Author: Denis Avetisyan
A new data system integrates the power of large language models directly into SQL databases to dramatically improve semantic query processing and performance.
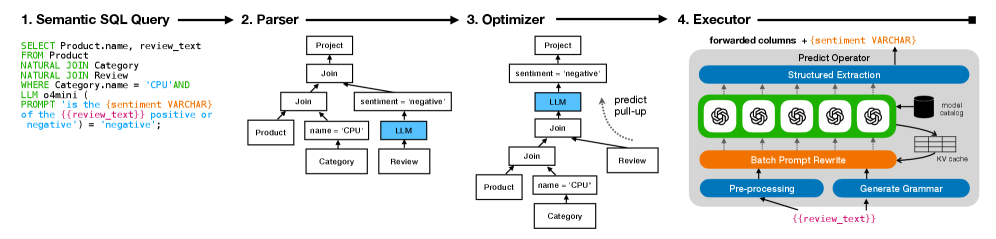
iPDB extends SQL with ML and LLM predicates to enable efficient evaluation of semantic queries within a relational data system.
Despite the enduring efficiency of SQL for structured data, modern applications increasingly demand the integration of learned models for complex tasks, yet existing systems struggle to efficiently leverage these models within relational databases. This paper introduces iPDB — Optimizing SQL Queries with ML and LLM Predicates, a novel relational system that extends SQL to natively support in-database machine learning and large language model inferencing. iPDB enables semantic query processing by introducing a relational predict operator and optimizations that allow LLMs and ML models to function as predicates within SQL queries. Could this approach unlock a new paradigm for data systems, seamlessly blending the strengths of relational algebra with the power of learned intelligence?
The Inherent Limitations of Textual Correspondence
Conventional Structured Query Language (SQL) databases operate on a principle of strict textual correspondence, demanding queries mirror data entries precisely to return results. This rigidity presents a significant obstacle to extracting meaningful insights, as subtle variations in phrasing, synonymous terms, or implied context can render a query fruitless, even when the underlying intent is clear. Consequently, a wealth of potentially valuable information remains locked within datasets, inaccessible through simple keyword searches. The limitations of exact-match queries are particularly pronounced with complex or evolving datasets, where nuanced understanding, rather than literal string matching, is essential for uncovering patterns and driving informed decision-making. This dependence on precise wording effectively creates a barrier between data and understanding, hindering the potential of data-driven exploration.
Contemporary data analysis increasingly prioritizes extracting meaningful insights, driving a fundamental shift in how information is accessed. No longer sufficient are queries that rely on precise keyword matches; instead, systems must decipher the underlying intent behind a request. This evolution stems from the recognition that human language is inherently ambiguous and nuanced, and that valuable data often resides not in what is explicitly stated, but in what is implied. Consequently, the focus is moving towards semantic queries – those capable of understanding the meaning of a question, rather than simply locating corresponding strings – unlocking a far richer and more comprehensive understanding of complex datasets and facilitating more effective decision-making.
The limitations of traditional data querying become strikingly apparent when applied to unstructured and semi-structured data – think text documents, social media feeds, or log files. These formats lack the rigid schema of relational databases, meaning exact keyword matches often yield irrelevant or incomplete results. A query seeking “customer complaints about delivery” might return mentions of deliveries generally, or complaints about product quality – failing to pinpoint the specific issues. The inherent ambiguity within natural language, coupled with the varied ways information is expressed, necessitates a more sophisticated approach. Conventional methods struggle to discern the meaning behind the data, hindering the ability to extract actionable insights from the vast quantities of information stored in these non-traditional formats, and driving the need for semantic query understanding.
