Author: Denis Avetisyan
A new framework balances performance and efficiency for deploying large AI models in real-world embodied systems.

This work presents a joint optimization of quantization and resource allocation for co-inference in large AI models, addressing the distortion-rate tradeoff for edge computing applications.
Deploying large AI models on resource-constrained embodied agents presents a fundamental challenge: balancing computational demands with real-time performance. This paper, ‘Quantization-Aware Collaborative Inference for Large Embodied AI Models’, addresses this by developing a framework for optimizing collaborative inference through joint design of quantization strategies and computational resource allocation. The authors demonstrate tractable approximations for quantization-induced distortion and derive rate-distortion bounds, enabling a principled approach to minimizing inference error under latency and energy constraints. Will this co-inference approach unlock truly scalable and efficient embodied AI systems capable of complex, real-world interaction?
Decoding Embodied Intelligence: Beyond Data to Action
The escalating demands of modern robotics and artificial intelligence are driving a significant shift towards systems capable of not just processing data, but actively interacting with and understanding the world around them. This need for perception, comprehension, and action in complex, real-world environments has given rise to the field of Embodied AI. Unlike traditional AI which often operates in simulated or highly structured settings, Embodied AI focuses on creating agents – whether robotic or virtual – that can navigate unpredictable landscapes, interpret sensory input, and execute tasks with a degree of autonomy and adaptability. This requires a holistic approach, integrating advances in areas like computer vision, natural language processing, and motor control to forge intelligent systems genuinely ’embodied’ within their surroundings, and capable of responding to dynamic, often ambiguous, situations.
The functionality of embodied AI hinges on the deployment of robust core intelligence, increasingly provided by Large AI Models (LAIM). These models, trained on massive datasets, enable agents to perceive complex environments, interpret sensory input, and formulate appropriate responses. Unlike traditional rule-based systems, LAIMs leverage statistical learning to generalize from data, allowing for adaptability and nuanced decision-making in unpredictable scenarios. This capability extends beyond simple task completion; it allows embodied agents to exhibit behaviors requiring understanding of context, prediction of outcomes, and even a degree of creativity in problem-solving. The sophistication of these models directly correlates with the agent’s ability to navigate, manipulate objects, and interact meaningfully within its surroundings, marking a significant leap toward truly intelligent and autonomous systems.
The practical implementation of Large AI Models (LAIM) in embodied AI systems is significantly hampered by substantial demands on computational resources and energy consumption. These models, while demonstrating impressive capabilities in simulated environments, often require specialized hardware – such as powerful GPUs – and considerable electrical power to operate in real-time. This poses a critical challenge for deploying robots and intelligent agents in resource-constrained settings, limiting their operational duration and increasing overall system costs. Researchers are actively exploring model compression techniques, neuromorphic computing, and edge computing solutions to mitigate these issues, striving to create LAIMs that are both powerful and sustainable for widespread use in embodied applications.
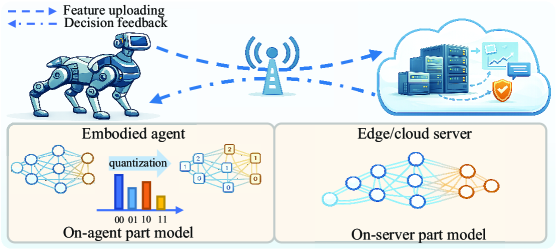
Strategic Deployment: The On-Device vs. On-Cloud Conundrum
Traditional artificial intelligence deployment fundamentally bifurcates into on-device and on-cloud processing paradigms. On-device processing executes AI models locally on the endpoint hardware – smartphones, embedded systems, or similar – resulting in minimal latency due to the elimination of network communication. However, this approach is constrained by the computational power, memory capacity, and energy efficiency of the target device. Conversely, on-cloud processing offloads AI tasks to remote servers, providing access to significantly greater resources – processing power, storage, and specialized hardware accelerators. This scalability comes at the cost of introducing network latency, requiring a reliable network connection, and raising potential data privacy concerns related to transmitting data to external servers.
