generated reward functions effectively incentivize the desired agent behavior.
Traditional reinforcement learning relies on reward functions meticulously crafted by human engineers, limiting exploration to pre-defined criteria. This methodology, however, constrains the potential for discovering novel or more efficient solutions. Utilizing Large Language Models to generate reward signals circumvents this limitation by enabling the system to propose reward functions not initially considered by humans. This allows for the investigation of a wider solution space, potentially uncovering reward structures that incentivize behaviors exceeding those explicitly programmed or anticipated, and facilitating the discovery of previously unknown strategies for task completion.
Training Agents with Automatically Designed Rewards: A Pragmatic Implementation
The Objective-Grounded Reward Search framework leverages MAPPO (Multi-Agent Proximal Policy Optimization), a policy gradient reinforcement learning algorithm, for training agents in multi-agent environments. MAPPO is an on-policy algorithm that utilizes a trust-region approach to update policies, ensuring stable learning through clipped surrogate objectives. Its architecture is specifically designed for decentralized execution with centralized training, enabling efficient learning of coordinated behaviors by allowing agents to share information during training but operate independently during deployment. The algorithm calculates policy gradients based on the collective experience of all agents and applies these gradients to update individual agent policies, fostering cooperative strategies and improving overall team performance.
Centralized Training, Decentralized Execution (CTDE) is a paradigm utilized to facilitate the learning of coordinated multi-agent behaviors. During training, a centralized critic has access to global state information, enabling it to accurately assess the joint actions of all agents and provide a comprehensive reward signal. However, at execution time, each agent operates independently using only its local observations, effectively decoupling the agents’ actions during deployment. This approach allows for the efficient learning of cooperative strategies by leveraging global information during training while maintaining scalability and responsiveness through decentralized action selection during operation.
