Author: Denis Avetisyan
A new hybrid architecture empowers on-device audio systems to intelligently offload complex queries to the cloud, boosting accuracy while preserving user privacy.
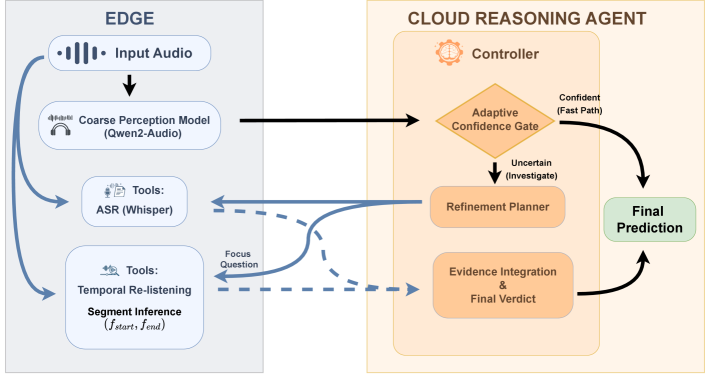
This work introduces CoFi-Agent, a coarse-to-fine reasoning framework leveraging adaptive gating for efficient and private on-device audio processing.
Deploying sophisticated audio analysis on edge devices presents a fundamental tension between computational efficiency and perceptual depth. This is addressed in ‘Bridging the Perception Gap: A Lightweight Coarse-to-Fine Architecture for Edge Audio Systems’, which introduces CoFi-Agent, a hybrid edge-cloud system that selectively refines uncertain audio perceptions using on-device tools. By initially performing fast local analysis and conditionally escalating complex cases, CoFi-Agent achieves significant accuracy gains on benchmarks like MMAR while minimizing latency and preserving acoustic privacy. Could this adaptive gating approach unlock truly intelligent and resource-conscious audio reasoning at the edge?
Decoding the Signal: The Limits of Current Acoustic Reasoning
Current methods for interpreting audio frequently rely on multi-stage processing pipelines – feature extraction, modeling, and classification – each demanding significant computational resources. This reliance creates a bottleneck for real-time applications like voice-activated devices or immediate environmental analysis. The sheer volume of data inherent in audio signals, combined with the complexity of algorithms used to decipher them, often necessitates offloading processing to remote servers – the cloud. While effective, this introduces latency and dependence on network connectivity, limiting functionality in areas with poor or no internet access. Consequently, a key challenge lies in developing more efficient acoustic reasoning systems capable of performing complex audio analysis directly on the device, minimizing computational load and eliminating the need for constant cloud dependence.
The pursuit of robust acoustic reasoning necessitates a delicate balance between computational efficiency and analytical precision. Current approaches often stumble when confronted with the intricacies of real-world soundscapes, requiring substantial processing power to discern meaningful information from noisy signals. Researchers are actively developing novel algorithms and hardware architectures designed to overcome these limitations, focusing on techniques like sparse signal representation and neuromorphic computing. These innovations aim to enable devices to interpret audio with human-like speed and accuracy, even in challenging acoustic environments, opening doors to applications ranging from real-time voice control and environmental monitoring to advanced robotics and assistive technologies – all without reliance on constant cloud connectivity.
![Adaptive gating demonstrates a superior accuracy-efficiency trade-off on the MMAR benchmark [latex] (N=1,000) [/latex] compared to consistently active investigation.](https://arxiv.org/html/2601.15676v1/x1.png)
CoFi-Agent: A Hybrid Approach to Acoustic Intelligence
CoFi-Agent utilizes a hybrid architecture distributing audio reasoning tasks between on-device and cloud-based processing units. This approach allows for initial, low-latency analysis to be performed locally, reducing reliance on network connectivity and minimizing response times. More complex reasoning, requiring greater computational resources, is then offloaded to the cloud. This division of labor optimizes both speed and accuracy by strategically allocating tasks to the most suitable processing environment, enabling efficient handling of varied audio inputs and complex analytical demands.
The CoFi-Agent utilizes a coarse-to-fine strategy for audio reasoning, beginning with a computationally inexpensive initial analysis to quickly identify potentially relevant segments. This preliminary pass informs whether more intensive processing is required; if so, the system escalates to a more complex analysis stage leveraging cloud resources. On the MMAR benchmark, this approach achieves a nearly 2x improvement in accuracy compared to a single-pass execution of a 7B parameter local model, demonstrating the efficacy of dynamic complexity allocation for improved performance and efficiency.
Inside the Machine: How CoFi-Agent Processes Sound
CoFi-Agent’s initial audio processing relies on two core on-device components: Qwen2-Audio-7B-Instruct, an Audio-LLM, and Whisper, an Automatic Speech Recognition (ASR) system. Qwen2-Audio-7B-Instruct is utilized for direct audio understanding, while Whisper transcribes the audio into text. This on-device processing allows for preliminary analysis without requiring data transmission, enhancing both privacy and speed. The outputs from both systems are then combined to form the basis for subsequent stages of analysis within CoFi-Agent, providing a foundational understanding of the audio content.
