Author: Denis Avetisyan
A new approach allows robots to dynamically adjust their processing power during tasks, achieving significant efficiency gains without compromising performance.
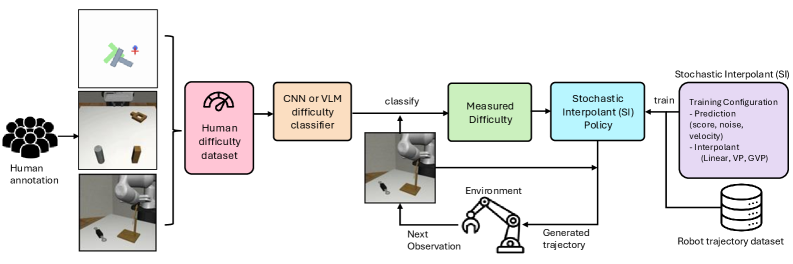
This work introduces a Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) for adaptive computation in robot control, leveraging task difficulty classification and generative models.
While diffusion- and flow-based policies excel in complex robotic manipulation, their fixed computational budget at each step introduces inefficiency and potential underperformance across varying task complexities. This work introduces ‘Dynamic Test-Time Compute Scaling in Control Policy: Difficulty-Aware Stochastic Interpolant Policy’, a framework that dynamically adjusts inference based on real-time difficulty classification. By adaptively allocating computational resources, our Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) achieves significant speedups-2.6-4.4x reduction in compute time-without compromising task success. Could this approach unlock a new era of efficient, task-aware robot controllers capable of intelligently optimizing resource allocation for maximum benefit?
Decoding the Limits of Robotic Control
Conventional robotic control systems frequently encounter difficulties when operating within unpredictable, real-world settings. These systems are typically engineered for structured environments and pre-defined tasks, exhibiting limited capacity to respond effectively to unanticipated obstacles or changes in conditions. This inflexibility stems from a reliance on precise models of the robot and its surroundings; however, such models are often inaccurate or incomplete when faced with the inherent variability of dynamic environments. Consequently, robots struggle with tasks requiring improvisation, adaptation, and the ability to generalize learned behaviors to novel situations-a significant impediment to their widespread deployment beyond controlled industrial settings. The need for robots capable of navigating and interacting seamlessly with complex, changing environments remains a central challenge in the field of robotics.
Current robotic policies, frequently honed in carefully controlled laboratory settings, demonstrate a surprising fragility when confronted with the unpredictable nature of real-world environments. While a robot might flawlessly execute a task – such as grasping an object – within its training parameters, even minor deviations, like changes in lighting, surface texture, or the introduction of unexpected obstacles, can lead to catastrophic failures. This lack of robustness stems from an over-reliance on precise sensor data and pre-programmed responses; the systems often struggle to generalize beyond the specific conditions they were designed for. Consequently, deploying these policies in dynamic, unstructured spaces – warehouses, homes, or disaster zones – proves remarkably difficult, highlighting a critical need for control strategies capable of adapting to unforeseen circumstances and maintaining reliable performance even under significant disturbances.
Effective robotic control fundamentally relies on the ability to anticipate the immediate consequences of actions and the evolving state of the environment, but achieving accurate state prediction presents a considerable hurdle. Current systems often struggle with the inherent uncertainties of real-world dynamics – unpredictable friction, unexpected obstacles, or the nuanced behavior of interacting objects. While sophisticated algorithms can model simplified scenarios, their performance degrades rapidly when faced with novel or complex situations. This limitation stems from the difficulty in creating comprehensive models that capture the infinite possibilities within a dynamic environment and the computational demands of processing the vast amount of sensory data required for reliable prediction. Consequently, robots frequently react to events rather than proactively planning based on anticipated outcomes, hindering their ability to perform complex tasks with the fluidity and adaptability expected of intelligent agents.

DA-SIP: A Framework for Intelligent Adaptation
Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) integrates the advantages of both flow-based and diffusion-based generative modeling techniques. Flow-based models, such as normalizing flows, offer efficient and invertible mappings, enabling rapid sampling and exact likelihood computation. However, they can struggle with complex, multi-modal distributions. Diffusion models, conversely, excel at modeling intricate distributions through a process of gradually adding and removing noise, but typically require significant computational resources for sampling. DA-SIP leverages normalizing flows to provide a computationally efficient base policy and then refines this policy using a diffusion process, focusing computational effort on areas where the flow-based policy is less certain. This hybrid approach aims to balance sampling speed with the ability to accurately represent complex state spaces and policy distributions.
The Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) incorporates a difficulty classifier that analyzes incoming task or state data to quantify its inherent complexity. This classifier, trained to predict the computational resources required for accurate policy execution, outputs a scalar value representing the assessed difficulty. This value then directly modulates the computational graph of the policy network; more difficult states trigger increased computation, while simpler states allow for reduced processing. The classifier utilizes features extracted from the state representation and is trained alongside the policy network using a combined loss function that optimizes both policy performance and classification accuracy, thereby enabling a dynamic allocation of computational resources based on real-time task demands.
The Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) achieves significant computational savings by dynamically allocating resources based on task complexity. Specifically, the system assesses the difficulty of a given state and adjusts its computational effort accordingly; in testing, this resulted in a demonstrated reduction of 2.6x to 4.4x in computational cost when contrasted with a baseline requiring maximum compute for all states. This adaptive resource allocation allows DA-SIP to maintain performance while substantially decreasing the overall computational demands, particularly beneficial in resource-constrained environments or when real-time control is critical.
The adaptive nature of DA-SIP facilitates robust control in dynamic and uncertain environments by modulating computational expenditure based on task complexity. The system’s difficulty classifier continuously evaluates state or task demands, and consequently allocates resources accordingly. This dynamic allocation ensures consistent performance across a range of conditions without requiring a fixed, maximum computational commitment. Empirical results demonstrate a $2.6x$ to $4.4x$ reduction in computational cost while maintaining control stability, indicating improved efficiency and resilience to environmental variations and unpredictable events.

Dissecting Task Difficulty: A Multi-Modal Approach
The difficulty classifier employs a multi-faceted approach to task assessment, integrating Convolutional Neural Networks (CNNs), Few-Shot Visual Language Models (VLMs), and Fine-Tuned VLMs. CNNs provide robust feature extraction based on image data, while Few-Shot VLMs leverage limited examples to generalize to unseen tasks. Fine-Tuned VLMs further refine performance by adapting to the specific characteristics of the task distribution. Combining these techniques allows for a more comprehensive and nuanced evaluation of task difficulty than any single method could provide, enabling a more accurate determination of the appropriate level of generative policy adaptation.
The integration of Gaussian Noise into the feature extraction processes of the CNN, Few-Shot VLM, and Fine-Tuned VLM models serves to enhance robustness and generalization performance. This technique introduces random noise, sampled from a Gaussian distribution, during the training phase. By exposing the models to slightly perturbed inputs, the system learns to be less sensitive to minor variations in the input data, effectively mitigating overfitting and improving performance on unseen data. This noise injection encourages the models to focus on the most salient features, leading to more stable and reliable feature representations and improved adaptability across diverse scenarios.
Performance evaluations of task difficulty classification methods indicate that the adaptive Convolutional Neural Network (CNN) classifier exhibits a minimal performance difference of 1.3%. In contrast, Few-Shot Visual Language Models (VLMs) demonstrated a 4.7% performance difference, and Fine-Tuned VLMs showed a 1.8% difference when assessing task difficulty. These results, derived from comparative analysis, suggest the adaptive CNN classifier offers a more consistent and stable performance metric for gauging task complexity than the evaluated VLM approaches.
Accurate task difficulty assessment enables a generative policy to be dynamically adjusted, maximizing performance across varying conditions. By precisely gauging the complexity of each task instance, the system can tailor its generation strategy – for example, by modulating exploration rates, adjusting the diversity of generated outputs, or selecting specific generation parameters. This adaptive behavior is crucial for maintaining high performance in environments with substantial task variation, and avoids suboptimal performance resulting from a static, one-size-fits-all generative approach. The ability to fine-tune the policy based on real-time difficulty analysis is a key component of robust and generalizable AI systems.