The methodology converts automatically designed reward programs into agent policies by leveraging a multi-agent reinforcement learning approach. Specifically, the generated reward functions are utilized as inputs to the MAPPO algorithm during training. This allows each agent to learn a policy optimized for its individual actions while simultaneously considering the collective reward signal. The resulting policies are then deployed during execution in a decentralized manner, enabling agents to act independently based on their learned strategies without requiring central coordination during gameplay; this is facilitated by the CTDE paradigm.
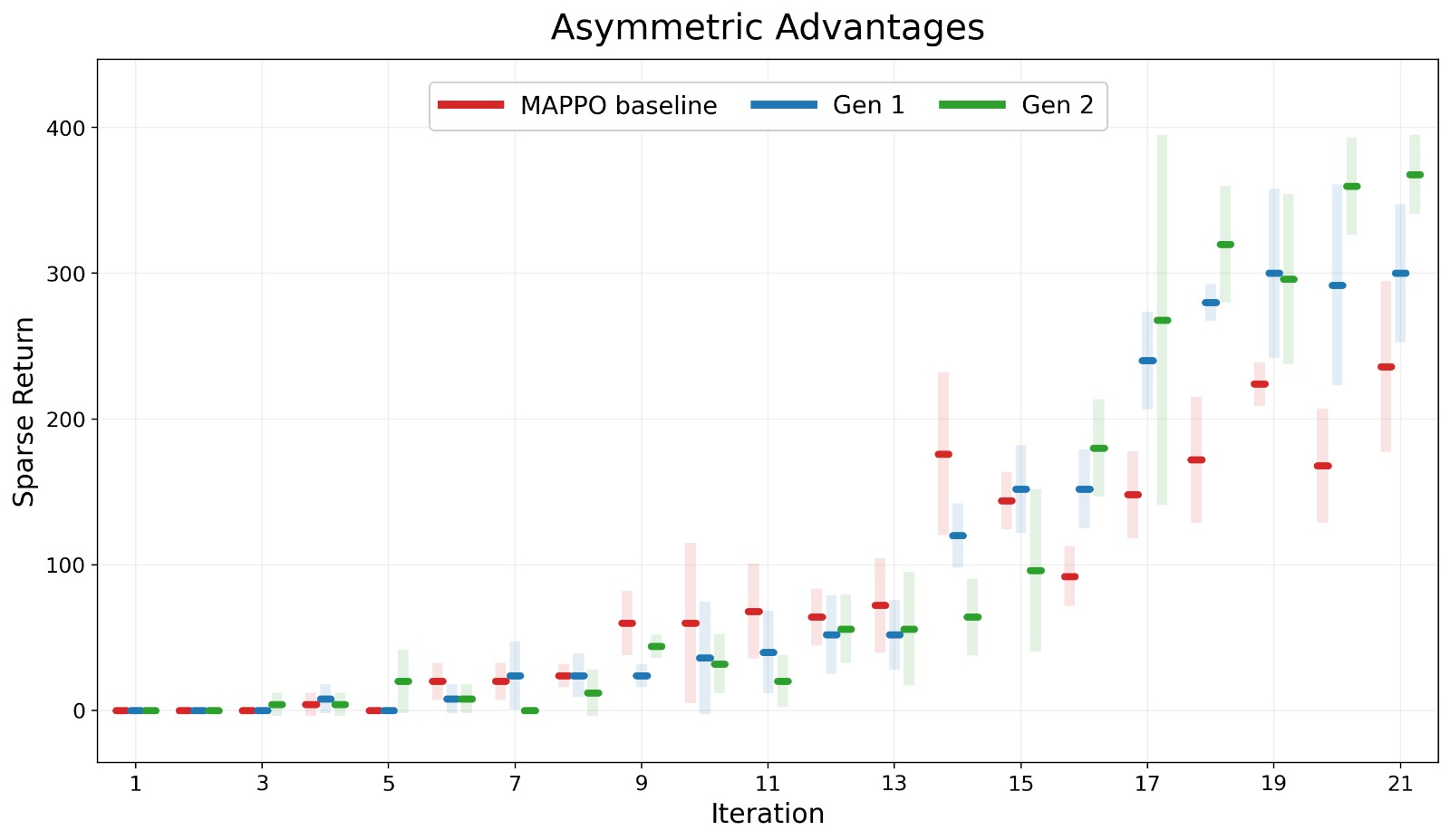
Performance evaluations using the Coordination Ring layout in Overcooked-AI demonstrate a substantial improvement in task completion with agents trained via automatically designed rewards. Generation 2 candidate agents achieved an average of 7.65 successful deliveries, representing a twelve-fold increase over the baseline agent’s 0.15 successful deliveries. This data indicates a significant capability gain in coordinating actions to achieve the objective within the specified environment.
Ensuring Effective Cooperation Through Incentive Alignment: The Core Principle
The success of multi-agent learning hinges on establishing a cohesive system where individual agent motivations contribute to a unified goal. When agents operate with misaligned incentives, competition and suboptimal outcomes frequently emerge, hindering overall performance. A carefully constructed framework, therefore, prioritizes the design of reward structures that encourage cooperative behaviors and discourage actions detrimental to the collective. This alignment isn’t simply about ensuring all agents receive rewards; it’s about shaping those rewards to reflect the value of collaborative effort and the shared success of the entire system, ultimately fostering interdependence and maximizing collective outcomes even in complex environments.
A critical challenge in multi-agent systems lies in mitigating payoff imbalances, where certain agents consistently accrue significantly higher rewards than others. Such disparities can actively discourage cooperation, as agents prioritizing individual gain may undermine collective efforts, even if a globally optimal solution exists. This system directly addresses this issue through a carefully constructed reward structure designed to equalize contributions and incentivize collaborative behavior. By preventing any single agent from dominating reward accumulation, the framework fosters a more equitable environment, encouraging all participants to contribute meaningfully to the shared objective. Consequently, this promotes sustained cooperation and unlocks substantial performance gains, particularly in complex environments where effective interaction is paramount.
