Author: Denis Avetisyan
Researchers have developed a new user simulator that leverages reasoning and reinforcement learning to create more realistic and challenging interactions with artificial intelligence.
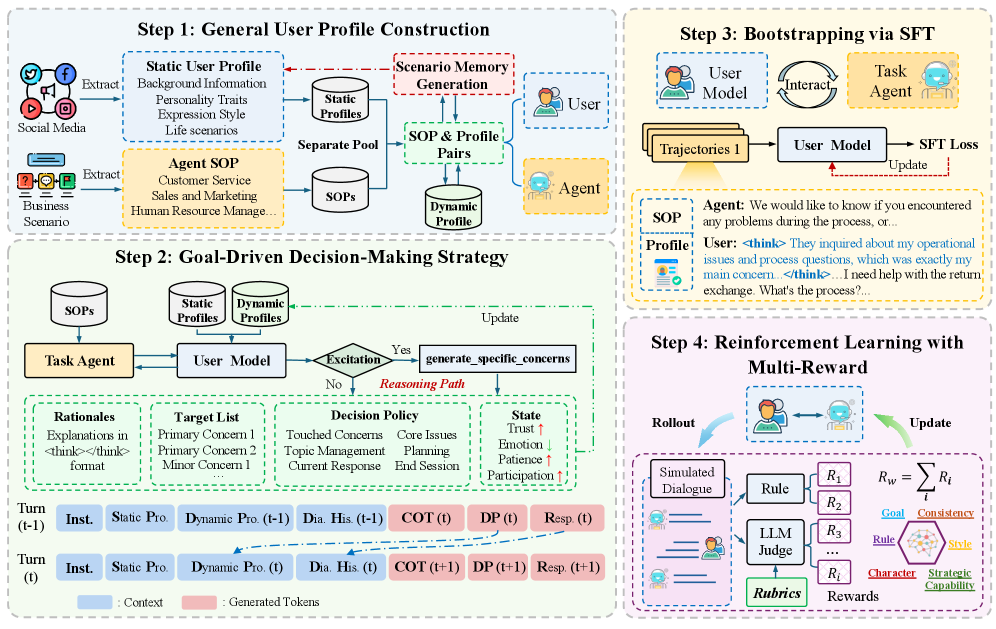
UserLM-R1 employs multi-reward reinforcement learning to model human reasoning in user simulations, improving strategic interaction and adversarial testing of large language models.
Current user simulators for dialogue systems often lack the adaptability and strategic depth of human interaction, hindering realistic agent training. To address this, we introduce UserLM-R1: Modeling Human Reasoning in User Language Models with Multi-Reward Reinforcement Learning, a novel approach that imbues simulated users with reasoning capabilities and strategic awareness. By combining dynamic user profiles with a goal-driven decision-making policy refined through reinforcement learning, UserLM-R1 demonstrably outperforms existing methods, particularly in challenging adversarial scenarios. Could this represent a step towards truly robust and engaging conversational AI systems capable of navigating complex interactions?
The Illusion of Intelligence: Why Current Simulators Fall Short
Current user simulators, designed to test conversational AI, frequently operate with models that drastically underestimate the complexities of human thought. These systems often rely on rule-based responses or statistical patterns, failing to capture the inferential leaps, contextual understanding, and common-sense reasoning that characterize natural dialogue. Consequently, they struggle to anticipate user behavior beyond pre-programmed scenarios, offering a limited evaluation of a conversational agent’s robustness. The resulting simulations may indicate high performance against predictable inputs, but provide a misleadingly optimistic view of how the system will fare when interacting with a genuine user capable of unexpected questions, nuanced expressions, or even deliberately deceptive tactics. This gap between simulated and human reasoning presents a significant challenge in developing truly intelligent and reliable conversational agents.
The inability of conventional user simulators to accurately model human reasoning significantly hinders the robust evaluation of conversational agents. These agents, increasingly deployed in sensitive contexts, must navigate complex interactions and resist manipulative tactics; however, current simulators often fail to expose vulnerabilities to such strategies. A conversational agent might successfully pass tests against a simplistic simulator, yet be easily exploited by a human user employing nuanced language or deceptive techniques. This discrepancy arises because simulators typically lack the capacity for strategic thinking, common-sense reasoning, or the ability to detect subtle cues indicative of manipulation. Consequently, reliance on these limited simulations provides a false sense of security, potentially leading to the deployment of agents susceptible to exploitation and undermining trust in their interactions.