Unifying Generative Models for Resilient Control
The Stochastic Interpolant (SI) framework underpins the DA-SIP approach by synthesizing the benefits of both Ordinary Differential Equation (ODE) and Stochastic Differential Equation (SDE) based generative models. ODEs provide deterministic trajectory generation, enabling precise control and predictable system behavior, while SDEs introduce stochasticity, allowing for exploration of diverse solutions and robustness to noise. The SI framework achieves this combination by formulating a generative process as an interpolation between an ODE and an SDE, effectively leveraging the strengths of each. This interpolation is parameterized, permitting the control of the balance between deterministic and stochastic behavior during trajectory optimization. The resulting model can thus generate trajectories that are both accurate and adaptable to uncertain or dynamic environments, offering a more versatile control strategy than either ODE or SDE models used in isolation.
Flow Matching and Diffusion Models are incorporated into the Stochastic Interpolant framework as methods for defining the vector field used in trajectory generation. Flow Matching directly learns a velocity field that maps initial states to terminal states, providing efficient and deterministic trajectory prediction. Diffusion Models, conversely, learn to reverse a diffusion process, starting from noise and gradually constructing trajectories, which introduces stochasticity and robustness. Both techniques parameterize the dynamics of the generative model, allowing the framework to synthesize diverse and feasible trajectories by solving an Ordinary Differential Equation (ODE) or Stochastic Differential Equation (SDE) defined by the learned dynamics. This integration allows for adaptable trajectory generation, accommodating varying levels of stochasticity and computational cost depending on the specific application and desired performance.
The Discretized Auto-regressive Stochastic Interpolant Policy (DA-SIP) relies on numerical integration to approximate solutions to the ordinary ($ODE$) and stochastic ($SDE$) differential equations that define the generative model’s dynamics. Specifically, both the fourth-order Runge-Kutta (RK4) method and the Heun integration scheme are implemented to discretize these continuous-time equations. RK4, a higher-order method, generally provides increased accuracy but at a greater computational cost per step, while Heun integration-a second-order method-offers a balance between accuracy and efficiency. The choice of integration method impacts the stability and precision of trajectory generation; parameters such as step size must be carefully tuned to prevent numerical errors and ensure robust control performance. Both methods approximate the solution $y(t+\Delta t)$ given $y(t)$ and the derivative $\frac{dy}{dt}$, allowing for iterative computation of state transitions.
The incorporation of Velocity Fields and Score Functions into the control policy provides enhanced navigation capabilities within complex state spaces. Velocity Fields define a directional vector at each state, guiding the policy towards desired regions, while Score Functions, derived from the gradients of the state distribution, indicate the density of states and facilitate movement towards high-probability areas. This dual approach allows the policy to leverage both pre-defined guidance, represented by the Velocity Field, and data-driven insights from the Score Function, improving exploration and exploitation in challenging environments. Specifically, the Score Function, denoted as $s(x)$, estimates the gradient of the log probability density of the state $x$, providing a direction for policy updates that maximizes state visitation in regions of high density.
Towards Truly Adaptive Robotic Systems
The development of DA-SIP represents a significant step toward robots capable of thriving in real-world unpredictability. Unlike traditional robotic systems that rely on meticulously planned sequences or exhaustive training data, DA-SIP employs adaptive computation and robust control strategies to navigate unforeseen circumstances. This framework allows a robot to continuously refine its understanding of the environment and adjust its actions accordingly, even with limited initial information. By dynamically optimizing its control parameters, the system maintains stability and achieves desired outcomes despite disturbances or changes in terrain. This capacity for on-the-fly adaptation isn’t simply about reacting to the unexpected; it’s about proactively anticipating and mitigating potential challenges, ultimately enabling robots to operate reliably and efficiently in dynamic, and often chaotic, environments.
A significant challenge in robotics lies in deploying systems beyond carefully controlled laboratory settings; real-world environments are inherently unpredictable and data-scarce. This framework addresses this limitation through its capacity to learn and adapt with minimal data, a crucial feature for practical application. Rather than requiring extensive training datasets for each new scenario, the system dynamically adjusts its control strategies in response to changing conditions, effectively learning on the fly. This allows robots to operate reliably even when faced with unforeseen obstacles or variations in their surroundings, opening doors for deployment in fields like search and rescue, environmental monitoring, and assistive robotics where pre-programmed responses are insufficient and the ability to generalize from limited experience is paramount. The framework’s robustness isn’t about anticipating every possibility, but about intelligently responding to the unexpected, making it a promising step towards truly versatile robotic systems.