Successfully fostering cooperation amongst multiple agents hinges on the meticulous crafting of reward programs. These programs must not only incentivize desired behaviors but also proactively mitigate potential pitfalls like disproportionate reward distribution, which can stifle collaborative efforts. A poorly designed reward system can inadvertently encourage selfish strategies or unintended consequences, undermining the overall objective; therefore, careful consideration must be given to the shaping signals provided to each agent. The aim is to create a positive feedback loop where cooperative actions are consistently reinforced, leading to emergent, synchronized behaviors and maximizing collective performance, particularly in environments where interaction and coordination are crucial for achieving sparse rewards.
Rigorous analysis of multi-agent learning dynamics reveals a notable increase in both action coupling – measured by Normalized Mutual Information (NMI) – and incentive alignment (ρ) across successive generations. This suggests that agents are not only becoming more interdependent in their actions, but also increasingly responsive to shared shaping signals, fostering genuine cooperation. Importantly, the implemented framework demonstrated a substantial improvement in performance, achieving up to a twelve-fold increase in sparse returns across diverse environmental layouts. These gains were particularly pronounced in interaction-bottlenecked environments, where effective coordination is crucial, highlighting the framework’s ability to overcome challenges inherent in complex, multi-agent systems and maximize collective reward through aligned incentives.
![Iterative training across Overcooked-AI layouts demonstrably improves agent coordination, as evidenced by increasing Action Coupling [latex]NMI[/latex], Incentive Alignment ρ, and decreasing Payoff Imbalance Δ from Baseline to Generation 2.](https://arxiv.org/html/2603.24324v1/figures/Introduction/ID_d.jpeg)
The pursuit of effective cooperative multi-agent reinforcement learning, as detailed in the article, hinges on crafting reward structures that incentivize desired behaviors. This echoes John McCarthy’s sentiment: “It is better to solve a problem correctly than to be fast.” The presented framework, leveraging large language models for objective-grounded reward search, prioritizes the correctness of the incentive design – ensuring agents are genuinely motivated towards cooperative goals – over simply achieving quick, potentially superficial, results. The method’s focus on aligning rewards with underlying objectives demonstrates a commitment to provable, rather than merely performative, coordination, a principle aligning with McCarthy’s emphasis on mathematical purity in problem-solving.
Future Directions
The automation of reward design, as demonstrated, represents a pragmatic step, yet obscures a fundamental truth: the elegance of a solution is not measured by the speed of its derivation, but by the consistency of its underlying principles. The current reliance on large language models, while yielding empirical improvements in multi-agent coordination, introduces a layer of inductive bias – the model’s ‘understanding’ of cooperation – that remains largely unexamined. Future work must address the provability of these learned reward structures, not simply their performance on benchmark tasks.
A critical limitation resides in the objective grounding itself. The paper frames cooperation through natural language, a representation inherently susceptible to ambiguity and imprecision. A truly robust framework would necessitate a formal specification of cooperative intent, independent of human linguistic interpretation. The pursuit of such a specification, while mathematically challenging, offers the potential for verifiable guarantees of agent behavior.
Ultimately, the field faces a choice: continue refining heuristics for reward shaping, or strive for a more axiomatic approach to multi-agent system design. The former offers incremental progress; the latter, a pathway towards algorithms that are not merely effective, but demonstrably correct. The consistency of the solution, not the speed of convergence, will define the ultimate measure of success.
Original article: https://arxiv.org/pdf/2603.24324.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- Physics Proved by AI: A New Era for Automated Reasoning
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Goddess of Victory: NIKKE 2×2 LOVE Mini Game: How to Play, Rewards, and other details
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- Total Football free codes and how to redeem them (March 2026)
- Gold Rate Forecast
- Nicole Kidman and Jamie Lee Curtis elevate new crime drama Scarpetta, which is streaming now
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-03-27 02:09