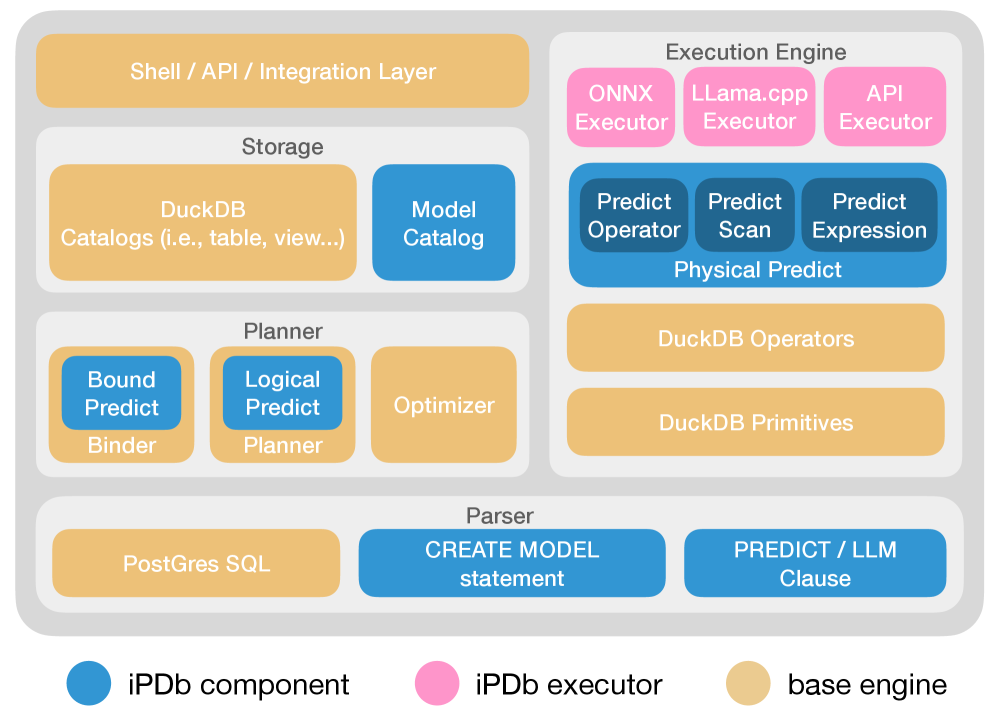
iPDB: A Logical Extension of SQL Through LLM Inference
iPDB introduces a novel approach to database querying by directly embedding Large Language Model (LLM) inference within SQL operations. This integration allows for the execution of semantic operations – tasks that interpret the meaning of data rather than relying on exact matches. Rather than modifying the underlying SQL language, iPDB extends it by enabling the invocation of LLM functions from within SQL queries, treating the LLM as a first-class citizen within the database system. This capability allows users to perform operations such as fuzzy matching, natural language-based filtering, and semantic joins directly within their SQL queries, broadening the scope of analytical possibilities beyond traditional relational algebra.
iPDB facilitates semantic joins and filtering through the application of Large Language Models (LLMs) to database queries. Traditional SQL relies on exact matches for data retrieval, requiring fields to be identical for a join or filter to succeed. iPDB, however, uses LLMs to assess the meaning of data, enabling joins and filters based on conceptual similarity rather than strict equality. This means that fields containing paraphrases, synonyms, or related concepts can be matched, expanding query results beyond those achievable with conventional SQL. The LLM evaluates the semantic relationship between data points, determining if a match exists based on contextual understanding, and allowing for more flexible and insightful data analysis.
iPDB utilizes DuckDB as its underlying database engine to ensure high performance for analytical queries. DuckDB is an in-process SQL OLAP database management system designed for efficient execution of analytical workloads, particularly on large datasets. Its in-process architecture minimizes overhead by eliminating the need for client-server communication, and its columnar storage format and vectorized execution engine optimize query processing speed. DuckDB supports standard SQL and offers features such as automatic query optimization and efficient data compression, contributing to iPDB’s ability to rapidly execute both traditional SQL and LLM-augmented queries.
Empirical Validation: Performance Gains Through Optimization
iPDB reduces Large Language Model (LLM) call overhead through techniques such as multi-row prompt marshaling and prompt deduplication. Multi-row prompt marshaling combines multiple data rows into a single prompt sent to the LLM, amortizing the cost of the LLM call setup and reducing the total number of requests. Prompt deduplication identifies and eliminates redundant prompts generated from similar data, preventing unnecessary LLM invocations. These optimizations directly minimize communication costs and processing time associated with LLM interactions, improving overall system efficiency.