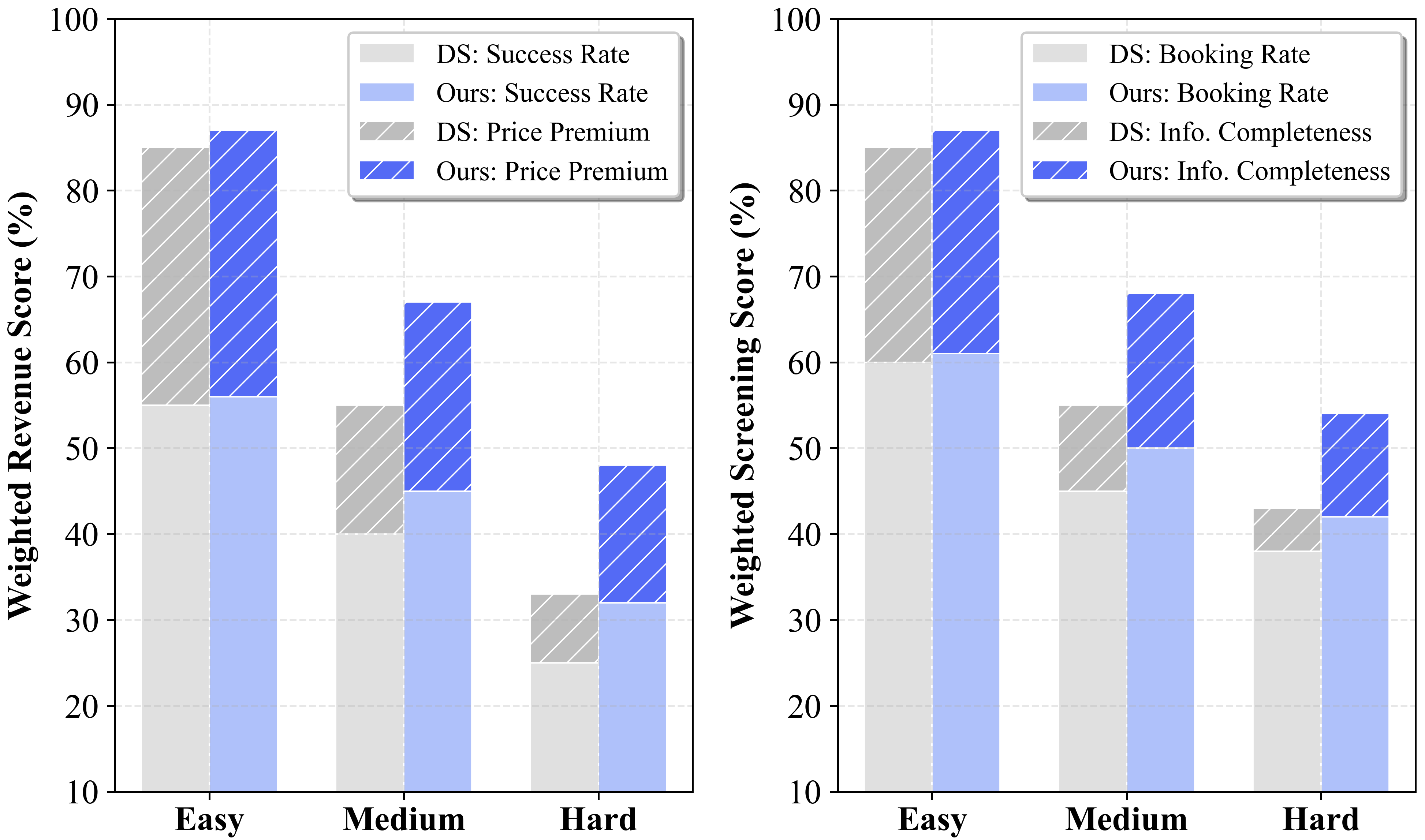
UserLM-R1: A Framework Rooted in Reasoning
UserLM-R1 employs a two-tiered user profile system to enhance simulation realism. Static user profiles define long-term attributes such as demographics, interests, and personality traits, providing a foundational behavioral context. Complementing this, dynamic user profiles track short-term states including current goals, conversation history, and evolving preferences. This combination allows UserLM-R1 to model not only consistent user characteristics but also adapt to the nuances of an ongoing interaction, resulting in more believable and contextually appropriate simulated responses. The framework integrates these profiles as inputs to its reasoning engine, informing goal selection and response generation.
