Author: Denis Avetisyan
A new approach filters unnecessary information in neural networks to boost the performance and efficiency of robot manipulation policies.

This work introduces Variational Regularization to refine intermediate features within U-Net decoders used in diffusion models for robot control, leveraging the Information Bottleneck principle.
While diffusion-based visuomotor policies have demonstrated success in robot manipulation, oversized denoising decoders often introduce redundant noise in intermediate feature representations. This work, ‘Information Filtering via Variational Regularization for Robot Manipulation’, addresses this limitation by introducing Variational Regularization (VR), a lightweight module that adaptively filters these features via a timestep-conditioned Gaussian prior and [latex]KL[/latex]-divergence regularization. Experiments across simulation benchmarks-including RoboTwin2.0, Adroit, and MetaWorld-demonstrate that VR improves success rates by up to 6.1%, achieving state-of-the-art performance, and real-world results confirm its practical viability. Could this approach to information filtering unlock more efficient and robust robotic learning paradigms?
Decoding the World: From Sensation to Scene Understanding
For a robot to navigate and interact with the physical world, a comprehensive perception of its surroundings is paramount. This begins with the acquisition of raw sensor data – typically from devices like LiDAR and cameras – which initially presents a chaotic stream of information. Effective robot control isn’t simply about executing pre-programmed instructions; it requires the ability to interpret this sensory input and construct a meaningful representation of the environment. Without a robust understanding of obstacles, navigable spaces, and object identities, a robot’s actions would be limited, inefficient, and potentially unsafe. Consequently, significant research focuses on developing algorithms that can transform this raw data into actionable insights, enabling robots to adapt to dynamic conditions and perform complex tasks with autonomy and precision.
The conversion of raw environmental data into a usable format begins with establishing a comprehensive scene representation. High-dimensional point cloud data, gathered from sensors, initially presents a vast and unwieldy dataset. This data is effectively distilled into a more compact and meaningful form, capturing the essential geometric and semantic information of the surroundings. This process isn’t merely about reducing data size; it’s about creating an internal model of the environment that a robot or AI system can readily interpret and utilize for tasks like navigation, object recognition, and interaction. A well-constructed scene representation allows for efficient reasoning about spatial relationships and facilitates informed decision-making, ultimately bridging the gap between sensory input and intelligent action.
The conversion of raw sensory input into actionable intelligence relies heavily on the capabilities of a 3D point cloud encoder. This component functions as a crucial information bottleneck, transforming the vast, high-dimensional data captured by sensors – representing a scene as a collection of points in 3D space – into a more manageable and meaningful representation. Effectively, the encoder distills the essential features of an environment, discarding noise and redundancy while preserving critical details like object geometry and spatial relationships. This compressed scene understanding then serves as the foundation for a multitude of downstream robotic tasks, including navigation, object recognition, and manipulation, allowing robots to interact with the world in a more efficient and reliable manner. The performance of this encoding process directly impacts the robot’s ability to perceive, reason about, and ultimately, operate within complex environments.

Generative Action: Modeling Control with Diffusion
Diffusion-Based Policies represent a recent development in robot control, enabling the modeling of complex manipulation tasks through a probabilistic framework. Unlike traditional methods that directly map states to actions, these policies learn to generate actions by reversing a diffusion process – a method originally developed for image generation. This involves training a model to denoise a signal, effectively learning the underlying distribution of successful actions for a given task. By framing robot control as a generative process, these policies demonstrate improved robustness to noisy sensor data and the ability to generalize to unseen scenarios. The approach contrasts with deterministic policies, allowing for exploration and adaptation during execution, which is particularly beneficial in dynamic and unpredictable environments.
Diffusion-based policies generate action sequences by learning to reverse a diffusion process, which systematically adds noise to data until it becomes pure noise, and then learns to denoise it. This is achieved by training a neural network to predict the noise added at each step, allowing the policy to iteratively remove noise from a random input and generate a coherent action sequence. This approach differs from traditional reinforcement learning methods and offers advantages in exploring complex action spaces and handling multi-modal distributions, as the diffusion process naturally encourages exploration and can represent multiple valid solutions. The iterative denoising process effectively models the conditional probability distribution of actions given the current state, allowing for robust and adaptable control policies.
The U-Net decoder functions as the core mechanism for translating encoded environmental observations into actionable robotic commands within diffusion-based policies. This architecture, commonly employed in image segmentation, receives a latent representation of the scene – often generated by an encoder network – and progressively upsamples this information through a series of convolutional and deconvolutional layers. Each layer refines the action prediction, incorporating contextual details from earlier stages. The final output of the U-Net decoder is a distribution over possible actions, representing the policy’s recommendation for the robot to execute, given the current state of the environment. The decoder’s structure allows for precise spatial reasoning and the generation of detailed, multi-dimensional action commands.