On-device AI deployment prioritizes data privacy by processing information locally, eliminating the need to transmit sensitive data to external servers; this also results in lower latency and faster response times due to the absence of network communication. Conversely, on-cloud deployment utilizes remote servers and infrastructure, enabling greater scalability to handle fluctuating workloads and potentially reducing operational costs through shared resources; however, this approach introduces network dependencies that can impact performance and necessitates data transmission, raising privacy considerations and incurring potential bandwidth costs.
The successful implementation of both on-device and on-cloud AI deployment strategies is fundamentally dependent on the efficient execution of Lightweight AI Models (LAIM). This necessitates careful consideration of model size, as larger models demand greater computational resources and storage, potentially exceeding the limitations of edge devices or increasing cloud infrastructure costs. Equally critical is managing computational complexity; algorithms with high complexity require more processing power and can introduce latency, impacting real-time performance. Optimization techniques, such as model pruning, quantization, and knowledge distillation, are therefore essential to reduce both model size and computational demands, ensuring LAIM can be effectively deployed across diverse hardware and network conditions.
Orchestrated Intelligence: The Power of Co-inference
Co-inference represents a distributed approach to machine learning inference, strategically partitioning workloads between on-device processing, edge servers, and cloud infrastructure to optimize overall system performance. This technique capitalizes on the unique advantages of each environment – leveraging the low latency of on-device computation for immediate responsiveness, the increased processing capabilities of edge servers for intermediate tasks, and the substantial resources of the cloud for complex, computationally intensive operations. By dynamically allocating inference tasks based on resource availability and network conditions, co-inference aims to minimize latency, reduce energy consumption, and improve the scalability of machine learning deployments compared to purely centralized or decentralized methods.
Co-inference strategically distributes computational load by executing demanding operations in the cloud and less intensive tasks locally. This division of labor allows for leveraging the greater processing power and resources available in cloud environments for complex calculations, while preserving low latency and immediate responsiveness by handling simpler inferences directly on the device or at the edge. The technique effectively balances performance gains from cloud processing with the need for real-time operation, optimizing overall system efficiency and user experience by matching task complexity to available computational resources at each location.
Evaluations of co-inference were conducted using the BLIP-2 and GIT models, assessed on the MS-COCO and VaTeX datasets to demonstrate performance in practical applications. Results indicate that distributing inference tasks across device, edge, and cloud infrastructure improves overall efficiency. Specifically, MS-COCO, a large-scale object detection, segmentation, and captioning dataset, provided a benchmark for complex visual reasoning, while VaTeX, a dataset of LaTeX equations, assessed co-inference capabilities in mathematical expression processing. These experiments confirmed the potential of co-inference to optimize resource allocation and enhance model performance across diverse tasks.
The practical application of co-inference is fundamentally limited by constraints on both latency and energy expenditure. This research introduces a theoretical framework designed to quantify the trade-offs between these two factors, expressed as a relationship between computational offloading and resource utilization. The framework’s validity has been empirically demonstrated through experimentation with three distinct models – FCDNN-16, BLIP-2, and GIT – assessing performance across varying computational distributions. Results indicate a quantifiable relationship between achievable inference rates and resulting distortion, with derived rate-distortion bounds closely aligning with numerically estimated distortion-rate functions, thereby providing a characterization of co-inference system behavior under these constraints.
Theoretical rate-distortion bounds derived within this work demonstrate strong alignment with numerically estimated distortion-rate functions across tested models-FCDNN-16, BLIP-2, and GIT. This correspondence validates the analytical framework and provides a quantifiable characterization of the trade-off between data rate and resulting distortion in co-inference systems. Specifically, the derived bounds establish limits on achievable performance, while the numerically estimated functions reflect the actual distortion-rate behavior observed in practical implementations. The close agreement between these two confirms the accuracy of the theoretical model in predicting the performance limits of co-inference, enabling informed optimization of system parameters to balance efficiency and accuracy.