UserLM-R1 employs goal-driven reasoning as a core mechanism for simulating user behavior. This approach prioritizes the formulation of a plan or objective prior to generating any response, mirroring the human cognitive process of considering desired outcomes before acting. Specifically, the system first identifies the user’s underlying goal based on the current context and user profile. This goal then guides the subsequent reasoning steps and ultimately shapes the generated response, ensuring that the output is not simply a reactive statement but rather a deliberate action intended to achieve a defined purpose. This contrasts with traditional methods where responses are generated directly from input, potentially lacking coherence and intentionality.
Chain-of-Thought (CoT) reasoning within UserLM-R1 involves prompting the model to explicitly articulate its reasoning steps before providing a final response. This is achieved by including demonstrations in the prompt that showcase intermediate reasoning traces, guiding the model to decompose complex tasks into a series of logical inferences. The explicit articulation of these reasoning steps enhances transparency by revealing the basis for the model’s decisions. Furthermore, this process improves interpretability, allowing developers and users to more easily understand why a particular response was generated, facilitating debugging and trust-building in the user simulation framework.

Building a Better Simulator: Training for Adaptability
UserLM-R1’s initial training phase utilizes supervised fine-tuning, a process where the model learns from a pre-existing dataset of user-provided reasoning examples paired with corresponding responses. This dataset consists of text demonstrating how users articulate their thought processes when solving problems or answering questions, alongside the expected or ideal responses. The supervised learning approach allows UserLM-R1 to establish a foundational understanding of reasoning patterns and response generation before further refinement through reinforcement learning. The quality and diversity of this initial dataset are critical determinants of the model’s subsequent performance and ability to generalize to unseen reasoning tasks.
Following supervised fine-tuning, UserLM-R1 undergoes reinforcement learning to improve reasoning performance. This process utilizes a multi-reward signal, comprising multiple metrics designed to assess both the correctness and quality of the model’s responses. The reward function incentivizes behavioral fidelity by rewarding responses aligned with human reasoning patterns. Furthermore, it encourages exploration of diverse reasoning trajectories-that is, different valid paths to a solution-preventing the model from converging on a single, potentially brittle, approach. This multi-faceted reward system enables the model to refine its reasoning capabilities beyond simple accuracy, fostering adaptability and robustness in conversational interactions.
The training regimen for UserLM-R1 facilitates adaptability to novel conversational contexts through iterative refinement of the model’s response generation. By exposing the model to a diverse range of reasoning tasks and utilizing a multi-reward reinforcement learning system, the model learns to generalize beyond the initial supervised fine-tuning data. This process enables the model to modify its reasoning approach based on evolving user inputs and maintain coherent dialogue, resulting in conversational patterns more closely aligned with human interaction. Specifically, the model’s ability to explore diverse reasoning paths, guided by the reward signals, allows it to handle unexpected prompts and maintain consistency across extended exchanges.
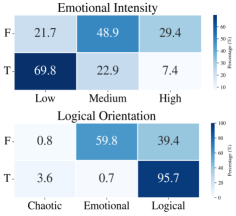
The Real Test: Defending Against Deception
UserLM-R1 underwent a demanding evaluation process utilizing a newly constructed adversarial dataset comprised of eleven distinct ‘trap’ scenarios. These scenarios were specifically designed to challenge the model’s ability to resist manipulative conversational tactics, probing for vulnerabilities to persuasive strategies and logical fallacies. The dataset moves beyond simple keyword detection, requiring the model to demonstrate genuine understanding and reasoned responses within complex, evolving dialogues. This rigorous testing methodology aims to accurately gauge the model’s resilience – not just its ability to generate coherent text, but its capacity to maintain consistent and truthful behavior even when confronted with deceptive conversational prompts. The diverse range of traps ensured a comprehensive assessment of UserLM-R1’s robustness across multiple forms of conversational manipulation.