Pruning the Noise: Variational Regularization for Efficiency
The architecture of the U-Net decoder, while effective, often processes backbone features that contain substantial redundancy and irrelevant data. This excess information doesn’t contribute to the final action generation and can, in fact, degrade performance by increasing computational load and potentially obscuring salient features. The inherent dimensionality of these features, coupled with the complexity of the input data, leads to a high-dimensional representation where not all elements are equally important for successful task completion. Consequently, filtering these features is crucial for improving efficiency and overall performance of the robotic control system.
Variational Regularization (VR) is implemented to address redundancy within the U-Net Decoder’s backbone features by drawing upon the principles of the Variational Information Bottleneck (VIB). This technique introduces a probabilistic approach to feature selection, effectively creating a compressed representation of the input data. The VIB framework encourages the model to learn a latent variable that captures only the information relevant to the task at hand, discarding irrelevant details. In the context of this implementation, VR aims to minimize the mutual information between the input features and the latent representation, while maximizing the mutual information between the latent representation and the desired output, ultimately leading to more efficient and robust feature extraction.
Variational Regularization (VR) operates by introducing a timestep-conditioned bottleneck to the feature representations within the U-Net decoder. This bottleneck enforces a compression of the feature data, reducing redundancy and focusing on information relevant to action generation. The degree of compression is controlled and quantified using the Kullback-Leibler (KL) Divergence [latex]D_{KL}(q(z|x)||p(z))[/latex], which measures the difference between the approximate posterior distribution [latex]q(z|x)[/latex] of the compressed features, given the input [latex]x[/latex], and a prior distribution [latex]p(z)[/latex]. By minimizing the KL Divergence, the VR technique ensures that the compressed features retain sufficient information for effective policy learning while simultaneously removing noise and irrelevant details, ultimately improving sample efficiency and performance.
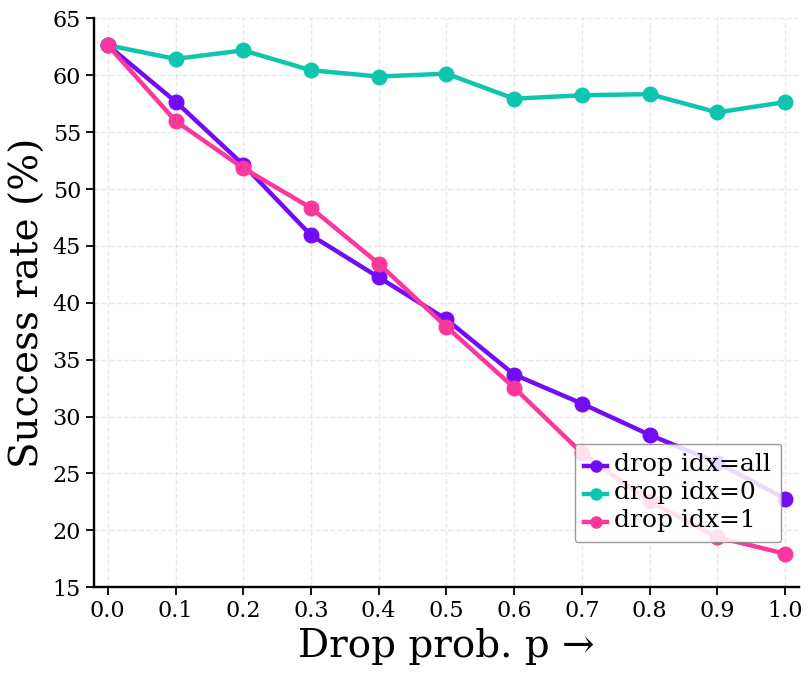
Evaluation of the Variational Regularization (VR) approach utilized Random Masking to assess the importance of individual features within the U-Net decoder backbone. This technique demonstrated a statistically significant performance improvement across multiple benchmarks; specifically, the average success rate on the RoboTwin2.0 environment reached 62.4%. Furthermore, performance on the Adroit and MetaWorld environments improved by 4.1% as measured by the SR5 metric. The benefits of VR also extended to real-world applications, evidenced by a 13.4% increase in success rate on a physical cup-stacking task, confirming the effectiveness of feature filtering for robotic control.
Beyond Current Limits: The Promise of Generative Control
The creation of effective robotic policies often presents a trade-off between expressiveness – the ability to perform a wide range of actions – and efficiency, which dictates how readily a robot can execute those actions. Recent advancements leverage the synergy between diffusion models and information-theoretic principles, specifically the Information Bottleneck [latex]\text{IB}[/latex], to overcome this challenge. The [latex]\text{IB}[/latex] principle encourages the learning of compressed representations that retain only the most relevant information for a given task, effectively distilling complex inputs into essential features. When integrated with diffusion models – probabilistic models adept at generating complex data – this approach allows for the creation of policies that are both highly capable and computationally lean. This results in robotic systems capable of performing intricate maneuvers while minimizing resource consumption and maximizing adaptability, paving the way for more sophisticated and practical applications in real-world scenarios.