![BLIP-2's performance on MS-COCO is sensitive to both delay and energy consumption thresholds, as demonstrated by varying results with [latex]E_0 = 2.00~{\rm J}[/latex] (left) and [latex]T_0 = 3.50~{\rm s}[/latex] (right).](https://arxiv.org/html/2602.13052v1/x13.png)
Refining the Algorithm: Quantization and Pruning for Efficiency
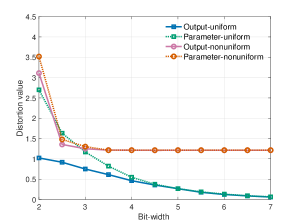
Quantization reduces the number of bits used to represent a neural network’s weights and activations, directly decreasing both model size and computational demands. This is achieved by mapping continuous values to a finite set of discrete levels. The theoretical underpinnings of quantization are described by Rate-Distortion Theory, which establishes a quantifiable relationship between the compression rate – the reduction in bits – and the resulting information loss, or distortion, in model accuracy. Lower precision data types, such as 8-bit integers, require less storage and offer faster computation compared to the typical 32-bit floating-point representation, although this comes at the potential cost of reduced model performance. The extent of accuracy loss is dependent on the specific quantization method and the sensitivity of the model to reduced precision.
Uniform quantization represents all weights with a consistent step size, simplifying implementation but potentially leading to larger quantization errors, especially with varying weight distributions. Nonuniform quantization, conversely, employs variable step sizes – often determined by the distribution of weights – to minimize quantization error for frequently occurring values, achieving higher accuracy at the cost of increased computational complexity. The selection between these methods depends on the specific model architecture, hardware capabilities, and acceptable trade-off between compression rate and model accuracy; generally, nonuniform quantization provides better accuracy for a given compression ratio, while uniform quantization offers faster inference due to its simplicity.
Pruning techniques reduce model complexity by systematically removing parameters – weights and biases – or entire neurons that contribute minimally to the model’s predictive power. This reduction in parameters directly translates to lower computational costs and memory footprint. Various pruning strategies exist, including magnitude-based pruning, which eliminates weights with the smallest absolute values, and structured pruning, which removes entire neurons or filters. Critically, effective pruning maintains model accuracy through retraining or fine-tuning after parameter removal, mitigating performance degradation and ensuring the model retains its functionality with a reduced parameter count.
The successful deployment of Lightweight AI Models (LAIM) on edge devices is critically dependent on model optimization techniques such as quantization and pruning due to the inherent resource limitations of these platforms – including constrained processing power, memory, and energy. Evaluations conducted through both simulations and deployments in real-world testbeds demonstrate that this combined optimization approach consistently yields superior performance compared to standard benchmark schemes. Specifically, these methods enable LAIM to achieve higher accuracy and efficiency when operating under the computational and power budgets typical of edge environments, facilitating practical implementation where alternative, larger models would be infeasible.
The Intelligent, Efficient RAN: A Vision for the Future
The future of wireless networks hinges on a powerful synergy between several emerging fields. Embodied artificial intelligence, where AI agents physically interact with their surroundings, demands real-time responsiveness from the network. This need is being met through co-inference – a technique allowing devices to collaboratively process data at the network edge, reducing latency and bandwidth demands. Crucially, these gains are amplified by advanced model optimization, which tailors AI algorithms for efficient execution on resource-constrained devices. This convergence isn’t simply about faster speeds; it’s architecting an AI-RAN – an AI-driven Radio Access Network – capable of dynamically adapting to the needs of embodied agents, enabling truly intelligent and efficient wireless communication for robotics, autonomous vehicles, and a host of other applications requiring seamless connectivity and real-time performance.
A transformative shift in radio access network (RAN) technology promises to unlock the full potential of robotics and autonomous systems operating within intricate, real-world scenarios. This next generation of systems will no longer be confined by the limitations of current wireless infrastructure; instead, they will benefit from a dynamically optimized network capable of supporting the demanding requirements of simultaneous localization, mapping, and object recognition. The convergence of artificial intelligence and RAN architectures facilitates seamless operation in challenging environments – from bustling cityscapes to unpredictable industrial settings – enabling robots to navigate, collaborate, and react with unprecedented agility and reliability. This intelligent connectivity isn’t simply about faster data transfer; it’s about creating a responsive, resilient network that anticipates and adapts to the ever-changing needs of autonomous agents, ultimately fostering a future where robots and humans coexist and collaborate more effectively.