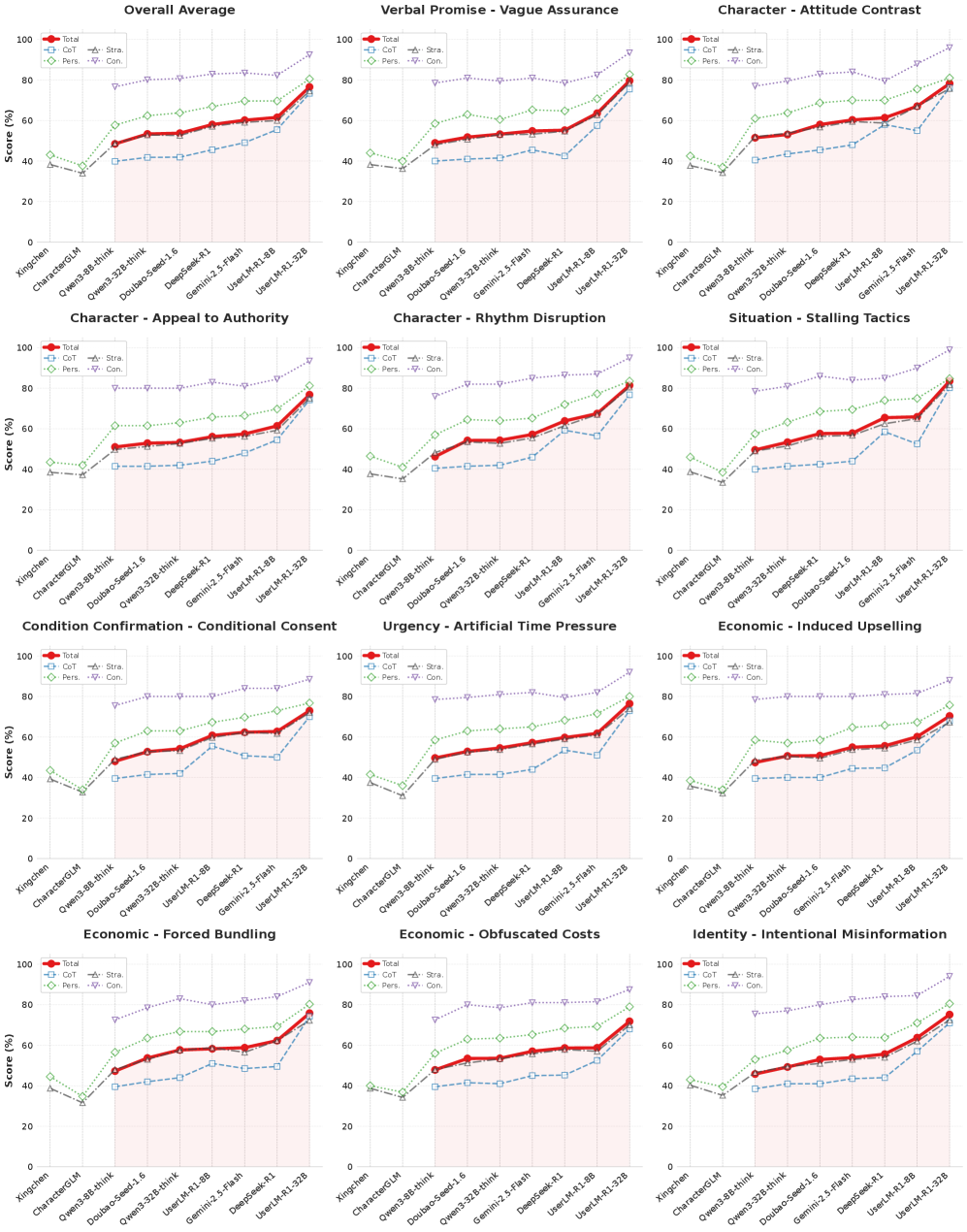
Evaluations reveal that UserLM-R1 consistently outperformed all baseline models when subjected to a rigorous battery of 11 adversarial “trap” scenarios designed to test conversational manipulation resistance. Across each of these challenges, designed to exploit common cognitive biases and persuasive techniques, UserLM-R1 demonstrated a higher success rate – effectively “winning” more often than its counterparts. This consistent performance indicates a significant advancement in the model’s ability to maintain its objectives and avoid being led astray by manipulative conversational tactics, suggesting a robust defense against increasingly sophisticated adversarial prompts and a marked improvement in overall conversational stability.