Timestep conditioning represents a significant advancement in refining the output of diffusion models for action sequences. By explicitly providing the diffusion model with information about when within a trajectory a particular action should occur, the generated movements become demonstrably smoother and more coherent. This technique moves beyond simply predicting the next action; it encourages the model to consider the temporal context, resulting in action sequences that adhere to a natural progression and exhibit improved fidelity. The integration of timestep information effectively guides the diffusion process, allowing for precise control over the timing and execution of actions, ultimately enhancing the robot’s ability to perform complex tasks with greater accuracy and adaptability.
The convergence of diffusion models and information theory presents a significant leap toward robots exhibiting truly complex and adaptable behaviors. Current robotic systems often struggle with the unpredictable nature of real-world environments, relying on pre-programmed responses or limited learning capabilities. This new framework, however, allows robots to not merely react to stimuli, but to synthesize novel action sequences based on an understanding of underlying environmental information. By efficiently compressing relevant data and generating nuanced responses, these robots can navigate dynamic scenarios, recover from unexpected disturbances, and even learn from their experiences – moving beyond rigid automation towards genuine autonomy. The potential extends to a wide range of applications, from advanced manufacturing and logistics to search and rescue operations and personalized assistance, promising a future where robots seamlessly integrate into and enhance human life.
Continued research aims to broaden the applicability of this control framework beyond current limitations, with emphasis on tackling increasingly intricate tasks demanding greater adaptability. A central focus involves developing methods to enhance the robustness and generalizability of learned policies, ensuring consistent performance across diverse and unpredictable real-world scenarios. This includes investigating techniques to improve sample efficiency – allowing robots to learn effectively from limited data – and exploring novel approaches to transfer learning, enabling knowledge gained from simpler tasks to be readily applied to more challenging ones. Ultimately, the goal is to create robotic systems capable of not just performing pre-programmed actions, but of intelligently responding to unforeseen circumstances and mastering a wider range of skills with minimal human intervention.

The pursuit of robust robot manipulation, as demonstrated in this work, benefits from a principle of reductive design. The paper elegantly applies Variational Regularization to distill essential information within the U-Net architecture, discarding superfluous detail. This aligns with a core tenet of effective problem-solving: removing the unnecessary to reveal the fundamental truth. As David Hilbert famously stated, “One must be able to say at any moment whether one has finished.” This research exemplifies that sentiment; by filtering intermediate features, the system achieves improved performance not through added complexity, but through purposeful simplification. The reduction of noise and redundancy streamlines the process, embodying clarity as a form of courtesy to both the system and its operator.
Beyond the Filter
The application of Variational Regularization to diffusion-based robot manipulation-a deliberate narrowing of the information channel-reveals a persistent truth: much of what passes for ‘learning’ is merely the retention of noise. This work rightly questions the uncritical expansion of neural network capacity, but the challenge extends beyond feature filtering. The U-Net architecture, while effective, remains a largely empirical construct. A more fundamental inquiry must address why these specific features are distilled, and whether a theoretically grounded, minimal sufficient statistic exists for robust manipulation policies.
Current metrics, focused primarily on task completion, are insufficient. A truly parsimonious policy should exhibit not only competence but also interpretability. The filtered features, while improving performance, remain black-boxed. Future work should prioritize the development of regularization techniques that yield features readily linked to physical properties-grasp affordances, object stability, kinematic constraints-transforming the network from a predictor into something approaching an explanation.
Ultimately, the pursuit of efficiency in robot learning is not merely an engineering problem. It is a philosophical one. The goal is not to build increasingly complex systems that simulate intelligence, but to uncover the minimal principles that constitute it. This demands a willingness to discard, to subtract, to embrace the elegance of simplicity, even at the cost of incremental gains.
Original article: https://arxiv.org/pdf/2601.21926.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Division Resurgence Best Weapon Guide: Tier List, Gear Breakdown, and Farming Guide
- Last Furry: Survival redeem codes and how to use them (April 2026)
- GearPaw Defenders redeem codes and how to use them (April 2026)
- Gold Rate Forecast
- eFootball 2026 “Countdown to 1 Billion Downloads” Campaign arrives with new Epics and player packs
- After THAT A Woman of Substance cliffhanger, here’s what will happen in a second season
- Clash of Clans Sound of Clash Event for April 2026: Details, How to Progress, Rewards and more
- Limbus Company 2026 Roadmap Revealed
- Guild of Monster Girls redeem codes and how to use them (April 2026)
- Genshin Impact Version 6.5 Leaks: List of Upcoming banners, Maps, Endgame updates and more
2026-01-31 17:36