Author: Denis Avetisyan
Researchers have developed a new approach that blends predictive control with reinforcement learning to enable safer, more efficient navigation for teams of robots in challenging environments.

CoRL-MPPI combines Model Predictive Path Integral control with learned behaviors to provide provably-safe and robust decentralized multi-robot collision avoidance.
Decentralized multi-robot systems face a fundamental trade-off between scalability and collision avoidance, often relying on computationally expensive or theoretically limited approaches. This paper introduces ‘CoRL-MPPI: Enhancing MPPI With Learnable Behaviours For Efficient And Provably-Safe Multi-Robot Collision Avoidance’, a novel framework that integrates Cooperative Reinforcement Learning with Model Predictive Path Integral (MPPI) control to address this challenge. By learning local cooperative behaviors and biasing MPPI’s sampling distribution, CoRL-MPPI significantly improves navigation efficiency and safety while preserving crucial theoretical guarantees. Could this fusion of learning and optimization unlock truly robust and scalable multi-robot navigation in increasingly complex environments?
Decoding the Swarm: The Limits of Centralized Control
Increasingly complex tasks demand multi-robot collaboration within shared workspaces, necessitating coordinated actions and robust collision avoidance. Traditional centralized approaches, while conceptually simple, struggle with scalability and introduce single points of failure. As the number of robots grows, computational burden escalates exponentially. Decentralized methods offer a solution by distributing the load and eliminating this critical vulnerability.
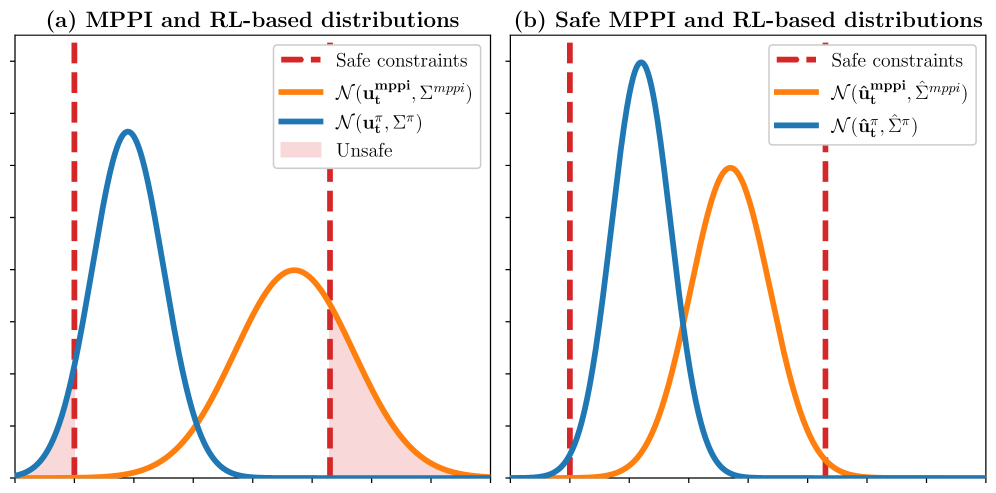
Effective operation in dynamic environments requires robustness to uncertainty and adaptability. Approaches based on distributed estimation and prediction are gaining prominence, allowing robots to anticipate the actions of others and proactively avoid collisions. Every system reveals its weaknesses under scrutiny.
CoRL-MPPI: Bridging Reinforcement Learning and Optimized Control
CoRL-MPPI synergistically combines reinforcement learning and Model Predictive Path Integral (MPPI) control to overcome the limitations of each technique. This hybrid approach addresses adaptation to dynamic environments and computational efficiency. Integrating a pre-trained reinforcement learning policy within the MPPI framework accelerates adaptation and improves performance by providing informed initial actions and a value function, effectively shaping the search space and accelerating convergence.
This architecture allows each robot to make informed decisions while leveraging MPPI’s optimization capabilities, enabling high-level strategic choices refined through trajectory optimization for robustness and precision. The result is an enhanced system exhibiting improved adaptability and efficiency.