DA-SIP represents a significant advancement in robotic control through the innovative combination of generative modeling and a difficulty classifier. This framework doesn’t simply react to environmental changes; it predicts them. Generative models allow the system to anticipate potential future states, effectively simulating possible outcomes before they occur. Crucially, the integrated difficulty classifier assesses the complexity of each situation, enabling DA-SIP to dynamically adjust its control strategies-allocating more computational resources to challenging scenarios and streamlining operations when conditions are favorable. This proactive and adaptive approach moves beyond traditional reactive control, offering a robust and efficient method for robots to navigate and manipulate objects in unpredictable real-world settings, and ultimately achieving more nuanced and reliable performance.
Ongoing research endeavors are directed toward broadening the scope of this adaptive framework, with particular emphasis on tackling increasingly intricate challenges and diverse operational landscapes. The anticipated advancements involve refining the system’s capacity to generalize learned behaviors across previously unseen scenarios, thereby enhancing its robustness and resilience in unpredictable real-world settings. This includes exploring more sophisticated generative models and difficulty classifiers, as well as investigating methods for continual learning and knowledge transfer. The ultimate objective is to move beyond task-specific robotic solutions and create truly intelligent systems capable of autonomous adaptation, paving the way for versatile robots that can seamlessly navigate and interact with complex environments, and ultimately, contribute to a wider range of applications.
The pursuit of efficient computation, as demonstrated by this Difficulty-Aware Stochastic Interpolant Policy, echoes a fundamental principle of intelligence: resource allocation based on perceived challenge. The system’s ability to dynamically scale computation-dedicating more resources to complex tasks and fewer to simpler ones-is not merely optimization, but a sophisticated form of intellectual leverage. As Marvin Minsky once stated, “Intelligence is the ability to make good decisions, even when faced with incomplete information.” This policy embodies that sentiment; it doesn’t demand perfect foresight of task complexity, but adapts in real-time, skillfully exploiting the relationship between difficulty classification and computational need. It’s a testament to the power of reverse-engineering reality, distilling control into an elegant exploit of comprehension.
What Breaks Next?
The Difficulty-Aware Stochastic Interpolant Policy (DA-SIP) presents a compelling demonstration: resource allocation isn’t merely about having compute, but about intelligently ceding it when unnecessary. The system, in essence, confesses its design sins – the inherent inefficiency of uniform application – by admitting where simplification is not degradation. However, this begs a critical question. Difficulty classification, while effective here, remains fundamentally tied to the present task. What happens when a novel, unanticipated difficulty emerges – a situation the classifier hasn’t ‘seen’ before? The elegance of dynamic scaling will crumble if the difficulty assessment itself becomes the bottleneck.
Further exploration must move beyond single-robot scenarios. A swarm, each unit operating under DA-SIP, introduces complexities of distributed difficulty assessment and collective resource optimization. Could discrepancies in individual difficulty readings be exploited – or even induced – to create emergent, adaptive behaviors? The current work assumes a relatively static environment; a truly robust system must anticipate and accommodate adversarial manipulations of perceived difficulty – a deliberate attempt to overload or under-resource the control policy.
Ultimately, the true test lies not in achieving computational savings, but in exposing the limits of adaptive computation itself. A bug isn’t a failure of implementation; it’s the system confessing its design sins. The next step isn’t to polish the current model, but to actively seek out those confessions, to push DA-SIP – and the entire paradigm of dynamic scaling – to the point of controlled collapse, revealing the fundamental constraints on intelligent resource allocation.
Original article: https://arxiv.org/pdf/2511.20906.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- World Eternal Online promo codes and how to use them (September 2025)
- Clash Royale Season 79 “Fire and Ice” January 2026 Update and Balance Changes
- Best Arena 9 Decks in Clast Royale
- Best Hero Card Decks in Clash Royale
- How to find the Roaming Oak Tree in Heartopia
- Clash Royale Witch Evolution best decks guide
- FC Mobile 26: EA opens voting for its official Team of the Year (TOTY)
2025-11-30 02:32