UserLM-R1 demonstrated a remarkable capacity for cognitive defense, uniquely succeeding in navigating the most challenging manipulation scenario – designated Case 3. This complex trap, designed to exploit vulnerabilities in conversational AI, proved insurmountable for all other models tested; only one out of five successfully resisted its influence. The ability to withstand such sophisticated cognitive attacks highlights a significant advancement in building robust and trustworthy conversational agents, suggesting UserLM-R1 possesses a level of reasoning and contextual awareness currently unmatched by existing alternatives. This success isn’t merely a quantitative improvement, but a qualitative leap toward AI systems capable of discerning and resisting deceptive conversational tactics.
The development of truly trustworthy conversational agents hinges on their ability to resist manipulation, making enhanced resilience a critical advancement. Without robust defenses against adversarial tactics, evaluations of a model’s core capabilities become unreliable – a system susceptible to being led astray cannot accurately demonstrate its knowledge or reasoning. This capacity to withstand manipulative conversational strategies isn’t merely about avoiding unwanted outcomes; it’s fundamental to establishing confidence in the agent’s responses and ensuring the validity of performance assessments. Consequently, prioritizing resilience allows for more meaningful benchmarking and paves the way for deploying conversational AI that is both dependable and genuinely helpful, fostering greater user trust and broader adoption.
The pursuit of increasingly realistic user simulators, as demonstrated by UserLM-R1 and its multi-reward reinforcement learning approach, feels…predictable. It’s another layer of complexity built upon existing limitations. The article details a system attempting to model human reasoning, but one suspects production environments will swiftly reveal unforeseen exploits and corner cases. As Robert Tarjan once said, “The most successful algorithms are those that are simple and elegant.” This feels anything but. The drive for strategic interaction, while admirable, often leads to brittle systems that fail spectacularly when confronted with genuinely unpredictable user behavior. Everything new is just the old thing with worse docs.
Future Shocks
The pursuit of increasingly ‘realistic’ user simulators invariably encounters the limits of what can be modeled. UserLM-R1, with its multi-reward reinforcement learning, represents a sophisticated attempt to inject strategic depth, but strategic depth is, itself, a moving target. Production systems will expose the brittle assumptions baked into any simulated opponent. Tests are a form of faith, not certainty; the adversarial scenarios deemed ‘challenging’ today will appear quaintly naive tomorrow.
The real difficulty isn’t generating clever responses, it’s handling the statistically improbable edge cases-the user who deliberately misinterprets instructions, the request phrased as a riddle, the sudden shift in conversational context. These aren’t failures of reasoning, but demonstrations of human unpredictability. Future work will likely focus less on perfecting the simulation of reasoning, and more on building systems robust enough to tolerate irrationality.
One suspects the ultimate benchmark won’t be achieving human-level performance in controlled experiments, but rather minimizing the number of inexplicable failures in live deployment. The goal isn’t to build an intelligent opponent, but one that doesn’t take down the service on a Monday morning. That, perhaps, is a more honest measure of progress.
Original article: https://arxiv.org/pdf/2601.09215.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Clash Royale Best Boss Bandit Champion decks
- Vampire’s Fall 2 redeem codes and how to use them (June 2025)
- World Eternal Online promo codes and how to use them (September 2025)
- How to find the Roaming Oak Tree in Heartopia
- Mobile Legends January 2026 Leaks: Upcoming new skins, heroes, events and more
- Best Arena 9 Decks in Clast Royale
- ATHENA: Blood Twins Hero Tier List
- Clash Royale Furnace Evolution best decks guide
- Brawl Stars December 2025 Brawl Talk: Two New Brawlers, Buffie, Vault, New Skins, Game Modes, and more
- How To Watch Tell Me Lies Season 3 Online And Stream The Hit Hulu Drama From Anywhere
2026-01-16 05:36