Following initial audio processing, the Segment Proposer component isolates portions of the audio stream deemed potentially relevant to the user query. This is achieved through analysis of acoustic features and preliminary transcriptions. Subsequently, the Confidence Gate assesses the ambiguity of the Segment Proposer’s output, evaluating the reliability of the initial analysis based on metrics such as transcription confidence scores and acoustic event detection certainty. This evaluation determines whether the query can be directly addressed or requires further investigation, contributing to the system’s adaptive gating strategy and influencing the decision to escalate the query for more complex processing.
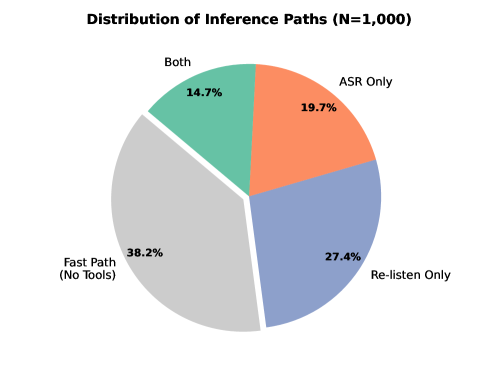
CoFi-Agent employs Adaptive Gating to manage query uncertainty through two primary mechanisms: Temporal Re-listening and tool augmentation. Approximately 62% of initial queries are escalated to a dedicated investigation path when the system identifies ambiguity. Of these escalated samples, Temporal Re-listening, which re-examines audio context surrounding the query, accounts for 27.4%. This process, combined with the utilization of external tools, allows CoFi-Agent to address complex or uncertain queries that require further analysis beyond the initial on-device processing.
Beyond the Benchmark: Implications for a Smarter, More Private Future
Evaluations conducted on the challenging MMAR Benchmark reveal CoFi-Agent’s substantial capabilities in complex audio reasoning. The system achieved an impressive 53.60% accuracy, demonstrating a significant leap in performance – nearly double that of a comparable single-pass local 7B model. This result highlights CoFi-Agent’s ability to not merely transcribe audio, but to genuinely understand and reason about the information contained within, paving the way for more sophisticated and reliable audio-based applications. The benchmark success indicates a robust system capable of handling nuanced audio data and extracting meaningful insights, exceeding the limitations of simpler, single-pass models.
CoFi-Agent’s design prioritizes data privacy through a fundamental principle of minimization. By executing a substantial portion of audio reasoning locally on the device, the system significantly reduces the need to transmit sensitive audio data to cloud servers for processing. This inherent characteristic not only bolsters user privacy but also addresses growing concerns surrounding data security and compliance. The architecture effectively confines data handling to the point of origin whenever possible, diminishing the potential attack surface and limiting the scope of data exposure, ultimately providing a more secure and user-centric approach to audio AI.
The efficiency of CoFi-Agent is demonstrated by its ability to resolve a significant portion of audio-based tasks – 38.2% – directly, without requiring external tools. When more complex reasoning is needed, tool augmentation proves effective, with Automatic Speech Recognition (ASR) assisting in 19.7% of cases and combined tool use covering an additional 14.7% of escalated samples. This streamlined processing capability positions CoFi-Agent as a viable solution for latency-sensitive applications, particularly in the realms of accessibility – offering real-time transcription and assistance – and the Internet of Things, where immediate audio analysis can enhance device responsiveness and user experience.
The pursuit of efficient on-device audio processing, as demonstrated by CoFi-Agent, necessitates a willingness to challenge conventional architectural boundaries. Every exploit starts with a question, not with intent. Robert Tarjan’s sentiment echoes the core principle behind this work: selectively offloading complex queries to the cloud isn’t about admitting defeat, but rather about strategically probing the limits of on-device capability. This targeted refinement, facilitated by adaptive gating, exemplifies a system designed not merely to function, but to understand where its limitations lie, mirroring an inquisitive approach to problem-solving. The architecture inherently tests the boundary between local and remote processing, optimizing for both accuracy and acoustic privacy.
What’s Next?
The CoFi-Agent architecture, while demonstrating a pragmatic approach to resource constraints, merely postpones the inevitable reckoning with fundamental limits. Selective query escalation functions as a sophisticated form of controlled failure; the system admits uncertainty, but only to outsource its resolution. The true challenge isn’t refining accuracy, but redefining what constitutes ‘sufficient’ understanding given inherently noisy data and limited computational budgets. Every patch is a philosophical confession of imperfection.
Future work will undoubtedly focus on minimizing the cloud dependency – pushing more of the ‘refinement’ process onto the edge. However, a more fruitful, if unsettling, direction lies in embracing ambiguity. Can models be designed to profit from uncertainty, to generate robust, if approximate, solutions even with incomplete information? The best hack is understanding why it worked.
Ultimately, the pursuit of ‘intelligent’ audio processing isn’t about achieving perfect transcription or flawless command recognition. It’s about building systems that can convincingly simulate understanding, even when operating on the fringes of comprehension. The elegance, it seems, will reside not in eliminating error, but in mastering its illusion.
Original article: https://arxiv.org/pdf/2601.15676.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- Gold Rate Forecast
- Invincible Creator on Why More Spin-offs Haven’t Happened Yet
- American Idol vet Caleb Flynn in solitary confinement after being charged for allegedly murdering wife
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- Olivia Colman’s highest-rated drama hailed as “exceptional” is a must-see on TV tonight
2026-01-25 23:58