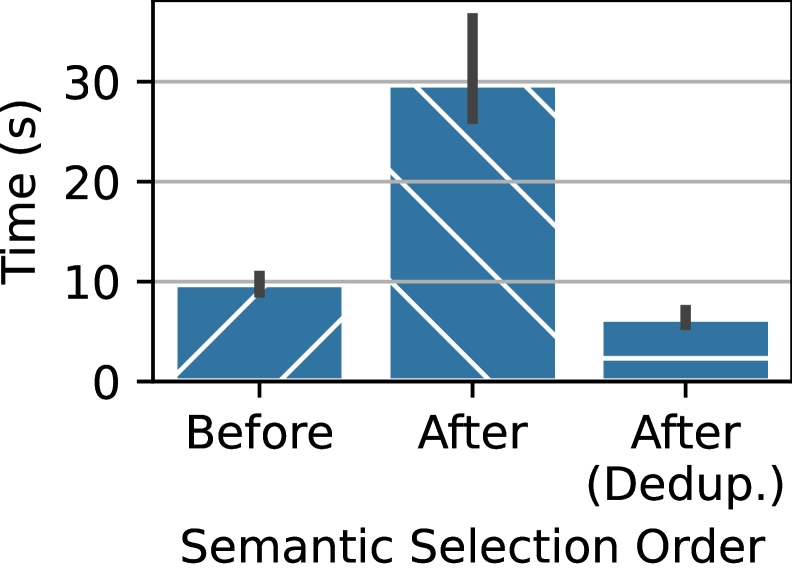
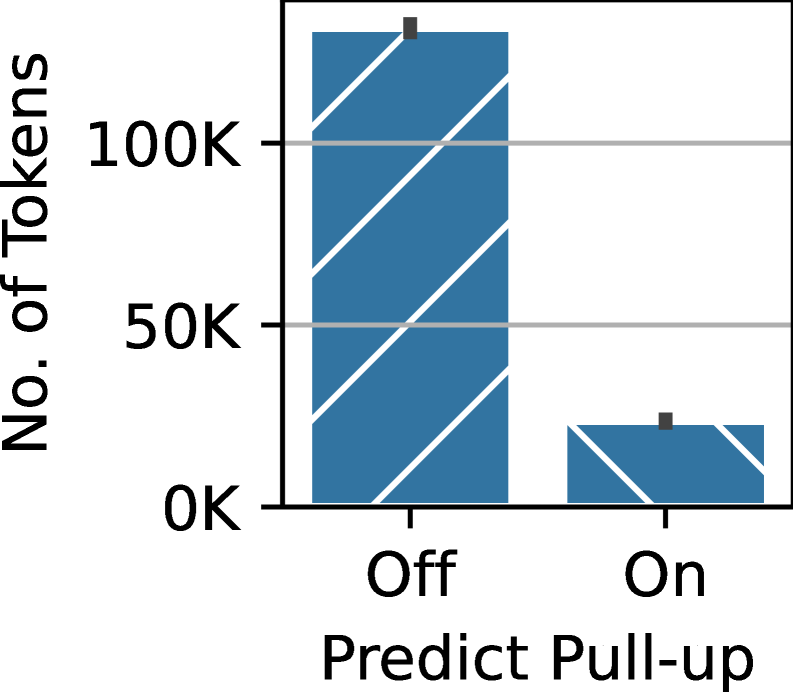
Predict Pull-up is a logical query optimization technique that restructures semantic queries to prioritize operations performed on the data source rather than transmitting large volumes of raw data to the Large Language Model (LLM). This involves identifying LLM operations that can be expressed as filters or transformations applicable to the underlying data. By ‘pulling up’ these operations and executing them within the data source’s environment, the amount of data transferred to the LLM is substantially reduced. This minimizes network latency and processing load on the LLM, leading to faster query response times and improved scalability, particularly for datasets where filtering significantly reduces the data volume.
Evaluations of the iPDB system demonstrate performance improvements of up to 1000x in semantic query processing when compared to existing state-of-the-art systems. This performance gain is the result of combined optimizations including multi-row prompt marshaling, prompt deduplication, and logical query rewriting via techniques such as ‘Predict Pull-up’. Benchmarks were conducted using a standardized dataset and query load, and measured the end-to-end latency of semantic query execution, showing a consistent and significant reduction in processing time with iPDB.
Expanding Analytical Capabilities: Semantic Operators and Adaptive Models
iPDB elevates data interaction beyond traditional keyword-based searches with the introduction of semantic operators, notably ‘Semantic Join’ and ‘Semantic Select’. These operators facilitate queries grounded in meaning, rather than strict matching of terms, allowing users to express complex requests in a more natural and intuitive manner. ‘Semantic Join’ intelligently combines data from disparate sources based on conceptual relationships, even if explicit links aren’t present, while ‘Semantic Select’ refines results by understanding the intent behind a query, identifying information that is conceptually relevant even if the phrasing differs. This capability moves beyond simple data retrieval, enabling iPDB to perform tasks akin to reasoning and inference, ultimately delivering more insightful and accurate responses to user needs.
The architecture incorporates a comprehensive Model Catalog, functioning as a dynamic registry of large language models (LLMs). This catalog doesn’t simply store models; it actively tracks their performance characteristics, capabilities, and associated costs. Users are empowered to select the LLM best suited for a given query, moving beyond a one-size-fits-all approach. The system facilitates experimentation and optimization by allowing comparison of different models on the same task, ultimately improving query accuracy and resource efficiency. This granular control over LLM selection is crucial for adapting to evolving data types and the nuanced demands of complex semantic queries, ensuring the system remains versatile and performs optimally across diverse applications.