Swarm Success: Performance and Efficiency Gains
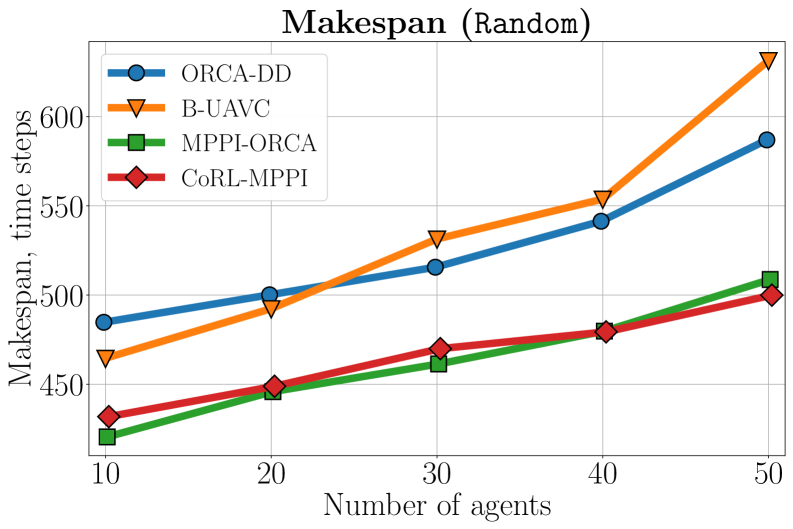
Experiments demonstrate that CoRL-MPPI significantly improves multi-robot task completion, achieving 100% success in Random and Circle scenarios, indicating robust coordination in simpler environments. In the challenging Mesh (Dense) scenario, CoRL-MPPI solved over 99% of tasks, exhibiting adaptability in complex, crowded spaces, surpassing many existing algorithms.
Critically, CoRL-MPPI provides formal safety assurances and demonstrates nearly 2x makespan improvement compared to MPPI-ORCA in dense scenarios. This combination of safety and efficiency positions CoRL-MPPI as a promising solution for applications where both are paramount.
The pursuit of provably-safe multi-robot collision avoidance, as detailed in this work, echoes a fundamental principle: understanding limitations through rigorous testing. The framework’s combination of Model Predictive Path Integral control and Reinforcement Learning isn’t merely about achieving a functional system, but actively probing the boundaries of what’s possible. As Bertrand Russell observed, “The difficulty lies not so much in developing new ideas as in escaping from old ones.” This resonates with CoRL-MPPI’s approach; it moves beyond traditional, potentially brittle control methods by learning adaptive behaviors, effectively escaping the limitations of pre-programmed responses and embracing a more flexible, robust solution in dynamic environments. The learned behaviours, tested and refined through simulation and potentially real-world implementation, reveal the true scope of safe and efficient cooperative navigation.
Beyond the Avoidance: Charting Future Trajectories
The integration of learned behaviors into a traditionally analytical framework—as demonstrated by CoRL-MPPI—reveals a predictable truth: safety isn’t a static property, but a dynamically negotiated compromise. The current work establishes a functional synergy, yet the implicit assumptions deserve scrutiny. What constitutes ‘complex’ environments? How does the learned policy generalize beyond the training regime, and what unforeseen consequences might arise from that extrapolation? The pursuit of provable safety often necessitates simplifying the world; the real world rarely reciprocates.
Future iterations should aggressively challenge the boundaries of decentralization. Complete decentralization is, after all, a theoretical ideal. Exploring hybrid approaches—where limited, carefully curated information is shared—could unlock efficiencies without sacrificing robustness. Furthermore, the focus invariably lands on collision avoidance. A more ambitious goal lies in proactive shaping of the environment, allowing robots to not merely react to obstacles, but to subtly influence their distribution—a sort of robotic terraforming, if you will.
Ultimately, this line of inquiry isn’t about building ‘safe’ robots, but about understanding the limits of predictability itself. Every successful avoidance maneuver is merely a temporary reprieve from the inevitable chaos. The true test will be how the system responds when—not if—those limits are breached.
Original article: https://arxiv.org/pdf/2511.09331.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- Best Arena 9 Decks in Clast Royale
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Country star who vanished from the spotlight 25 years ago resurfaces with viral Jessie James Decker duet
- How to find the Roaming Oak Tree in Heartopia
- M7 Pass Event Guide: All you need to know
- Solo Leveling Season 3 release date and details: “It may continue or it may not. Personally, I really hope that it does.”
- Kingdoms of Desire turns the Three Kingdoms era into an idle RPG power fantasy, now globally available
2025-11-13 13:22