Continued development hinges on optimization strategies capable of real-time adaptation; future research will prioritize algorithms that move beyond static configurations to dynamically respond to fluctuating network resources and diverse application demands. These strategies will necessitate intelligent monitoring of conditions like bandwidth availability, computational load, and energy consumption, allowing the AI-RAN to proactively adjust model complexity, inference frequency, and resource allocation. Such adaptive approaches promise to maintain performance levels even under unpredictable circumstances, ensuring consistent service delivery for a growing range of robotic and autonomous applications – from precision agriculture and environmental monitoring to industrial automation and public safety – while simultaneously minimizing energy expenditure and maximizing network efficiency.
The culmination of progress in AI-RAN technologies promises a significant leap forward in the capabilities of artificial intelligence systems. These developments aren’t simply about incremental improvements; they are poised to deliver AI solutions characterized by markedly increased responsiveness, allowing for near-instantaneous reaction to dynamic environments. Beyond speed, reliability will be substantially enhanced through robust architectures and adaptive optimization, minimizing failures and ensuring consistent performance even under challenging conditions. Crucially, these advancements are intrinsically linked to energy efficiency; by intelligently managing resources and streamlining processes, future AI systems will dramatically reduce their power consumption, paving the way for sustainable and scalable deployments across a wide range of applications, from autonomous vehicles to smart infrastructure and beyond.
The pursuit within this research – optimizing co-inference through quantization and resource allocation – mirrors a fundamental drive to understand system limits. It’s an intellectual dismantling, a controlled demolition of established parameters to reveal underlying structure. Ada Lovelace observed that “The Analytical Engine has no pretensions whatever to originate anything.” This holds true here; the framework doesn’t create intelligence, but rather exploits the existing potential within Large AI Models by meticulously controlling the flow of information – the ‘distortion-rate tradeoff’ – to achieve optimal performance at the edge. The work isn’t about invention, but precise, resourceful execution within defined boundaries – a testament to understanding how things actually work.
Pushing the Boundaries
The presented framework, while demonstrably effective in navigating the distortion-rate tradeoff within co-inference, implicitly accepts a fundamental constraint: the models themselves are fixed. What happens when the very architecture becomes malleable? Future work must investigate whether a truly dynamic system – one that simultaneously optimizes quantization, resource allocation, and model topology – can transcend the limitations of pre-defined structures. The current approach treats quantization as a means to an end; a more radical exploration would consider it as a potential source of emergent behavior, deliberately introducing controlled ‘noise’ to enhance robustness or unlock unforeseen capabilities.
Furthermore, the emphasis on embodied AI naturally invites a challenge. The framework currently optimizes for computational efficiency, but what of the embodiment itself? The energy savings achieved through aggressive quantization are rendered less impactful if the actuators required for physical interaction demand disproportionate power. A complete solution demands a holistic view – one that integrates the energy profile of the entire embodied system, not merely the inference engine. This necessitates a re-evaluation of the distortion-rate tradeoff, factoring in the perceptual limitations of the embodied agent itself. After all, a perfectly accurate simulation is useless if the robot cannot reliably execute the corresponding action.
Ultimately, the true test lies not in minimizing latency or maximizing throughput, but in identifying the point of diminishing returns. At what level of distortion does the system cease to be ‘intelligent,’ and instead become a cleverly disguised automaton? The pursuit of efficiency should not eclipse the fundamental question of what constitutes meaningful intelligence in an embodied context.
Original article: https://arxiv.org/pdf/2602.13052.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Episode 4 Release Date, Time, Where to Watch
- How Martin Clunes has been supported by TV power player wife Philippa Braithwaite and their anti-nepo baby daughter after escaping a ‘rotten marriage’
- Beyond Accuracy: Gauging Trust in Human-AI Teams
- Gold Rate Forecast
- Clash Royale Balance Changes March 2026 — All Buffs, Nerfs & Reworks
- ‘Project Hail Mary’s Unexpected Post-Credits Scene Is Worth Sticking Around
- CookieRun: OvenSmash coupon codes and how to use them (March 2026)
- We talked to ‘Bachelorette’ Taylor Frankie Paul. Then reality hit pause on her TV career
- Roco Kingdom: World China beta turns chaotic for unexpected semi-nudity as players run around undressed
- eFootball 2026 is bringing the v5.3.1 update: What to expect and what’s coming
2026-02-17 03:38