The precision of queries powered by large language models hinges significantly on skillful prompt engineering and meticulous data type extraction. Simply phrasing a question is often insufficient; crafting prompts that provide clear context, specify desired output formats, and guide the LLM’s reasoning process dramatically improves result accuracy. Simultaneously, the system must accurately identify and categorize data types – distinguishing, for example, between numerical values, dates, and textual information – to perform appropriate operations and avoid misinterpretations. Without these dual focuses – a well-defined query and correctly parsed data – even the most sophisticated LLM can generate unreliable or nonsensical responses, underscoring their combined importance in building trustworthy and effective semantic query systems.
Towards a Future of Intuitive Data Access: Democratizing Insight
iPDB represents a significant leap towards democratizing data access through a novel architectural design that prioritizes natural language interaction. Traditionally, querying databases required specialized knowledge of structured query languages like SQL, creating a barrier for many potential users. iPDB bypasses this requirement by enabling individuals to pose questions using everyday language, which the system then intelligently translates into executable database queries. This is achieved through a carefully constructed framework that combines the strengths of large language models with the precision of database systems, allowing for a more intuitive and efficient data exploration process. The result is a paradigm shift, where accessing and understanding data becomes as simple as asking a question, fostering broader data literacy and empowering a wider range of users to derive valuable insights.
The architecture of this system is intentionally designed for continuous improvement and adaptation, prioritizing extensibility to accommodate future advancements in large language models (LLMs) and semantic operators. This modularity allows for seamless integration of novel LLMs as they emerge, ensuring the system benefits from ongoing improvements in natural language understanding and generation. Furthermore, the ability to incorporate new semantic operators – functions that refine and expand the system’s analytical capabilities – guarantees it can address increasingly complex data queries and evolving user needs. This forward-looking design isn’t simply about keeping pace with innovation; it’s about actively shaping the future of data interaction, establishing a platform that remains at the cutting edge of what’s possible with data analysis and interpretation.
iPDB fundamentally alters how individuals interact with data by dissolving the traditional barrier between structured query language and large language models. Previously, extracting meaningful insights required proficiency in SQL, limiting access to data-driven decision-making for many. iPDB bypasses this constraint, allowing users to pose questions in everyday language which the system then translates into precise SQL queries. This seamless conversion unlocks the full potential of existing databases, enabling a broader range of individuals to explore data, identify trends, and derive actionable intelligence. Consequently, organizations can foster a more data-literate culture, empowering employees at all levels to contribute to strategic initiatives and improve overall outcomes through informed decision-making.
The pursuit of predictable and reproducible results, central to iPDB’s design, echoes a fundamental tenet of robust system construction. The system’s integration of LLM predicates within the relational algebra framework isn’t merely about enhancing query capabilities; it’s about subjecting those capabilities to the rigor of deterministic evaluation. As Vinton Cerf aptly stated, “If it’s not reproducible, it’s not reliable.” iPDB strives for this reliability by grounding LLM inference within the established rules of relational databases, ensuring that semantic query processing, while leveraging the power of large language models, remains verifiable and consistent. This dedication to determinism allows for the construction of data systems capable of consistently delivering accurate and trustworthy results.
What Lies Ahead?
The integration of large language models into established relational systems, as demonstrated by iPDB, is not merely an engineering feat, but a philosophical challenge. The system correctly identifies that the true power lies not in replacing relational algebra, but in augmenting it. However, the current paradigm still relies on translating semantic intent into a format digestible by the database-a necessary, but ultimately clumsy, intermediary. A genuine advancement will necessitate a re-evaluation of the fundamental query processing model itself. Can a database natively ‘understand’ a predicate, without reduction to boolean expressions?
Current approaches, while effective, remain tethered to the limitations of LLM generalization. The ‘predict’ operator, for all its elegance, inherits the inherent uncertainty of the models it employs. A critical area for future research lies in the development of mechanisms for quantifying and propagating this uncertainty through the relational algebra – a task far more complex than simply achieving a high accuracy score on benchmark datasets. The pursuit of ‘correctness’ demands more than statistical validation; it requires a formal understanding of model limitations.
Ultimately, the true test of this line of inquiry will not be in processing increasingly complex semantic queries, but in achieving a demonstrable reduction in logical ambiguity. Simplicity is not brevity; it is non-contradiction. The elegance of a solution is measured not by its performance on contrived examples, but by its provable consistency – a standard to which all data systems should aspire.
Original article: https://arxiv.org/pdf/2601.16432.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Only One Straw Hat Hasn’t Been Introduced In Netflix’s Live-Action One Piece
2026-01-27 05:54